目前,基于Transformer的预训练语言模型在各种下游任务上取得了极好的结果,甚至在部分数据上达到了人类的水平。然而,长文本摘要依旧是一个具有挑战性的问题:文本长度过长,通常超过了预训练语言模型的长度限制;内容广度大,信息压缩比大;文本数据通常是特定领域文章。本文主要介绍了解决长文档摘要问题的几种机制。
近年来,Transformer以及基于Transformer的预训练语言模型在自然语言理解和生成领域取得了巨大进展。在短文本摘要领域,无论是抽取式摘要(BERT,RoBERTa),还是生成式摘要(BART,T5),文本摘要模型都取得了卓越的表现。然而,长文本摘要长度长,内容广,压缩程度高,并且通常是特殊领域文章(如arxiv论文),一直以来是一个难以处理的问题。[1]
目前,解决长文本摘要主要有基于图/GNN的模型,基于RNN的模型和基于Transformer的模型。图模型首先将一篇文章映射为一个图,并使用无监督的中心性打分抽取top-K句子或者使用GNN进行训练。RNN方法对整个序列文本进行建模,并抽取或者生成摘要。目前,Transformer和PLM逐步取代RNN,成为NLP领域的焦点。但是,受到位置编码长度影响,预训练语言模型通常对输入文本的最大长度存在一定限制,例如,BERT仅仅可以处理512位字符。同时,Transformer的平方级别复杂度进一步限制了输入文本的长度,而对文本进行截断造成了文本信息的丢失。因此,直接应用预训练语言模型是行不通的,需要添加额外机制。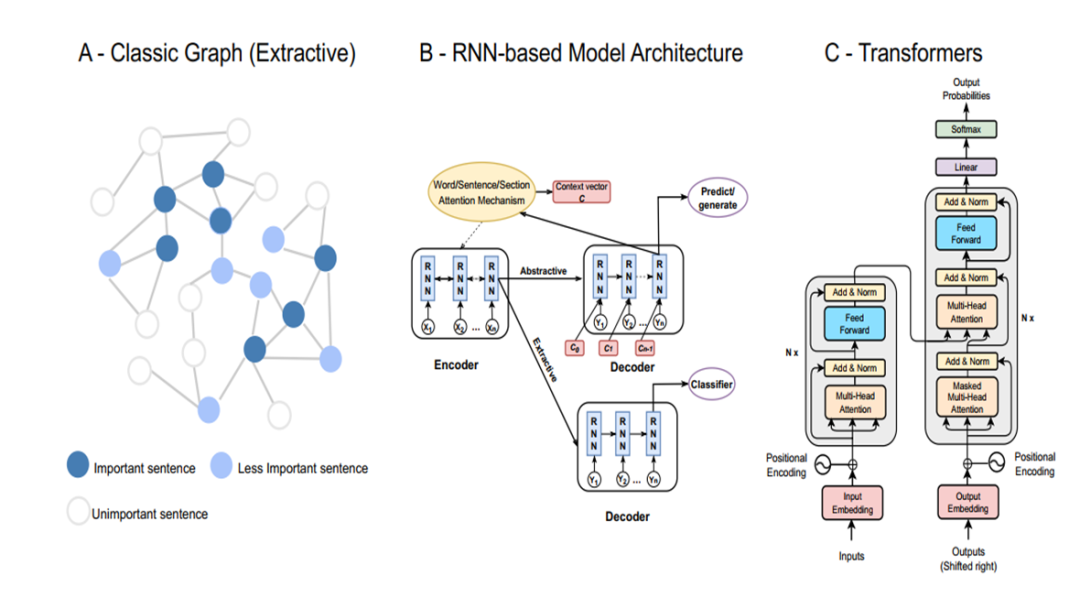
本文关注于应用于三种模型中的不同机制,更好的对长文本进行建模和摘要。接下来,本文将围绕高效注意力机制,信号引导,分治,内容选择等机制,以及与GNN,Transformer等模型的结合进行介绍。值得注意的是,这些机制之间并不是独立存在的,不同的机制之间可以相互结合,在降低内存需求的同时提高模型性能。
阅读详情
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢