
【标题】Towards Applicable Reinforcement Learning: Improving the Generalization and Sample Efficiency with Policy Ensemble
【作者团队】Zhengyu Yang, Kan Ren, Xufang Luo, Minghuan Liu, Weiqing Liu, Jiang Bian, Weinan Zhang, Dongsheng Li
【发表日期】2022.5.19
【论文链接】https://arxiv.org/pdf/2205.09284.pdf
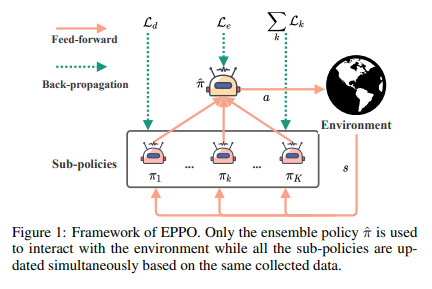
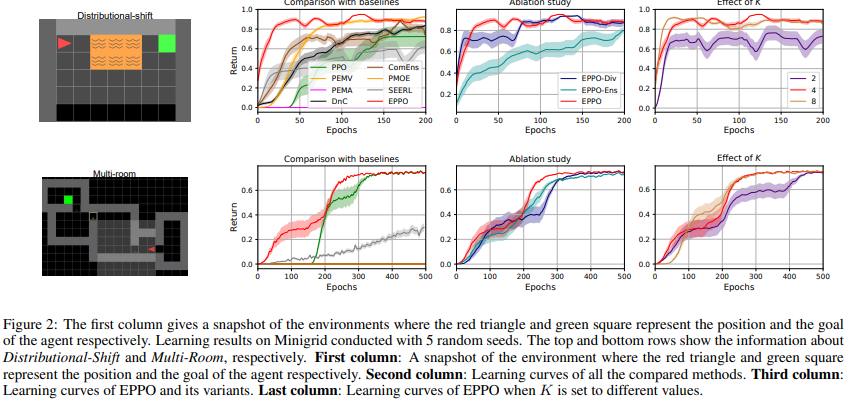
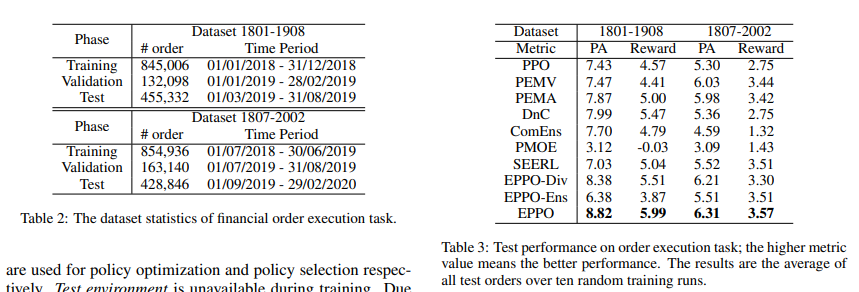
【推荐理由】强化学习(RL)算法在金融交易和物流系统等现实世界应用中取得成功具有挑战性,因为存在噪声观测以及训练和评估之间的环境转换。因此,它需要高采样效率和通用性来解决实际任务。然而,直接应用典型的RL算法可能会导致此类场景中的性能不佳。考虑到集成方法在监督学习(SL)中的准确性和通用性方面的巨大性能,本文设计了鲁棒且适用的方法,称为集成近端策略优化(EPPO),该方法以端到端的方式学习集成策略。值得注意的是,EPPO将每项政策和政策组合有机地结合起来,并同时优化两者。此外,EPPO在政策空间上采用了多样性增强正则化,这有助于推广到未知状态并促进探索。我们从理论上证明了EPPO提高了探索效率,并且通过对各种任务的综合实验评估,研究证明了与普通策略优化算法和其他集成方法相比,EPPO实现了更高的效率,并且对真实世界的应用具有鲁棒性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢