
作者:Yi Wang, Kunchang Li, Yizhuo Li, 等
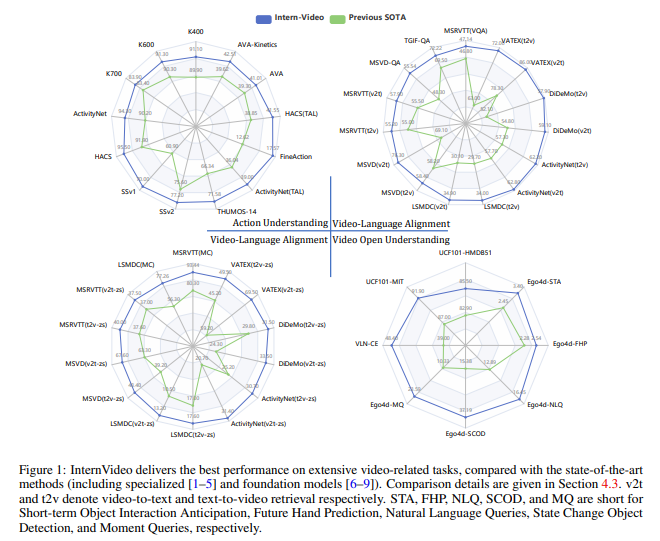
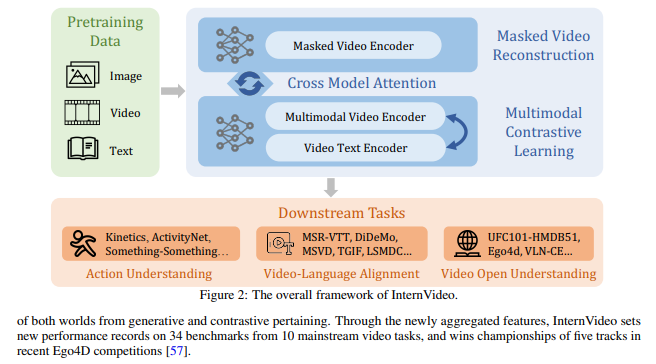
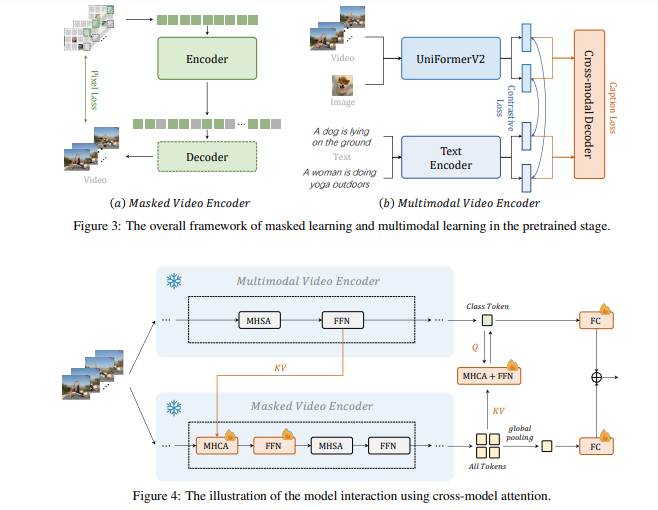
简介:本文研究通用且训练效率高的视频基础模型。基础模型最近在计算机视觉的各种下游任务中显示出出色的性能。然而,大多数现有的视觉基础模型只关注图像级的预训练和适应,这对于动态和复杂的视频级理解任务是有限的。为了填补这一空白,作者提出了通用视频基础模型 InternVideo——利用了生成式和判别式自监督视频学习。具体来说,InternVideo 有效地探索了掩蔽视频建模和视频语言对比学习作为预训练目标,并以可学习的方式选择性地协调这两个互补框架的视频表示,以促进各种视频应用。InternVideo 在来自广泛任务的 39 个视频数据集上实现了SOTA性能,包括视频动作识别/检测、视频语言对齐和开放世界视频应用程序。特别是,作者的方法可以在具有挑战性的 Kinetics-400 和 Something-Something V2 基准测试中分别获得 91.1% 和 77.2% 的 top-1 准确率。上述结果均有效地展示了作者的 InternVideo 对视频理解的普遍性。
论文下载:https://arxiv.org/pdf/2212.03191.pdf
源码下载:https://github.com/OpenGVLab/InternVideo
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢