
作者:Kunpeng Song, Ligong Han, Bingchen Liu,等
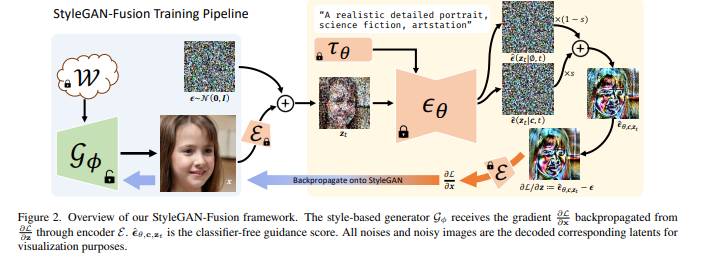
简介:本文研究扩散模型实现域自适应的新方法。能否将文本到图像扩散模型用作训练目标,让 GAN 生成器适应另一个领域?在本文中,作者展示了无分类器指导可以用作判别器,并使生成器能够从大规模文本到图像扩散模型中提取知识。生成器可以有效地转移到文本提示指示的新域中,而无需访问目标域中的真实样本。作者通过大量实验证明了作者方法的有效性和可控性。尽管没有经过训练来最小化 CLIP 损失,但作者的模型在短Prompt提示上获得了同样高的 CLIP 分数和显着降低的 FID,并且在长而复杂的提示上在定性和定量上都优于基线。据作者所知:作者所提出的方法是首次尝试将大规模预训练扩散模型和蒸馏采样结合起来用于文本驱动的图像生成器域自适应,并提供了以前无法实现的质量。此外,作者已将作者的工作扩展到基于 3D 风格的生成器和 DreamBooth 指南。

论文下载:https://arxiv.org/pdf/2212.04473.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢