
“Pre-training + Fine-tune”正在重置AI领域的研究范式,预训练大模型已成为备受瞩目的研究方向,它首先兴起于自然语言处理,也彻底变革了这方面的研究和应用。预训练新范式先将非常普遍的“通识”知识抽取出来,培养一个基础模型,然后以此进行微调,得到处理具体问题的专业模型,其性能和效率大多已胜过传统的任务模型,使得AI应用门槛大幅降低。
达摩院是国内最早投入预训练大模型的研究团队之一。2021年1月,达摩院推出多模态大模型M6,模型参数从百亿起步,后增至10万亿,成为全球最大的预训练模型之一。同时,针对自然语言处理,达摩院推出了2万亿参数的语言大模型PLUG,中文预训练也逐渐朝“大模型”演进。在上述研究的基础上,达摩院更是推出了“阿里通义大模型体系”,以多模态预训练模型为底座,涵盖文本、视觉和多模态任务。
本文将着重介绍下阿里通义大模型体系中的AliceMind,它以通用预训练模型StructBERT为核心,包括一系列预训练语言模型,取得了多个业界领先的技术成果,包括2018年1月在英文机器阅读理解榜单SQuAD首次超越人类基准,2021年8月在视觉问答榜单VQA Leaderboard上首次超越人类基准,2022年11月在中文语言理解榜单CLUE首次超越人类基准。
基于阿里通义AliceMind,我们在各种自然语言的下游任务,包括理解生成、文本分类、对话问答、文档分析和机器翻译等方面研发出了一整套的自然语言处理技术和框架,目前正在AI模型社区魔搭ModelScope上持续进行开源开放,希望能推动NLP领域的研究,帮助开发者轻松构建自己的语言模型和AI应用。
2.1 信息增强的词法分析任务
分词、词性标注、命名实体识别等词法分析任务是NLP中基础、且应用最广泛的任务模块,应用场景包括搜索query分析、商品信息抽取、对话NLU、文档结构化等。在预训练的范式之下,如何融入无监督、半监督、检索等多类型知识是词法分析任务在学术界和工业界的共同热点。
✪ 分词
模型名称:BAStructBERT模型链接:https://modelscope.cn/search?search=BAStructBERT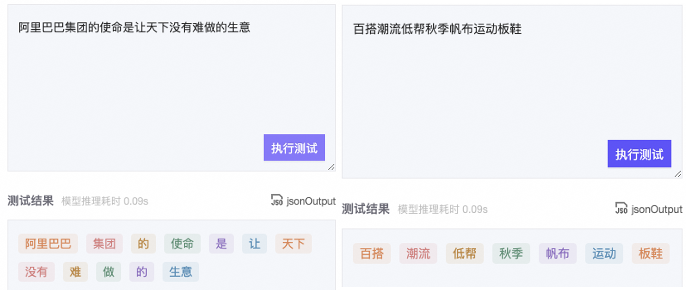 中文分词算法已经发展了30多年,从最初的基于词典的匹配方法,到后来的基于字标注的统计学习方法,再到深度学习方法,而大规模预训练语言模型的出现大幅度提升了中文分词的效果。
中文分词算法已经发展了30多年,从最初的基于词典的匹配方法,到后来的基于字标注的统计学习方法,再到深度学习方法,而大规模预训练语言模型的出现大幅度提升了中文分词的效果。
魔搭开源的分词模型在预训练阶段将边界熵、互信息等无监督统计信息融入到预训练任务中,从而提升预训练语言模型对中文词汇边界的学习能力。该模型在分词、词性标注等中文序列标注任务取得了SOTA结果, 具体论文发表于EMNLP2022。
为了便利开发者使用,我们在魔搭上的分词、词性标注模型提供Base和Lite两种规模的模型,还专门提供了基于电商数据训练的电商行业分词模型。未来,我们会持续丰富行业分词、词性标注模型, 同时也会提供推理效率更高的基于浅层神经网络(LSTM、GCNN)的蒸馏模型。
✪ 命名实体识别(NER)
模型名称:RaNER模型链接:https://modelscope.cn/search?search=RaNER
信息抽取能帮助我们从海量文本自动提取挖掘关键信息,是数字化的重要支撑技术,其中,命名实体识别(NER)是信息抽取中的重要子任务。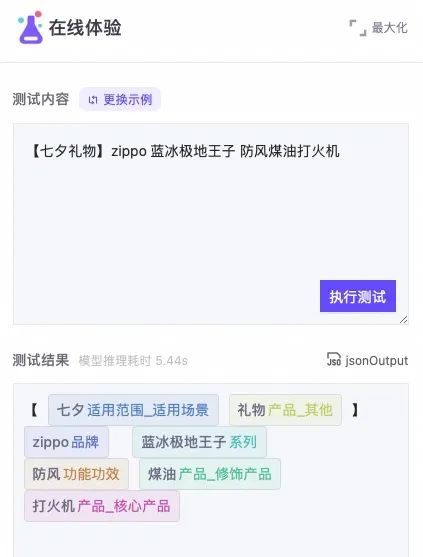 比如上面的电商文本,模型需要合理地识别核心产品、品牌、场景、功能等关键信息。而要实现高质量的识别结果,必须融入知识。经过两年的技术探索,提出了检索增强技术体系RaNER,在自然语言处理国际学术会议ACL/EMNLP/NAACL/COLING发表了五篇论文,在SemEval 2022国际多语言竞赛获得十项第一,获得唯一的最佳系统论文奖,同时也在NLPCC语音实体理解竞赛获得榜首成绩。
比如上面的电商文本,模型需要合理地识别核心产品、品牌、场景、功能等关键信息。而要实现高质量的识别结果,必须融入知识。经过两年的技术探索,提出了检索增强技术体系RaNER,在自然语言处理国际学术会议ACL/EMNLP/NAACL/COLING发表了五篇论文,在SemEval 2022国际多语言竞赛获得十项第一,获得唯一的最佳系统论文奖,同时也在NLPCC语音实体理解竞赛获得榜首成绩。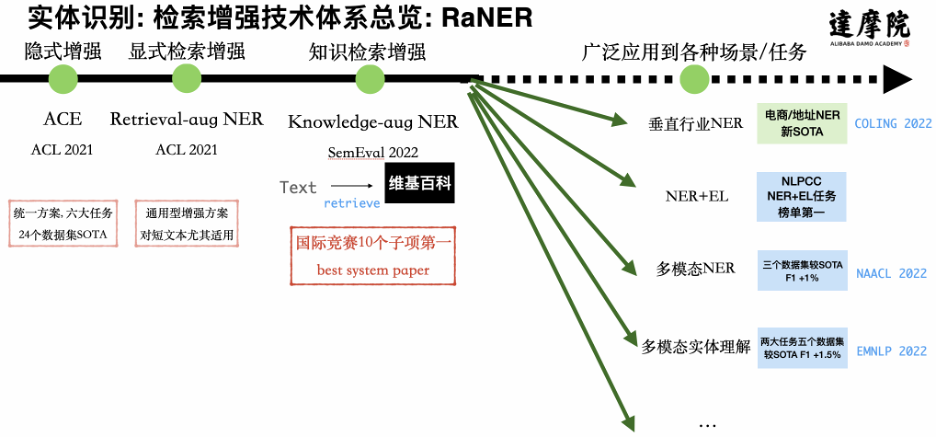 在魔搭社区,我们不仅提供通用的实体识别模型,还有40多个具体的模型,横跨15个不同的行业,多个中/英/小语种,及包括base/large/lstm模型规格,方便用户在不同行业、不同语种、同场景进行使用。
在魔搭社区,我们不仅提供通用的实体识别模型,还有40多个具体的模型,横跨15个不同的行业,多个中/英/小语种,及包括base/large/lstm模型规格,方便用户在不同行业、不同语种、同场景进行使用。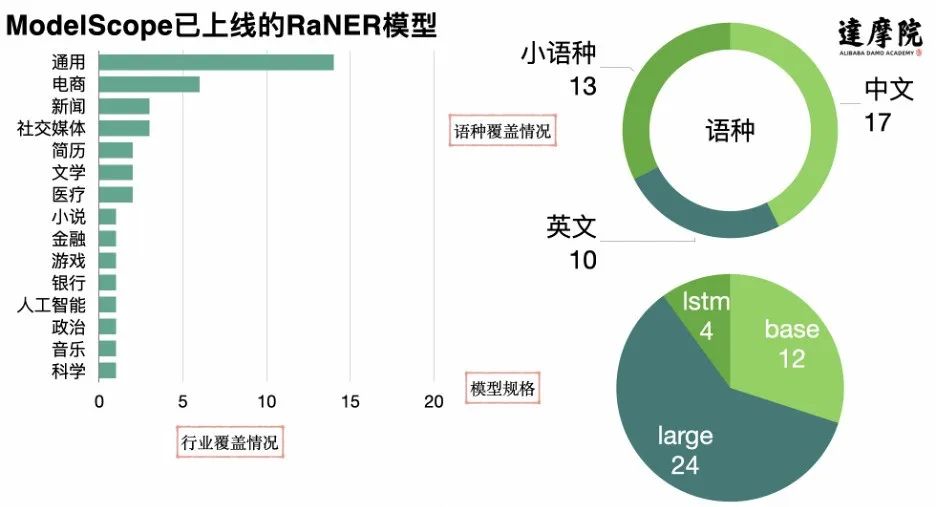
2.2 文本分类任务
作为业界最权威的中文自然语言理解榜单之一,CLUE从文本分类、阅读理解、自然语言推理等9项任务中全面考核AI模型的语言理解能力。过去三年,该榜单吸引了众多国内顶尖NLP团队的参与,尽管榜首位置多次易主,但参评AI模型一直未能超越人类成绩。
2022年11月22日,阿里通义AliceMind在4项任务中的表现超过人类水平,同时实现了总榜平均分的首次超越,意味着AI模型的中文语言理解水平达到了新的高度。
✪ 情感分类模型
模型名称:StructBERT情感分类模型链接:https://modelscope.cn/models?name=情感分类
情感分类需要模型对带有感情色彩的主观性文本进行分析、推理,即分析文本所表达的态度,是倾向于正面还是反面。通常来说,情感分类的输入是一段句子或一段话,模型需要返回该段话正向/负向的情感极性,在用户评价,观点抽取,意图识别中往往起到重要作用。
我们在魔搭上开源了5个情感分类模型,包括了中英文通用版本和中文电商领域版本。以“启动的时候很大声音,然后就会听到1.2秒的卡察的声音,类似齿轮摩擦的声音”为例,模型会返回情感的正负面以及其对应的概率。如下图所示: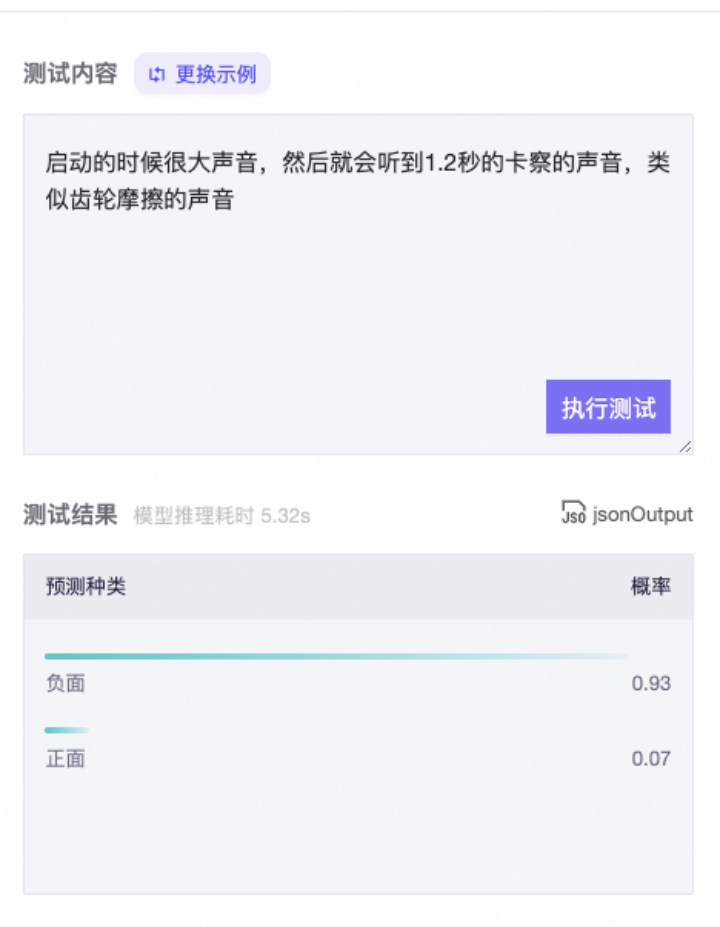 该模型使用StructBERT作为预训练底座,收集了各领域的开源情感分类数据集(共10W+)进行Fine-tune,并结合R-drop、label-smoothing等策略避免模型过拟合,因此能实现较好的效果。
该模型使用StructBERT作为预训练底座,收集了各领域的开源情感分类数据集(共10W+)进行Fine-tune,并结合R-drop、label-smoothing等策略避免模型过拟合,因此能实现较好的效果。
✪ 零样本分类
模型名称:StructBERT零样本分类模型链接:https://www.modelscope.cn/models/damo/nlp_structbert_zero-shot-classification_chinese-base/summary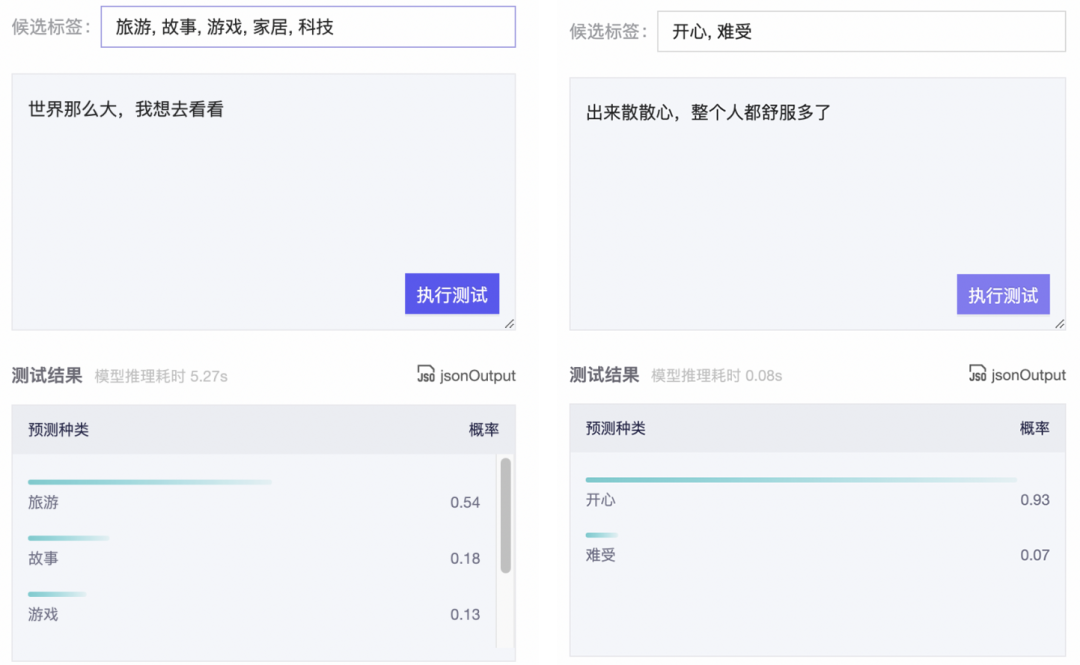 从上图两个实例,我们可以发现StructBERT零样本分类模型支持候选标签任意定义,从而具备了解决各种任务的能力,比如例1中的主题分类任务、例2中的情感分析任务。因此,我们能在无标注数据或标注数据很少的情况进行快速启动模型,或者为待标注数据进行预分类从而提高标注效率。
从上图两个实例,我们可以发现StructBERT零样本分类模型支持候选标签任意定义,从而具备了解决各种任务的能力,比如例1中的主题分类任务、例2中的情感分析任务。因此,我们能在无标注数据或标注数据很少的情况进行快速启动模型,或者为待标注数据进行预分类从而提高标注效率。
技术上,StructBERT零样本分类模型将待分类的文本和每个标签依次拼接进行自然语言推理任务,之后整合每个标签得到的结果,从而形成文本所属的标签。该模型对文本和标签的信息都进行充分的编码和交互,并利用预训练学习到的知识,可在不使用下游数据进行训练的情况下,按照指定的标签对文本进行分类。 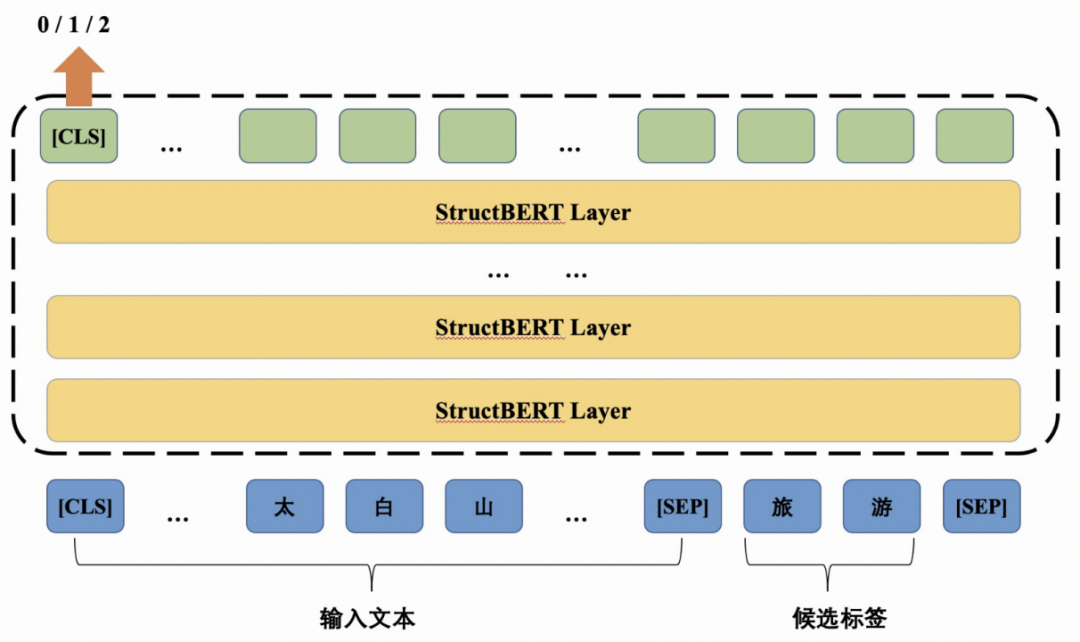
2.3 文本语义表示
✪ 语义匹配
模型名称:ROM模型链接:https://modelscope.cn/models?name=CoROM&page=1
文本语义匹配模型在文本相似度、文本聚类、文本检索排序等下游任务中发挥着重要作用,基于预训练模型构建的召回、排序模型对比传统的统计模型优势明显。下图展示了搜索场景中判断查询query和候选文档的相似度的典型样例: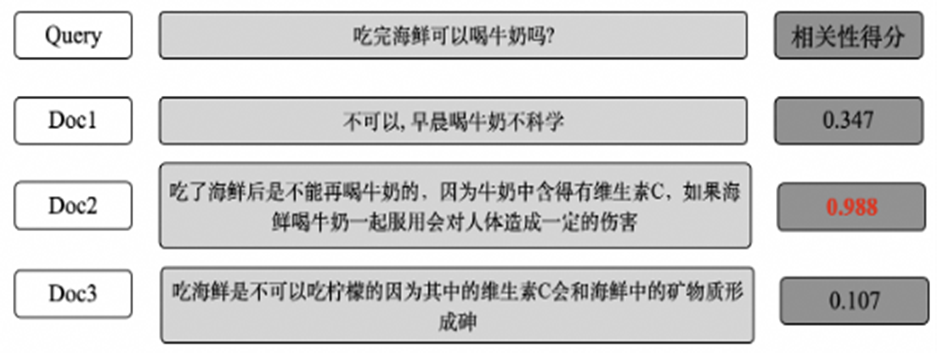 文本语义匹配检索系统应用示例
文本语义匹配检索系统应用示例
达摩院自研的ROM模型提供文本表示、文本排序的中英文单塔、双塔模型。区别于通用的BERT预训练模型,ROM模型在预训练任务中通过引入结合词权重的Random Masking方法和对比学习任务, 提升了文本表示能力和对关键词信息的建模能力。依赖ROM系列模型构建的文本检索系统在2022年3月份登顶MS MARCO Passage Ranking LeaderBoard。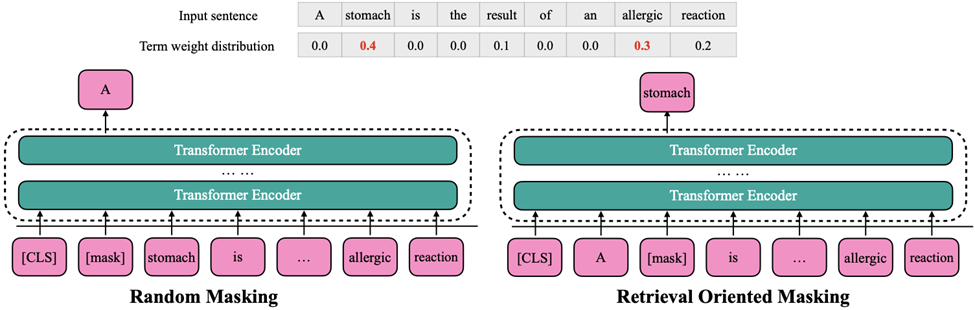 ROM预训练语言模型
ROM预训练语言模型
随着OpenAI提出GPT-3超大规模生成模型,AIGC领域也进入高速发展期,从文本生成、到图片生成甚至是视频生成。我们在魔搭社区也开源开放了多个生成模型。
3.1 PALM模型
模型链接:https://modelscope.cn/models?name=PALM&page=1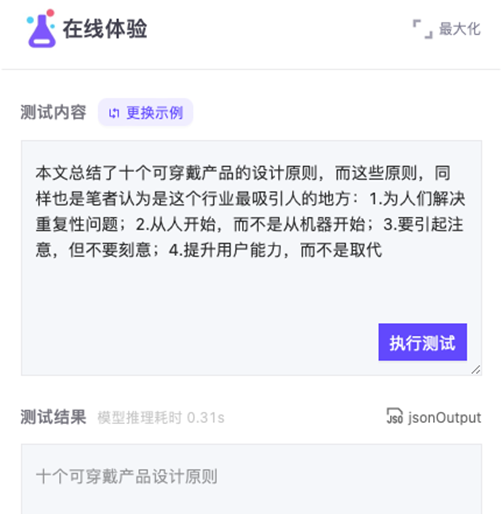 自动生成摘要
自动生成摘要
PALM模型采用了与之前的生成模型不同的预训练方式。在海量无标签文本语料上结合了Autoencoding和Autoregression两种方式,引入Masked LM目标来提升encoder的表征能力,同时通过预测文本后半部分来提升decoder的生成能力。相关技术论文发表在EMNLP 2020,论文发表时在CNN/Daily Mail Gigaword等数据集上实现了SOTA。
在PALM基础上,我们采用多阶段多任务渐进式从易到难的训练范式,提出了PALM 2.0中文预训练生成模型,并将训练好的下游场景模型和finetune训练能力完全开放,适用于大部分的中文生成业务场景。
3.2 PLUG模型
模型链接:https://modelscope.cn/models/damo/nlp_plug_text-generation_27B/summary
该模型提出时是中文社区最大规模的纯文本预训练语言模型,集语言理解与生成能力于一身,在语言理解(NLU)任务上,以80.179分刷新了当时CLUE分类榜单的新记录排名第一;在语言生成(NLG)任务上,在多项业务数据上较SOTA平均提升8%以上。
模型采用encoder-decoder的双向建模方式,在大规模的中文训练数据(1T以上)训练,因此在传统的zero-shot生成的表现上,无论是生成的多样性,领域的广泛程度,还是生成长文本的表现,较此前的模型均有明显的优势。
该模型的零样本生成能力较为突出,下面是一些具体展示:
✪ 小说续写
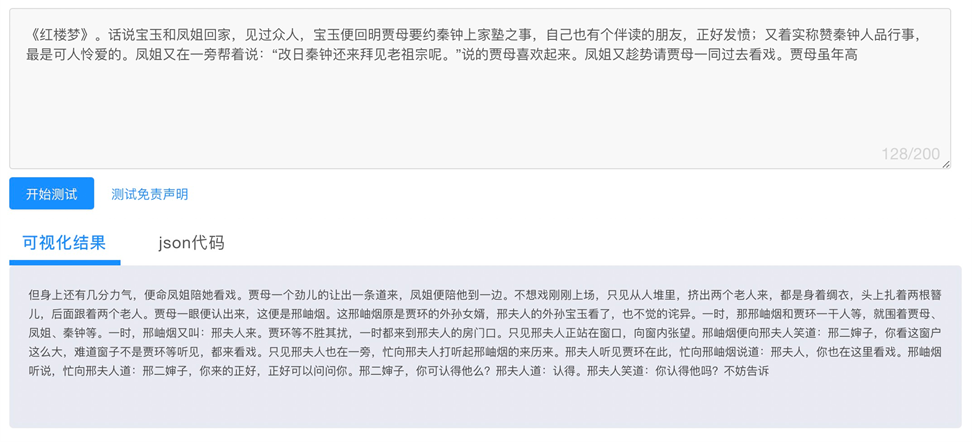
✪ 生活百科
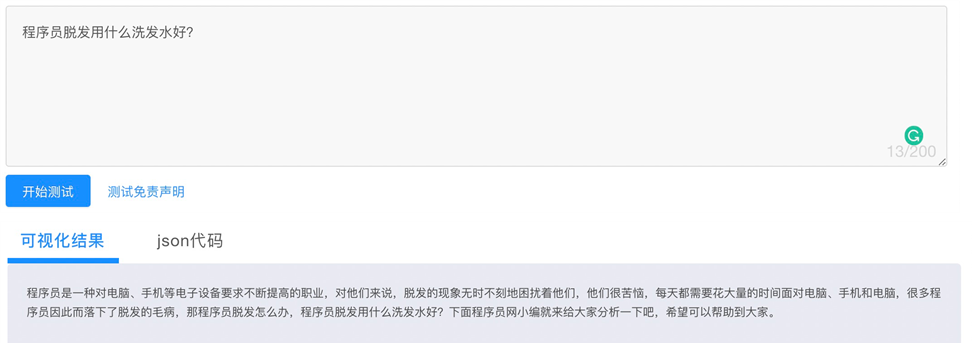
✪ 零样本学习
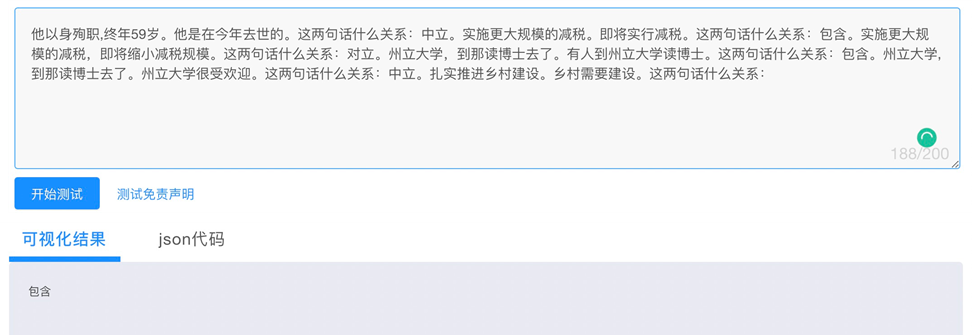
3.3 mPLUG模型
模型链接:https://modelscope.cn/search?search=mplug
在纯文本大模型PLUG的基础上,我们又推出了多模态的统一大模型mPLUG,2021年在视觉问答榜单VQA Challenge 取得第一,并首次超越人类基准,具体技术论文发表于EMNLP2022。
mPLUG核心解决了多模态融合时视觉特征序列过长导致的低效性、信息淹没的问题,提出新的跨模态融合方法skip-connected network。在仅用1300万图文数据预训练,便在VQA、Caption等核心多模态任务上取得同等参数规模下的SOTA,除此之外,还可用于下游的视频文本的理解和生成场景。
✪ 视觉问答(VQA)

✪ 图像描述(Image Captioning)

✪ 视觉定位(Visual Grounding)

✪ 图文检索(Image-text Retrieval)

3.4 中文版GPT-3
模型链接:https://modelscope.cn/models/damo/nlp_gpt3_text-generation_13B/summary
使用入口:https://modelscope.cn/studios/damo/ai_writer/summary
因为GPT-3主要支持英文,对于中文效果较差,访问使用还需要申请,因此我们推出了中文GPT-3,免费开放,可自由访问,希望为中文社区带来更好用的中文生成大模型。
我们创新性地结合无监督数据和有监督prompt数据,并考虑到用户的不同GPU资源,训练了不同版本规模的中文GPT-3,包括base/large/1.3B/2.7B/13B/30B,以及后续即将推出的175B。目前模型具备多种生成能力,如代码生成、小说续写、作文生成等。
✪ 代码生成
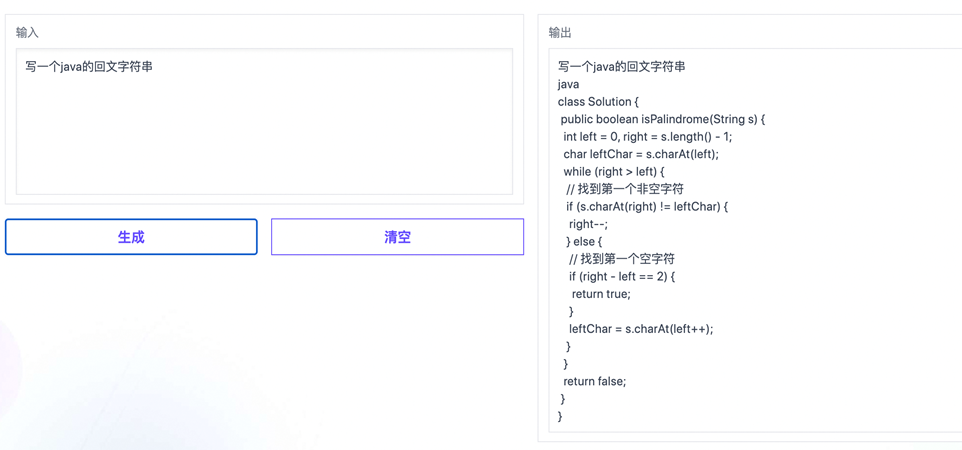
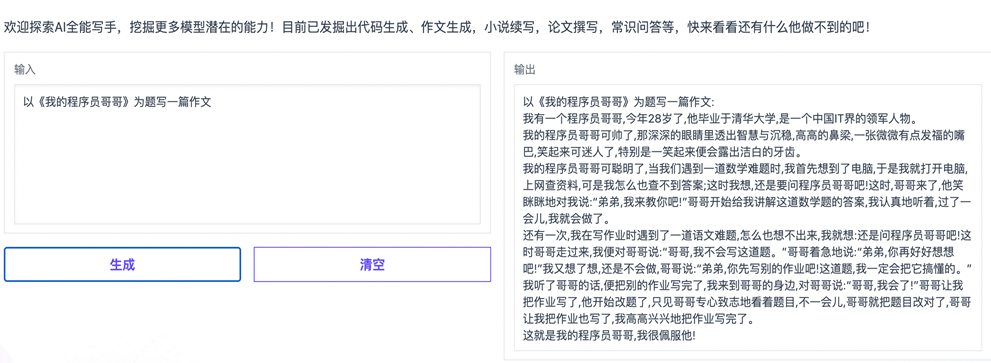
✪ 作文生成
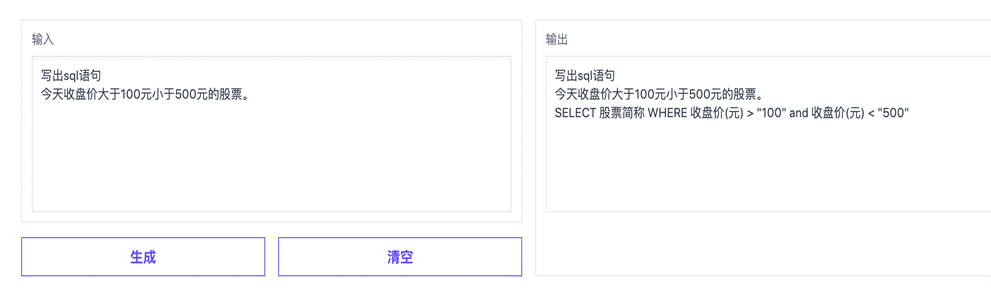
✪ SQL生成
4.1 SPACE 对话模型
模型链接:https://modelscope.cn/models/damo/nlp_space_pretrained-dialog-model/summary
如何将人类先验知识低成本融入到预训练模型中一直是个难题,我们提出了一种基于半监督预训练的新训练方式,将对话领域的少量有标数据和海量无标数据一起进行预训练,从而把标注数据中蕴含的知识注入到预训练模型中去,打造了SPACE 1/2/3 系列预训练对话模型,在11个国际公开对话数据集上取得了最好结果。 在魔搭社区上,我们以SPACE模型为基座,开源了理解、生成fine-tuning和意图分类、对话状态追踪和回复生成推理pipeline,覆盖了对话系统各个核心模块,只需几行代码,就能快速上手对话系统,复现论文里的SOTA效果。
在魔搭社区上,我们以SPACE模型为基座,开源了理解、生成fine-tuning和意图分类、对话状态追踪和回复生成推理pipeline,覆盖了对话系统各个核心模块,只需几行代码,就能快速上手对话系统,复现论文里的SOTA效果。
4.2 SPACE-T表格问答模型
模型链接:https://modelscope.cn/models/damo/nlp_convai_text2sql_pretrain_cn/summary
现代企业花费大量精力构建了数据库、数据中台等基础设施,支撑CRM、ERP、OA等系统,但是常规的企业智能化方案中,仍需要花费大量资源,去重新构建图谱、意图、FAQ等知识形态。如果能够利用已有的二维关系型数据库直接构建企业智能化系统,就可以节省大量成本。
达摩院研发了SPACE-T表格问答模型,能够智能理解分析表格信息,已经在阿里云智能客服等多个产品中输出,服务了多领域的客户。这次在魔搭社区上免费开源开放,能够让有需要的企业通过对接自己的数据库,定制化构建自己的表格问答应用,可具备单/多属性查询能力、单/多条件筛选能力、最值/平均/计数等基础统计能力等,如下图所示: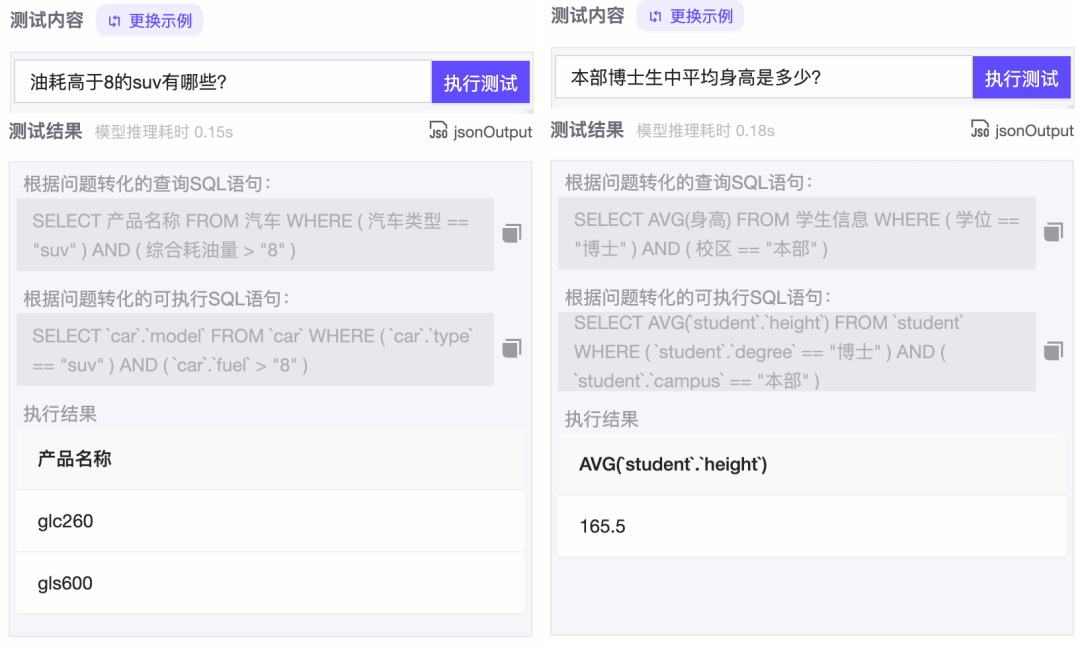 技术上,该模型由亿级表格数据预训练构建,具备良好的开箱即用能力。模型在训练和推理过程中都会将表格的Schema信息作为输入,使模型能够理解表格信息,实现了表格知识即插即用的效果。
技术上,该模型由亿级表格数据预训练构建,具备良好的开箱即用能力。模型在训练和推理过程中都会将表格的Schema信息作为输入,使模型能够理解表格信息,实现了表格知识即插即用的效果。
模型名称:CSANMT连续语义增强机器翻译体验链接:https://modelscope.cn/models?name=CSANMT&page=1&tasks=translation
达摩院长期致力于机器翻译的研究,产生了一批高质量的模型。这次我们重点开源了CSANMT连续语义增强机器翻译,这是我们最新研发的高质量神经机器翻译(NMT)模型,获得了ACL2022杰出论文奖。
CSANMT模型由编码器(Encoder)、解码器(Decoder)和语义编码器(Semantic Encoder)三个单元构成。语义编码器可以在连续分布式语义空间捕捉源语言与目标语言的相似性,从而更加充分、更加高效地利用双语训练数据,不仅可以显著提升了翻译质量,而且能够有效改善了模型的泛化能力和鲁棒性。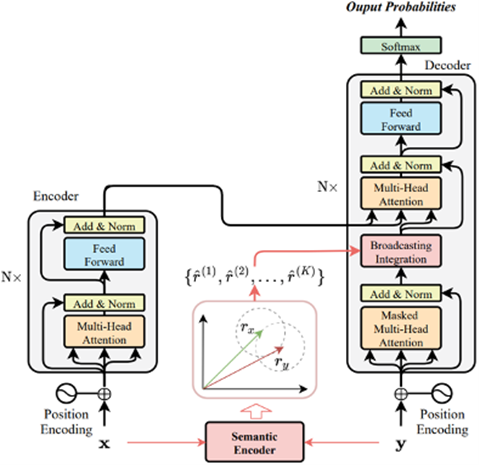 首批开源的CSANMT模型包括中英、英中、英法 、法英、英西、西英等语向的模型,后续还将开源覆盖欧洲、东亚、东南亚等区域主要语种的CSANMT翻译模型。我们将对模型进行持续迭代优化,确保性能和体验处于业内领先水平。
首批开源的CSANMT模型包括中英、英中、英法 、法英、英西、西英等语向的模型,后续还将开源覆盖欧洲、东亚、东南亚等区域主要语种的CSANMT翻译模型。我们将对模型进行持续迭代优化,确保性能和体验处于业内领先水平。
自然语言处理代表着AI从感知智能走向认知智能,相关研究如火如荼,随着预训练新范式的推动,底座模型越来越“通识”,下游模型场景越来越丰富,落地效果也更加完善,各种应用方兴未艾。
魔搭社区不仅提供了达摩院自己研发的100多个NLP模型,也接入了业界一流科研机构的众多优质模型,比如澜舟科技的孟子系列轻量化预训练语言模型,智谱AI的mGLM多语言模型等...欢迎大家基于这些优质模型,搭建出自己的创意应用,更希望自然语言处理迎来一个全新的时代。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢