
来自今天的爱可可AI前沿推介
2、[LG] Confidence-Conditioned Value Functions for Offline Reinforcement Learning
J Hong, A Kumar, S Levine
[UC Berkeley]
离线强化学习的置信条件价值函数
要点:
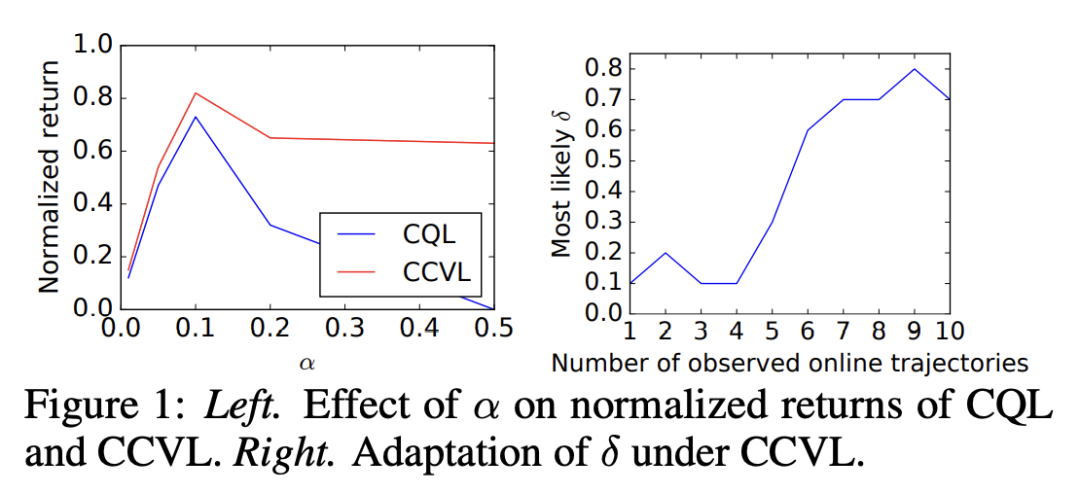
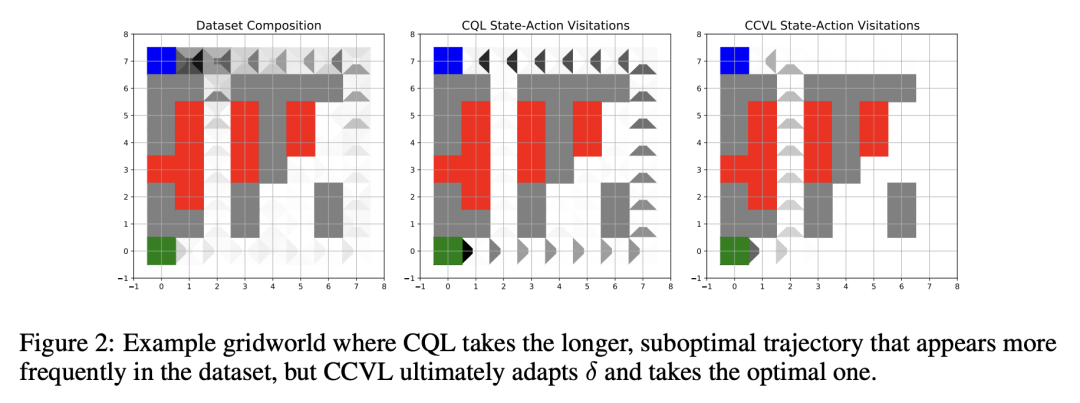
1. 提出基于置信条件的价值学习(CCVL)自适应离线强化学习算法;
2. CCVL是在任意所需置信度下真实Q值的下界值估计;
3.CCVL在离散动作环境(如Atari)中优于现有最先进方法
摘要:
离线强化学习 (RL) 承诺能仅用现有的静态数据集来学习有效策略,而无需任何昂贵的在线交互。为此,离线强化学习方法必须处理数据集和学习策略之间的分布漂移。最常见的方法是学习保守或下界的价值函数,低估了分布外 (OOD) 行为的回报。然而,此类方法存在一个明显的缺点:针对此类价值函数优化的策略只能根据固定的、可能是次优的保守程度行事。然而,如果能在训练时学习不同程度的保守策略并设计一种方法在评估过程中动态选择其中之一,则可以缓解这种情况。为此,本文提出价值函数学习,这些价值函数还以保守程度为条件,将其称为以置信度为条件的价值函数。本文推导出一种新形式的 Bellman 备份,以高概率同时学习任意置信度的 Q 值。通过以置信度为条件,价值函数通过使用迄今为止的观察历史来控制置信度水平,从而在在线评估期间启用自适应策略。这种方法可以通过在置信度上调节现有保守算法的 Q 函数在实践中实现。本文从理论上表明,所学习到的价值函数可以在任意所需的置信度下对真实价值产生保守估计。本文凭经验表明,所提出算法在多个离散控制域上优于现有的保守离线强化学习算法。
Offline reinforcement learning (RL) promises the ability to learn effective policies solely using existing, static datasets, without any costly online interaction. To do so, offline RL methods must handle distributional shift between the dataset and the learned policy. The most common approach is to learn conservative, or lower-bound, value functions, which underestimate the return of out-of-distribution (OOD) actions. However, such methods exhibit one notable drawback: policies optimized on such value functions can only behave according to a fixed, possibly suboptimal, degree of conservatism. However, this can be alleviated if we instead are able to learn policies for varying degrees of conservatism at training time and devise a method to dynamically choose one of them during evaluation. To do so, in this work, we propose learning value functions that additionally condition on the degree of conservatism, which we dub confidence-conditioned value functions. We derive a new form of a Bellman backup that simultaneously learns Q-values for any degree of confidence with high probability. By conditioning on confidence, our value functions enable adaptive strategies during online evaluation by controlling for confidence level using the history of observations thus far. This approach can be implemented in practice by conditioning the Q-function from existing conservative algorithms on the confidence. We theoretically show that our learned value functions produce conservative estimates of the true value at any desired confidence. Finally, we empirically show that our algorithm outperforms existing conservative offline RL algorithms on multiple discrete control domains.
论文链接:https://arxiv.org/abs/2212.04607

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢