
2022 年是人工智能生成内容(AI Generated Content,AIGC)爆发的一年,其中一个热门方向就是通过文字描述(text prompt)来对图片进行编辑。已有方法通常需要依赖在大规模数据集上训练的生成模型,不仅数据采集和训练成本高昂,且会导致模型尺寸较大。这些因素给技术落地于实际开发和应用带来了较高的门槛,限制了 AIGC 的发展和创造力发挥。
针对以上痛点,网易互娱 AI Lab 与上海交通大学合作进行了研究,创新性地提出一套基于可微矢量渲染器的解决方案——CLIPVG,首次实现了在不依赖于任何生成模型的情况下,进行文字引导的图像编辑。该方案巧妙地利用矢量元素的特性对优化过程进行约束,因此不仅能够避免海量数据需求和高昂的训练开销,在生成效果上也达到了最优的水准。其对应的论文《CLIPVG: Text-Guided Image Manipulation Using Differentiable Vector Graphics》已被 AAAI 2023 收录。
CLIPVG 的总体流程如下图所示。首先会对输入的像素图进行不同精度的多轮矢量化 (Multi-round Vectorization),其中第 i 轮得到的矢量元素集合记为Θi。各轮得到的结果会被叠加到一起整体作为优化对象,并通过可微矢量渲染 (Differentiable Rasterization) 转换回到像素域。输出图片的起始状态是输入图片的矢量化重建,然后按照文字描述的方向进行迭代优化。优化过程会根据每个 ROI 的区域范围和关联文字,计算 ROI CLIP loss,并根据梯度优化各个矢量元素,包括颜色参数和形状参数。
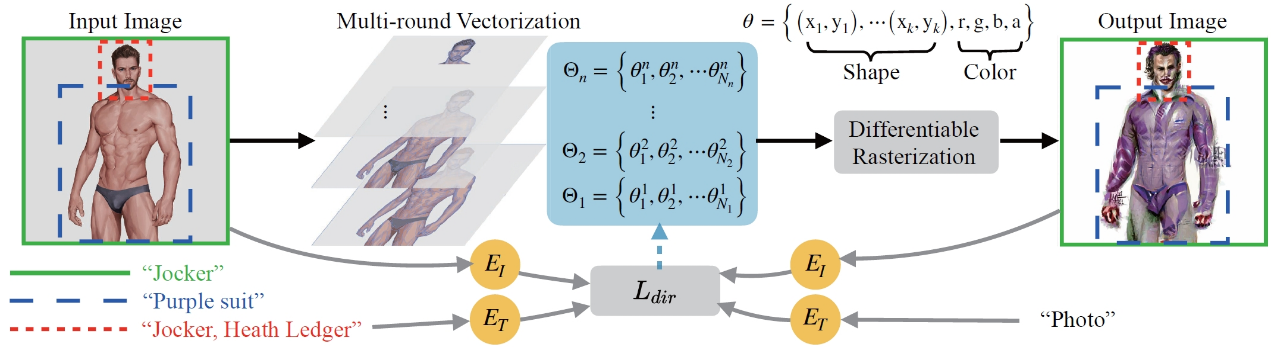
整个迭代优化的过程可见下例,其中的引导文字为”Jocker, Heath Ledger”(小丑,希斯 · 莱杰)。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢