
来自今天的爱可可AI前沿推介
[LG] Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints
A Komatsuzaki, J Puigcerver, J Lee-Thorp...
[Google Research & Georgia Institute of Technology]
Sparse Upcycling:稠密检查点专家混合训练
要点:
1. 稀疏激活模型正成为相对于稠密模型的有吸引力的替代方案,具有计算效率优势;
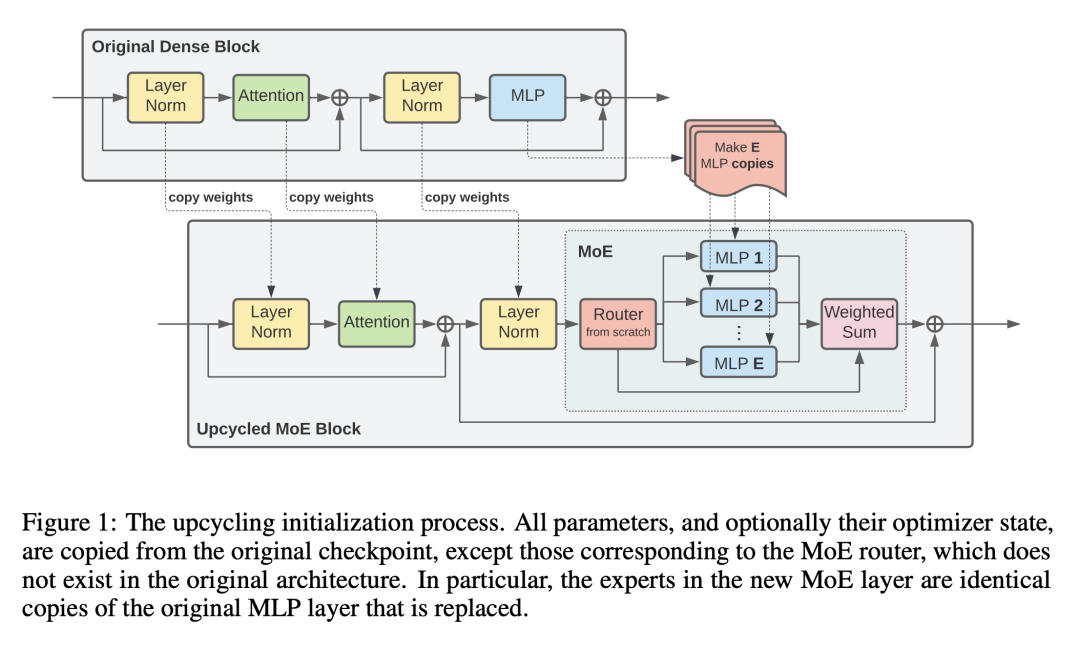
2. Sparse Upcycling通过从稠密检查点初始化稀疏激活混合专家模型,来重用沉没(过往)训练成本;
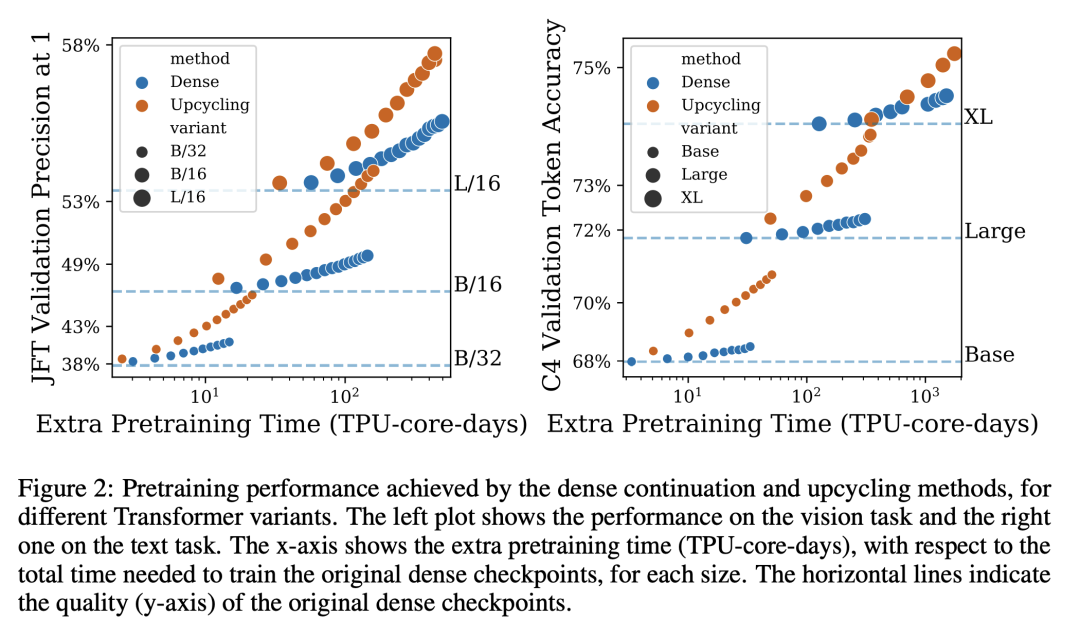
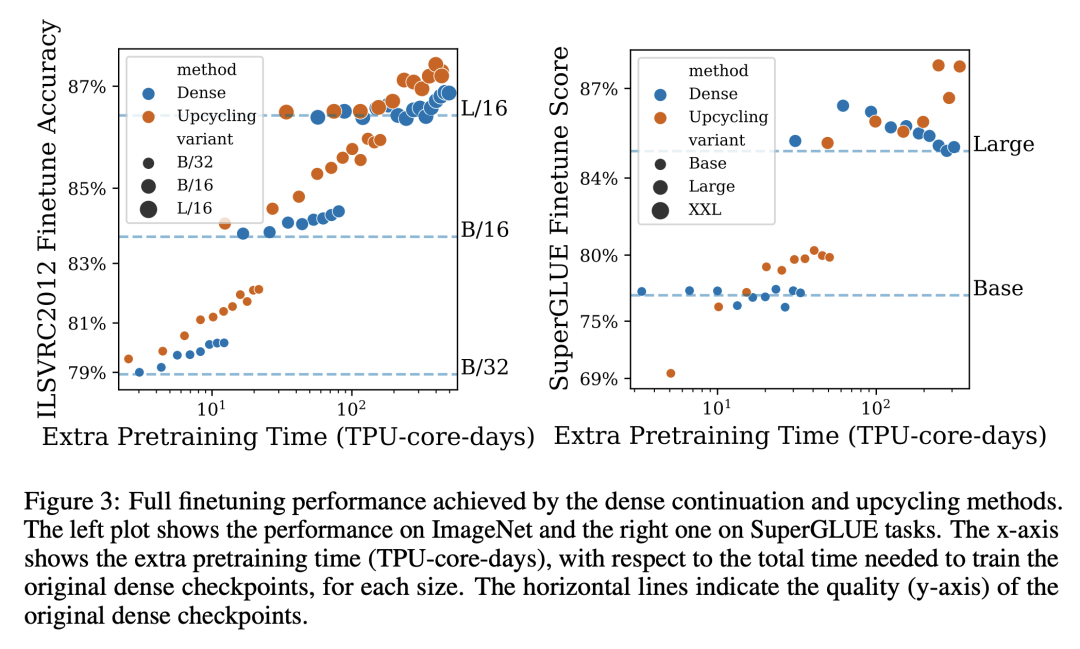
3. 对视觉和语言模型而言,Upcycling总是有效的,只需要比训练稠密模型所需的成本更少的预算就能获得显著的性能提升。
摘要:
训练大型深度神经网络达到收敛,可能是非常昂贵的。因此,通常只有一小部分流行的稠密模型在不同的环境和任务中被重复使用。越来越多的稀疏激活模型,寻求将模型大小与计算成本脱钩,正在成为稠密模型的一个有吸引力的替代品。虽然在质量和计算成本方面更有效,但稀疏模型仍然对数据要求很高,而且在大规模系统中从头开始训练成本很高。本文提出Sparse Upcycling——通过从稠密检查点初始化稀疏激活专家混合模型来重新使用沉没(过往)训练成本的简单方法。本文表明,在SuperGLUE和ImageNet上,使用Sparse Upcycling的T5 Base、Large和XL语言模型以及Vision Transformer Base和Large模型的表现明显优于稠密模型,只使用了最初密集预训练沉没成本的50%。升级后的模型也优于从头开始训练的初始稠密型预训练计算预算为100%的稀疏模型。
Training large, deep neural networks to convergence can be prohibitively expensive. As a result, often only a small selection of popular, dense models are reused across different contexts and tasks. Increasingly, sparsely activated models, which seek to decouple model size from computation costs, are becoming an attractive alternative to dense models. Although more efficient in terms of quality and computation cost, sparse models remain data-hungry and costly to train from scratch in the large scale regime. In this work, we propose sparse upcycling -- a simple way to reuse sunk training costs by initializing a sparsely activated Mixture-of-Experts model from a dense checkpoint. We show that sparsely upcycled T5 Base, Large, and XL language models and Vision Transformer Base and Large models, respectively, significantly outperform their dense counterparts on SuperGLUE and ImageNet, using only ~50% of the initial dense pretraining sunk cost. The upcycled models also outperform sparse models trained from scratch on 100% of the initial dense pretraining computation budget.
论文链接:https://arxiv.org/abs/2212.05055

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢