
本文是支付宝体验科技沙龙第 3 期-走进蚂蚁端智能技术回顾系列文章,作者是蚂蚁集团算法工程师世豪,介绍了 xNN 在端侧 AI 优化问题抽象及解决思路,以及面对“算力碎片化”为特点的 AI 芯片生态,思考新一代端智能建模框架所需的核心要素,实现对终端设备算力的精细化挖掘。
xNN 框架 1.0:轻量化建模
轻量化建模和主流的模型优化的思路相对一致。我们基于刚才所定义的四个层级的优化主体逐层建设相应的能力,整体上形成一个自上而下的逐层优化。在这个过程中,我们沉淀了四个方面的技术能力:结构搜索,模型压缩,模型转换,计算引擎。通四个维度逐层向下优化,我们希望能够为我们内部不同的业务算法需求提供层次化的解决方案。接下来我会对这四个模块整体做一个简单的介绍。
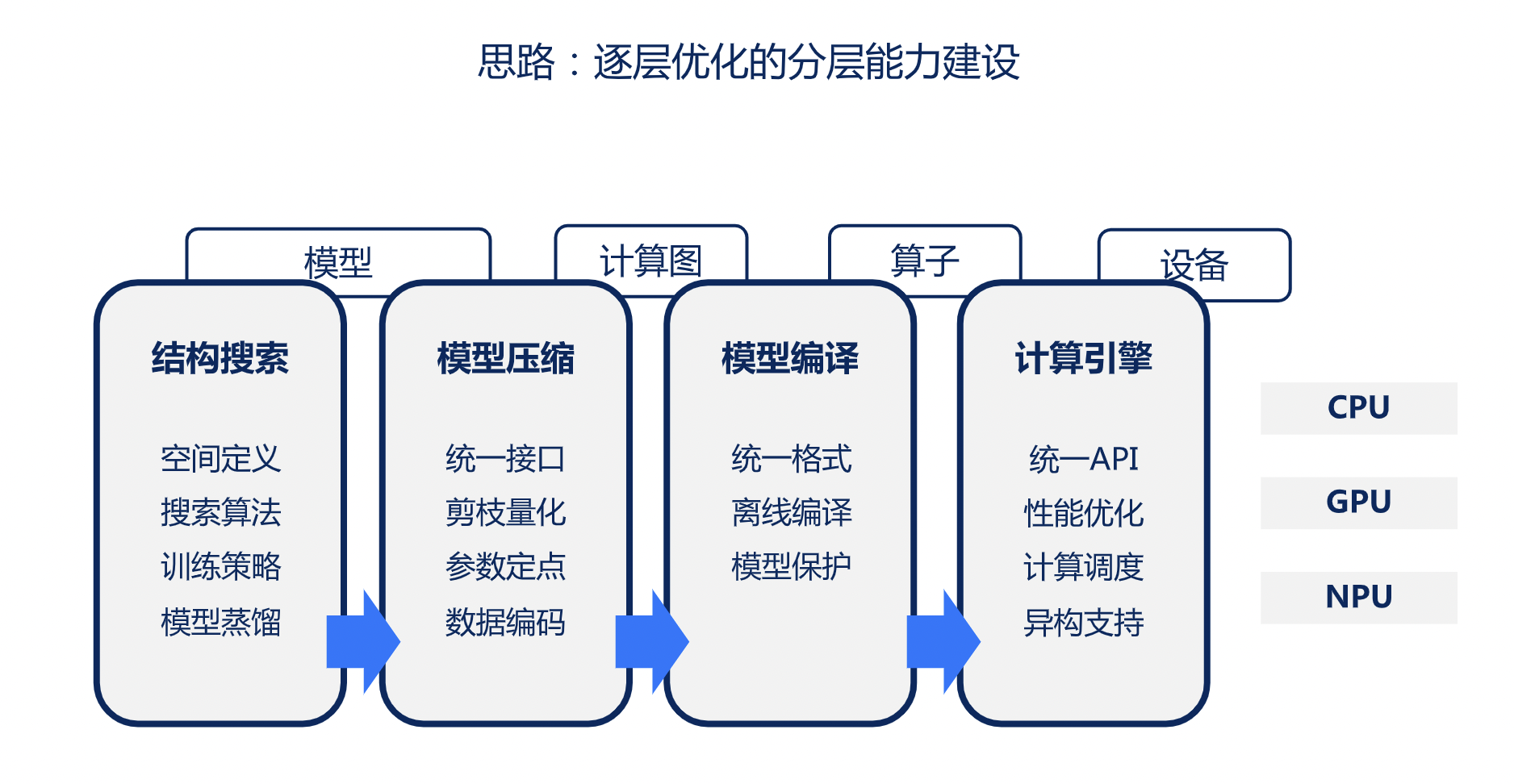
首先是模型压缩和结构搜索,这两个技术模块是与端模型算法研发过程紧密相关,且需要与算法同学深度协同的一些技术能力。
模型压缩:
早在 xNN 计算引擎首次上线时,我们便配套布局建设了模型压缩的核心技术。它包括了模型的剪枝,参数的量化,以及数据编码。
-
剪枝(Pruning):模型剪枝可以简单的分为三个维度。(1)通道剪枝(Channel Pruning)虽然能够有效的降低模型的尺寸以及计算的性能,但在实际的使用过程中调整通道间的压缩比例往往需要大量调参。(2)模版化剪枝(Pattern Pruning)及突触剪枝(Synapse Pruning):这种方式通可以在引擎侧设计特殊的稀疏计算 kernel 来实现加速,但往往依赖较高的压比率才能获得较好的加速效果。因此想要把这个能力充分的利用起来,往往依赖较大的优化精力投入。整体来看,我们认为剪枝相关的技术在逐步的被结构搜索(NAS)的方式所去替代,并逐步将更多的技术资源迁移至 NAS 方向的建设中。
-
量化(Quantization):量化是广泛应用于我们实际的业务场景中的一项模型压缩技术。它一方面能够帮助我们压缩模型尺寸以减小模型下发的流量消耗和设备端存储消耗,比如说我们可以用量化的方式对搜索推荐模型中的 Embedding 的词表做模型的压缩;另一方面,我们也可以用量化的方式去做加速。因为很多硬件厂商所提供的指令集都支持了 INT8 量化加速指令。所以量化是一个投入产出性价比较高的模型压缩手段。
-
编码(Coding):利用数据编码方式来进一步的减小模型的尺寸,是在 xNN 引擎上线第一个模型时便引入的核心能力。我们可以简单的通过稀疏的表达存储方式来去做一个信息的存储;与此同时,xNN 设计了有效的编码算法,通过对AI的数据分布来实现更高的压缩比率来逼近信息熵的极限。
结构搜索:
网络结构搜索(Network Architecture Search, NAS)正在 xNN 体系中逐步取代很多单点模型压缩能力。因为上述的压缩算法往往会依赖于算法研发同学优化经验和反复尝试迭代才能获得较优的效果,那么通过自动化的方式来去替代人工的优化和搜索,对研发的效能帮助很大。
在这个背景下,我们也持续跟进并沉淀了非常多的能力。比如说我们通过 Black-box Optimization 实现自动化的超参搜索,比如通过 Differiential NAS 这种可微的方式,或者是通过 one-shot NAS 的方式来去做模型压缩。这些方案都广泛应用在我们的业务场景中,并取得了很不错的实践效果,绝大多数场景都进一步超过了以往经过专家经验深度调优的模型指标。
模型转换:
这个阶段主要的工作是把我们主流的深度学习训练框架所产出的模型转换为实际部署的 xNN 模型格式。整个的转换涉及的各种图优化的过程对相关领域同学都比较熟悉,我们不做过多的介绍。
在此基础之上,围绕着蚂蚁业务中实际需求,也逐步建设了非常多的增量功能。例如模型串联的需求,大家做真正的做端智能的业务落地,会发现往往一个业务所需要的端智能的算法通常并不是由一个单一的模型就能够解决的,往往是由多个 AI 模型通过一定的算法逻辑串联而成。因此有没有办法把多个AI模型有效的串联到一个模型之中?如果可以,那我们能够极大的减少算法研发同学和实际的工程部署同学之间的对接成本,以及整个开发的生命周期。
因此我们在编译阶段提供了相关的工具:模型串联工具帮助把一些包括循环分支;动态化工具能够实现引擎功能、资源调度逻辑的动态发布;另外包括模型保护工具、端侧训练工具等等相关的一些能力,都伴随着业务的发展逐步建设和完善起来。
计算引擎:
最后一块是计算引擎,这个也是我们通常所称的端侧 AI 计算相关的一个核心模块。计算引擎在我们 APP 的开发者的视角上来讲,我们更多的是聚焦于如何寻找高效的 kernel 实现,在访存密集型和计算密集型的计算任务上去做合理的优化和调整。在整个建设过程中,我们针对不同的部署平台,会有不同的差异化的一个优化策略。比如说在 CPU 和 GPU 上,我们能够通过自己去实现定制化的高效 kernel 实现,来达到更优的效果。因此我们会在这些平台上去利用我们的专家经验,针对核心算子做深度的优化,并会逐步的以更自动化的算子编译的方式去做演进。
面对现在逐渐发展起来的 NPU 等 AI 芯片,我们 APP 开发者往往不太能够具备非常深入底层的优化方式。因此这一块我们会和各个芯片及硬件厂商会做较多协同,以期能够利用最大化的利用到端侧 AI 芯片的硬件加速算力。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢