
来自今天的爱可可AI前沿推介
[LG] You Can Have Better Graph Neural Networks by Not Training Weights at All: Finding Untrained GNNs Tickets
T Huang, T Chen, M Fang, V Menkovski…
[Eindhoven University of Technology & University of Texas at Austin]
与完全训练网络具有可比性能的未训练GNN子网络的发现
要点:
1.进行发现匹配未训练GNN的探索。
2.发现稀疏性是在发现与完全训练网络具有可比性能的未训练子网络的强大工具。
3.分布外检测和输入扰动鲁棒性性能均有所改善。
摘要:
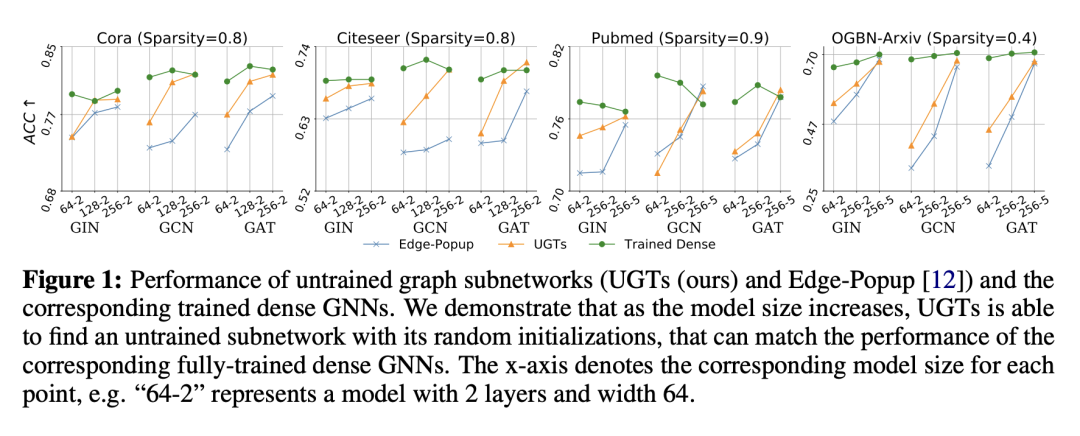
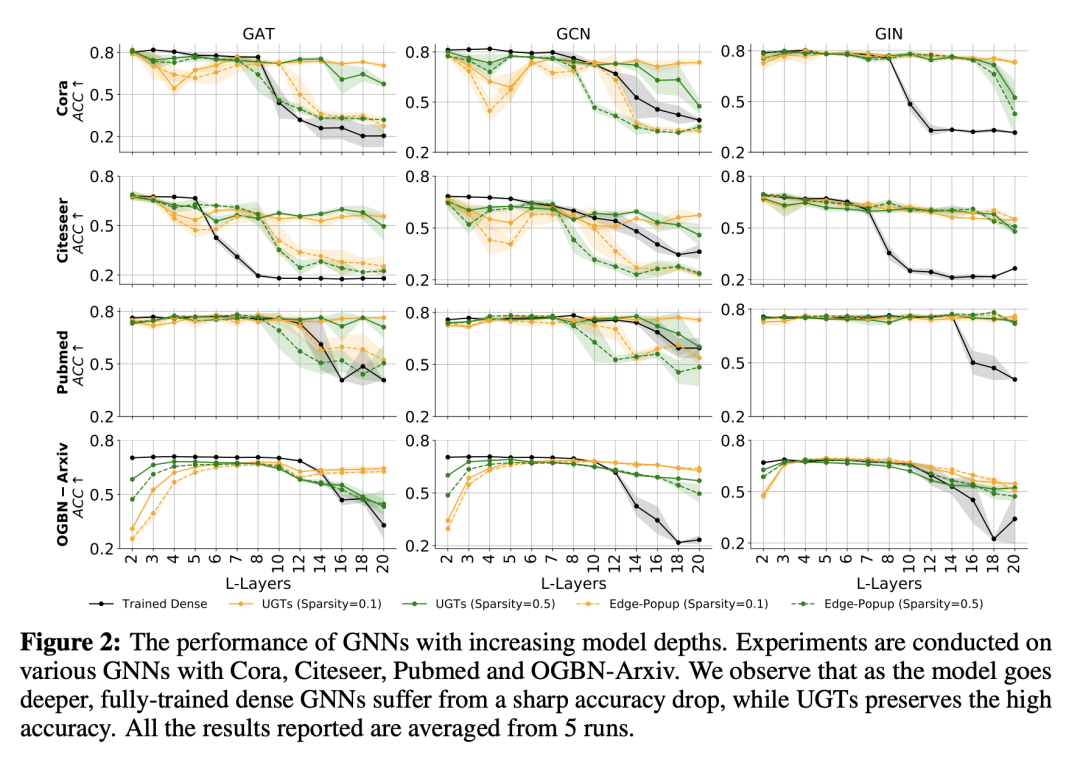
最近的工作令人印象深刻地证明,在随机初始化的卷积神经网络(CNN)中存在一个子网络,可以在初始化时与完全训练的稠密网络的性能相匹配,而无需对网络权重进行任何优化(即未训练的网络)。然而,图神经网络(GNN)中此类未经训练的子网络的存在仍然是个谜。本文进行了发现匹配未训练 GNN 的首次探索。以稀疏性为核心工具,可以在初始化时找到未经训练的稀疏子网络,可与完全训练的稠密 GNN 的性能相匹配。除了这个已经令人鼓舞的可比性能发现之外,本文还表明,发现的未经训练的子网络可以大大减轻 GNN 过度平滑问题,因此成为一个强大的工具,可以在没有额外技巧的情况下实现更深层的GNN。本文还观察到这种稀疏的未经训练的子网络在分布外检测和输入扰动的鲁棒性方面具有吸引人的性能。在包括开放图基准 (OGB) 在内的各种流行数据集上评估了其在广泛使用的 GNN 架构中的方法。
Recent works have impressively demonstrated that there exists a subnetwork in randomly initialized convolutional neural networks (CNNs) that can match the performance of the fully trained dense networks at initialization, without any optimization of the weights of the network (i.e., untrained networks). However, the presence of such untrained subnetworks in graph neural networks (GNNs) still remains mysterious. In this paper we carry out the first-of-its-kind exploration of discovering matching untrained GNNs. With sparsity as the core tool, we can find untrained sparse subnetworks at the initialization, that can match the performance of fully trained dense GNNs. Besides this already encouraging finding of comparable performance, we show that the found untrained subnetworks can substantially mitigate the GNN over-smoothing problem, hence becoming a powerful tool to enable deeper GNNs without bells and whistles. We also observe that such sparse untrained subnetworks have appealing performance in out-of-distribution detection and robustness of input perturbations. We evaluate our method across widely-used GNN architectures on various popular datasets including the Open Graph Benchmark (OGB).
论文地址:https://openreview.net/forum?id=dF6aEW3_62O


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢