
作者:Andrés Villa, Juan León Alcázar, Motasem Alfarra,等
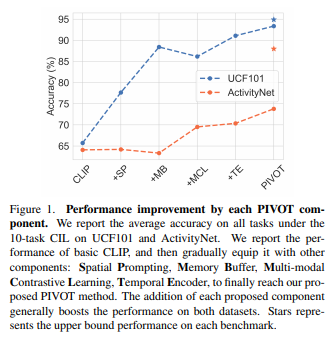
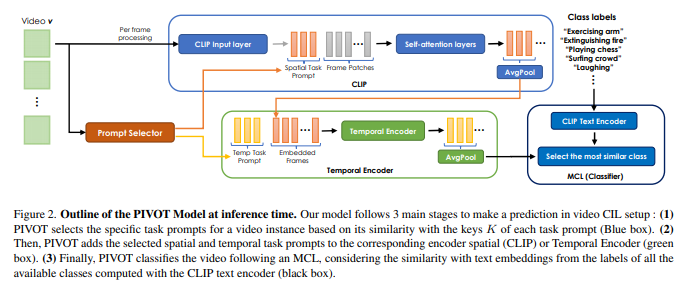
简介:本文研究视频数据的持续学习问题。由于数据可用性、存储配额、隐私法规和昂贵的注释过程,让最新的机器学习pipeline受到限制。这些限制使得维护在不断增长的注释集上训练的大规模模型:变得困难或不可能。持续学习直接解决了这个问题,其最终目标是设计一种方法,使神经网络有效地学习新(未见)类的相关模式,而不会显着改变其在先前学习的模式上的表现。作者提出了 PIVOT:一种利用图像域中预训练模型的广泛知识的新方法,从而减少了可训练参数的数量和相关的遗忘。不同于以往的方法,作者的方法是第一种有效使用Prompt提示机制进行持续学习而无需任何域内预训练的方法。作者的实验表明:PIVOT 在 ActivityNet的Task 20任务上将SOTA方法提高了 27%。
论文下载:https://arxiv.org/pdf/2212.04842.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢