
【标题】Towards Safe Reinforcement Learning via Constraining Conditional Value-at-Risk
【作者团队】Chengyang Ying, Xinning Zhou, Hang Su, Dong Yan, Ning Chen, Jun Zhu
【发表日期】2022.9.17
【论文链接】https://arxiv.org/pdf/2206.04436v2.pdf
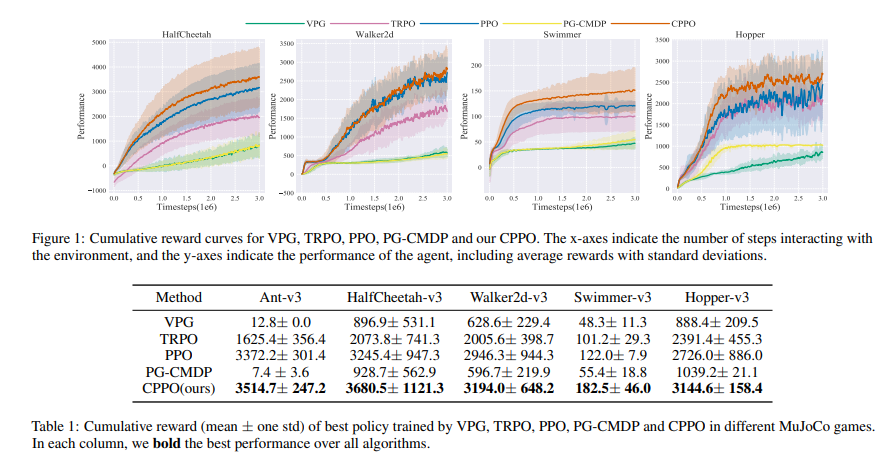
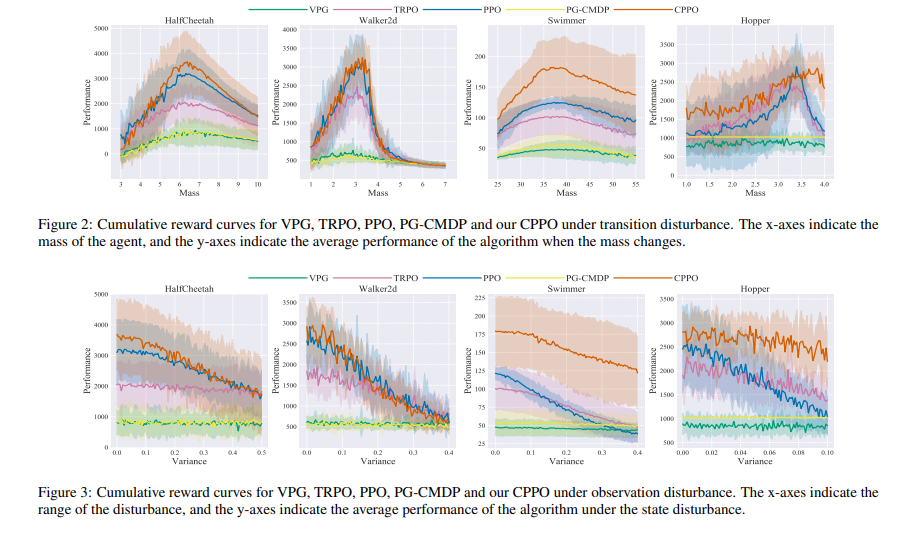
【推荐理由】尽管深度强化学习(DRL)已经取得了实质性的成功,但由于过渡和观察的内在不确定性,它可能会遇到灾难性的失败。大多数现有的安全强化学习方法只能处理过渡扰动或观察扰动,因为这两种扰动影响主体的不同部分;此外,流行的最坏情况回报可能导致政策过于悲观。为此,本文首先从理论上证明了在过渡扰动和观测扰动下的性能退化取决于一个新的值函数范围(VFR)度量,该度量对应于最佳状态和最坏状态之间的值函数差距。在分析的基础上,采用条件风险值(CVaR)作为风险评估,并提出了新的CVaR近端策略优化(CPPO)强化学习算法,通过将CVaR保持在给定阈值之下,将风险敏感的约束优化问题形式化。实验结果表明,CPPO在MuJoCo中的一系列连续控制任务上实现了更高的累积回报,并且对观测和过渡扰动都更鲁棒。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢