
本文最初发布于swyx的个人博客。
GPT-2的周期为6个月:
-
2019年2月,OpenAI宣布了GPT-2,但说它太危险了,尚不能全部发布,并从非营利性改组为有限营利(capped-profit)。
-
到了8月,两名硕士生公开克隆了它,并命名为OpenGPT-2。
-
到了11月,经过谨慎地分阶段发布,OpenAI发布了他们的1.5B参数模型。
GPT-3的周期为10个月:
-
2020年5月:OpenAI将GPT-3以论文形式发布,并在2020年6月发布了封测版API。2020年7月:EleutherAI成为一个真正开放的OpenAI替代品。
-
2020年9月:授予微软“GPT-3独家许可”。
-
2021年1月:EleutherAI发布了The Pile,他们800GB的数据集。
-
2021年3月:EleutherAI发布了他们开放的GPT-Neo 1.3B和2.7B模型。
-
2021年11月:OpenAI将API从等待列表中移除。
-
2022年5月:Meta面向研究人员发布了OPT-175B(包括日志和一个开放许可)。
-
2022年6月:Yandex在Apache-2许可下发布YaLM-100B。
-
2022年7月:HuggingFace在RAIL许可下发布BLOOM-176B。
Text-to-Image的周期为两(?)年(GANs的整个历史达10年之久):
-
2020年6月:OpenAI在博客上介绍了Image GPT。
-
2020年12月:Patrick Esser等人发表论文Taming Transformers for High-Resolution Image Synthesis(又称VQGAN,大幅改进了2019年的VQVAEs)。
-
2021年1月:OpenAI宣布了第一代DALL-E的结果并开源CLIP。
-
2021年5月:OpenAI宣布,他们发现扩散模型在图像合成中击败了GANs。
-
2021年12月:CompVis小组发布了使用潜在扩散模型合成的高分辨率图像,以及原始存储库CompVis/latent-diffusion。
-
2021年12月:OpenAI发布了GLIDE:利用文本引导扩散模型实现逼真的图像生成和编辑。
-
2022年3月:Midjourney推出封测版。
-
2022年4月:OpenAI宣布推出DALL-E 2,并提供受限“研究预览”。
-
2022年5月:谷歌发布他们的Imagen论文(在3天时间内用PyTorch实现)。
-
2022年7月:DALL-E 2通过OpenAI的UI/API提供公开测试版(有等待名单)。
-
2022年7月:Midjourney也通过他们的Discord宣布了一个完全开放的测试版。
-
2022年8月:Stable Diffusion 1.4公开发布,遵循OpenRAIL-M许可。模型和代码来自CompVis + Runway,Stability AI提供资金以增加计算能力。
-
2022年9月:OpenAI将DALL-E 2移出等待名单。
-
2022年10月更新:Runway发布Stable Diffusion 1.5版,存在一定的争议性。
-
2022年11月更新:Stability发布Stable Diffusion 2.0。
当然,上面这个时间线是经过仔细筛选的;如果把扩散模型(2015年)和Transformer模型(2017年)从学术论文发表到开发的历史以及GANs之前的工作都考虑进来,那么这个故事要长得多。还可以看下Stable Diffusion在RunwayML的研究起源,以及2021年12月,Emad在与Elad Gil的聊天中对CC12M的突破性进展的描述。
但更有趣的是此后发生的事情。9月份,OpenAI发布音频转文本模型Whisper,遵循MIT许可,没有设置API付费墙。当然,音频转文本领域的滥用空间比较小,但也有不少人猜测,人们对Stable Diffusion发布的反应影响了开源决策。
足够先进的社区是有魔力的。研究人员和资金充足的团队一直都非常擅长创建新的基础模型(FM),但提供产品化用例和优化模型的最后一英里则是开源社区非常擅长的工作。
在这方面,最可量化的例子发生在最近的Dreambooth循环中(通过主题的少样本分析对text-to-image进行微调以插入场景)。

Dreambooth是一个值得考虑的优化目标,因为你不仅要下载一个模型并运行它,还要在自己的样本图像上运行微调训练,但最初的移植需要大量的内存,以至于对大多数人来说,不可能在自己的机器上运行。
是Corridor Digital的家伙们让它在YouTube上走红。
Twitter形式的时间线:
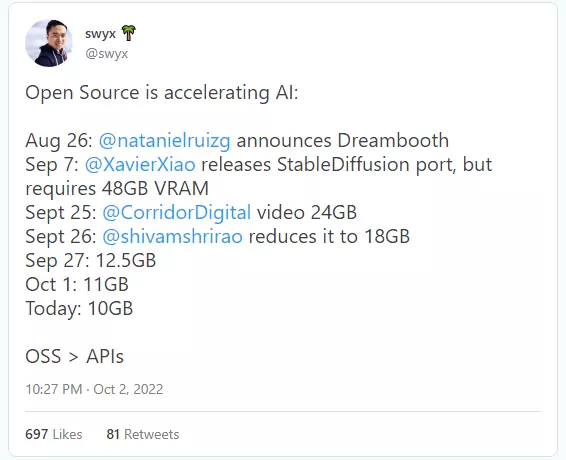
可以看出,为了那些在自己机器上运行模型的人,开源社区在12天内完成了开源移植,然后在随后的25天内将系统要求降低了79%。
更新:10月8日,系统需求再次降低,变成8GB。
大部分优化工作都发生在GitHub上,由Xavier Xiao(来自新加坡的生成式模型和优化博士,就职于AWS AI)和Shivam Shrirao(驻印度的高级计算机视觉工程师)完成,并得到来自意大利的Matteo Serva的帮助。两人与原Dreambooth团队都没有关系。
低处的果实都摘完了,使得一些人开始担心收益递减,但还是存在一些概念验证,将Stable Diffusion缩小到可以在手机上运行(之前已降至10GB甚至5GB——消费级卡的内存为6-12GB,iDevices有统一内存)。
这可能是开源人工智能模型优化的圣杯,因为这样一来,图像生成实际上就不再受云经济和利润动机的限制了。
2022年10月更新:这里有一个开源实现:https://github.com/madebyollin/maple-diffusion
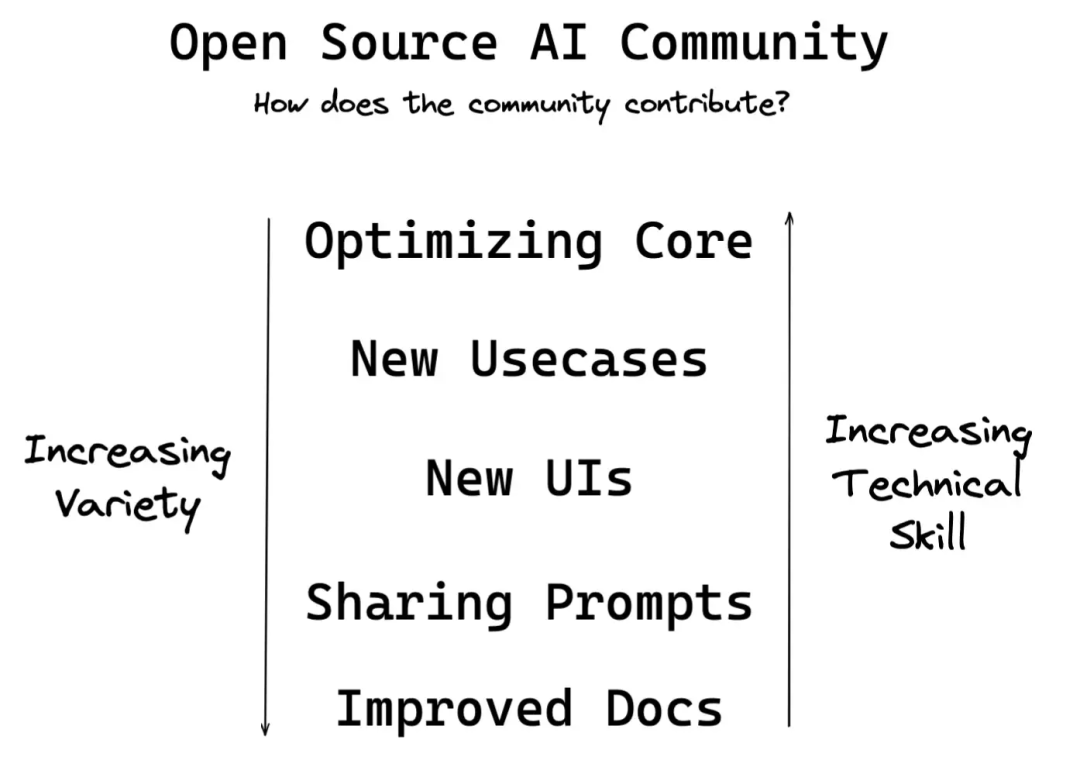
以下是提高所需技术技能的一个大致顺序:
-
原始的CompVis README对于初学者而言并不友好
-
社区合力创建:
-
R*tard指南和常规指南
-
博客
-
推特主题
-
YouTube演练
-
谷歌专栏
-
带注释的网站和图示说明
-
Prompt工程是一种后天技能,在GPT3发布3年后,有人仍然用它得出了令人惊讶的结果(1、2);这意味着LLM有很大的潜力(不只是结果),而我们尚处于初级探索阶段
-
对于分享Prompt,每个社区现在都有了成熟完备的方法,以此为基础,我们可以建立Prompt库,大幅减少寻找Prompt的耗时(从大于30秒到不足300毫秒,减少了2个数量级!),降低Prompt工程的学习难度。
-
社区也是利用这种方法摸索已知的难题,如如何生成真实的手和Negative Prompt的重要性。
-
由于Stable Diffusion“只是”一个Python脚本,人们可以根据自己的需要创建自己的UI,而不必受Stability AI自己的Dreambooth所束缚。
-
AUTOMATIC1111已经成为社区中最重要的Web UI,它提供了大量的功能,可谓集社区发现的SD使用智慧之大成。
-
由于ML社区偏爱Windows,所以开源社区已经实现了大量在M1 Macs或许还有iPhone上运行的技巧(如上所述)。
-
通常,SD UI是独立的应用程序,但新的交付模式使它们可以作为现有工作流程的一部分来使用,在Photoshop、Figma、GIMP,甚至是VR里面。
-
我不清楚谁首先发明了Inpainting和Outpainting技术(它最初是在DALL-E的公告中被提及,但是在像这样的开源UI被创建出来后,它才真正被广泛使用)
-
更多:超高分辨率Outpainting,3D世界
-
与其他工具/技术搭配使用是成熟创新的另一个来源:
-
“反向Prompt工程”也就是使用图像进行Prompt(使用CLIP Interrogator)
-
使用txt2mask来增强Inpainting
-
多个后处理步骤,包括使用Real-ESRGAN、TECOGAN、GFPGAN、VQGAN等(如AUTOMATIC1111中的“hires fix”)
-
创建一个GRPC服务器(用于与Stability AI通信)
-
为txt2music、music2img等新模式做准备
-
(如上所述)最大限度地减少Stable Diffusion和Dreambooth占用的内存
-
将Stable Diffusion的速度提高了50%
一个有趣但重要的切入点——大部分AI/ML的东西都是用Python编写的,而Python作为一种分发机制是很不安全的。也就是说,“开源人工智能”的兴起也将伴随“开源人工智能安全”需求的日益增加。
整个过程让人不禁联想到开源是如何吞噬Software 1.0的:
-
版本控制:从Bitkeeper到Git
-
语言:从Java工具链到Python、JavaScript和Rust
-
集成开发环境(IDE):从[许多相当不错的IDE]到VS Code占据60%以上的市场份额
-
数据库:从Oracle/IBM到Postgres/MySQL
Anders Hejlsberg是Turbo Pascal、TypeScript等5种语言之父,他有一句名言:未来,不开源的语言是不会取得成功的。或许,对于技术栈中越来越多的东西,你都可以说同样的话。
我们很容易得出这样的结论,在Software 2.0/3.0中也会出现同样的情况,但还存在一些问题。
对于经济学家来说,希望基础模型开源发布是违反直觉的。据估计,训练GPT-3的成本在460万到1200万美元之间,还不包括人工成本和失败的尝试(现在,一些创业公司声称已将其降低到45万)。即使是Stable Diffusion令人印象深刻的60万美元成本(Emad暗示真实数值要低得多,但也说他们的实验成本是13倍(200万A100小时)),在没有投资回收计划的情况下,也不是什么可以随意忽视或放弃的东西。
从OpenAI通过API盈利的轨迹来看,每个人都明白AI经济的发展趋势:
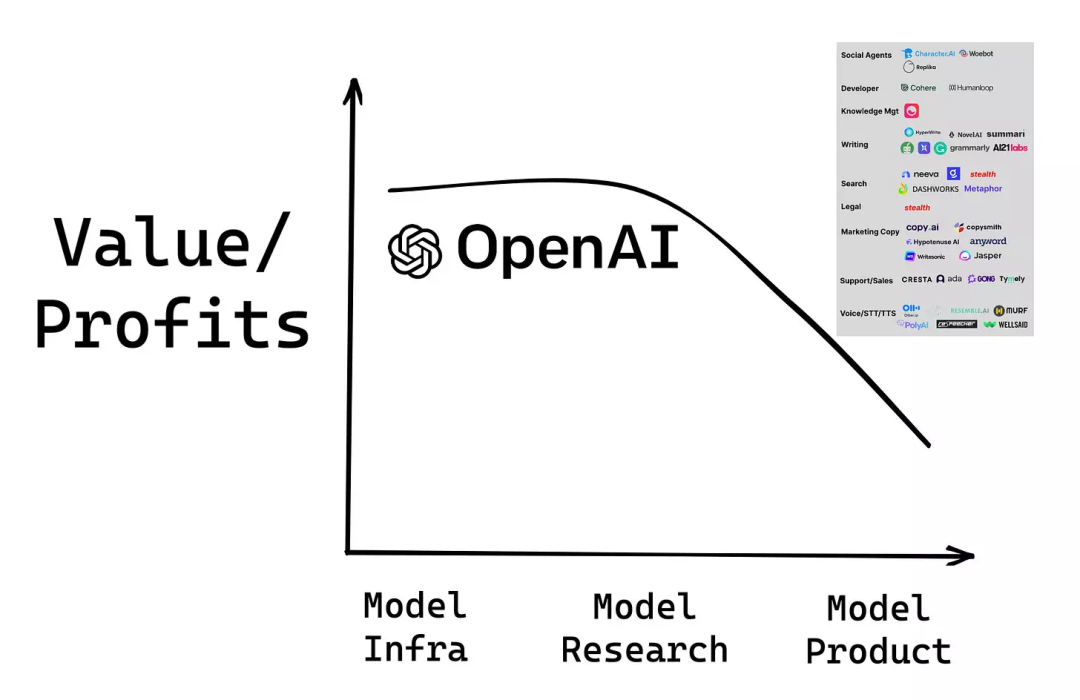
(如果Research > Infra可能会有争议,所以让它们大致相等,就迁就我一下吧)
但作为非经济行为体,Stability AI的既定目标是既压低拥有专有基础模型研究的经济价值,又扩大人工智能的总体TAM:
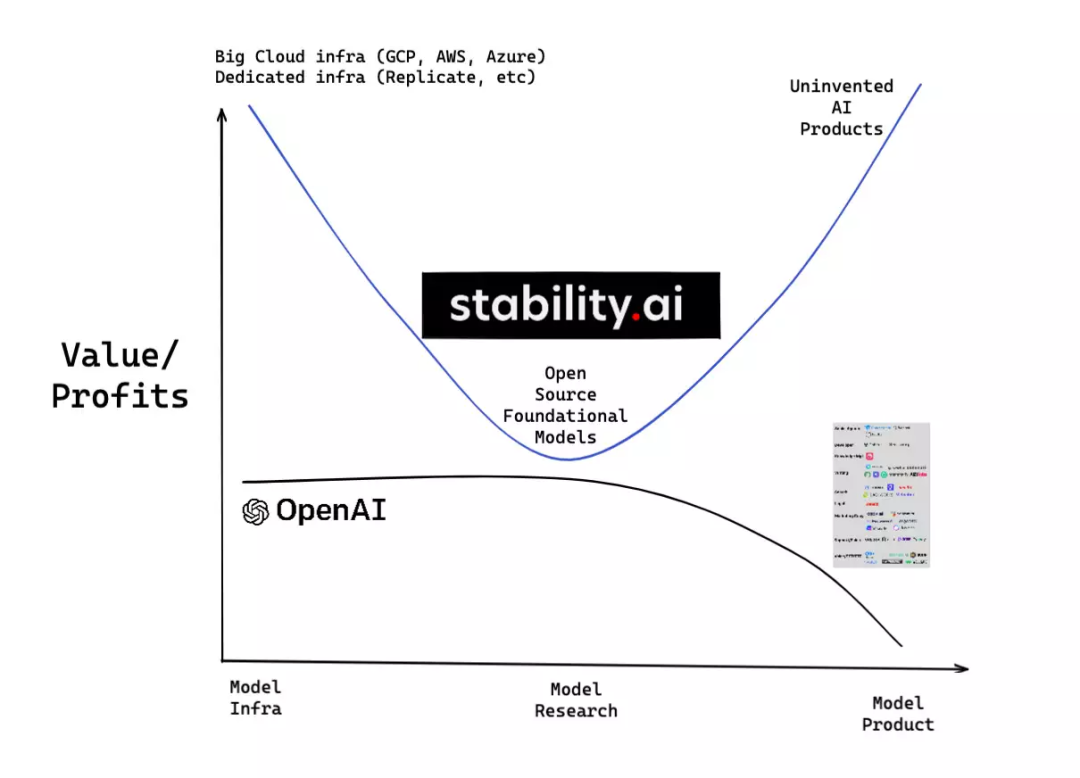 这是由Stan Shih提出的关于行业价值分布的微笑曲线模型,Ben Thompson也做过广泛的讨论。
这是由Stan Shih提出的关于行业价值分布的微笑曲线模型,Ben Thompson也做过广泛的讨论。
最大的问题是Stability公司打算如何为自己融资——1亿美元的A轮融资为他们争取了一些时间,但在我们真正知道Stability公司打算如何赚钱之前,这个生态系统不会真正稳定下来。
来自Emad的回应:“商业模式很简单,规模和服务与普通COSS类似,但有一些附加价值。
-
https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/24
-
https://github.com/divamgupta/diffusionbee-stable-diffusion-ui/issues/5 -
https://github.com/breadthe/sd-buddy/discussions/20
2022年10月更新:InvokeAI是一个例外,它遵循MIT许可。
Stable Diffusion自己发布了一个新的CreativeML Open RAIL-M许可(RAIL代表Responsible AI,由一个独立的团队创建),用于管理模型权重(要花60万美金才能获得),其中某些部分与OSI批准的许可兼容,但也有些不兼容的用例限制。如果你与法律部门和OSI的人打过交道,就会知道这是行不通的,这种许可分歧没有法律先例可依。
StabilityAI已经清楚地表明,你可以将其产品用于商业目的,他们甚至公开支持Midtravel使用StabilityDiffusion,但当有一天,赌注扩大1000倍时,法律细节就开始变得重要了。
来自HuggingFace人工智能顾问Carlos Muñoz Ferrandis的说明:“Meta发布的OPT175(LLM)、BB3(聊天机器人)和SEER(计算机视觉)许可类似于RAIL(包括用例限制),仅用于研究目的(许可证有2个取决于模型的变体)。”
OpenAI Whisper是我所知道的第一个模型、权重和代码都遵循MIT许可(简单、"真正开源")的例子。
Emad更正道:“除了Stable Diffusion,我们支持的所有模型都已经在MIT许可下发布了,例如,花了120万A100小时的OpenCLIP。”
时间敏感提示:如果你很关心许可,则可以关注下GitHub和开源研究所10月18日组织的讨论和一个专家组。你也可以联系Tidelift总顾问Luis Villa。
撇开OSI的批准不谈,到目前为止,我们有意忽略了另一个问题,那就是“开源”到底意味着什么。
在传统的Software 1.0时代,“开源”意味着代码库开源,但不一定是基础设施设置的细节,也不一定是代码所积累/操作的数据。换句话说,开放代码并不意味着开放基础设施或开放数据(虽然不是必须的,但在实践中,通常至少会有一些关于如何自托管的基本指南)。
在Software 2.0时代,数据收集变得非常重要,并开始主导代码(被简化为模型架构)。像ImageNet这样的开放数据集帮助培养了整整一代ML工程师,最明显的动力来自Kaggle比赛,当然还有ImageNet挑战赛本身(在这项赛事中,AlexNet和CNN推动了整个领域向深度学习的融合)。通过半同态加密,你甚至可以屏蔽数据以创建像Numerai这样的系统——不是严格意义上的开放,但也足够开放,无聊的数据科学家可以摆弄下这些假数字,赚点外快。不过,权重通常是不开放的,因为那是训练成本最高的内容。
有了Software 3.0和已知的Chinchilla缩放曲线,LLM和FM成了人们在单一大型语料库上进行的一次性大规模投资。
“开源AI”运动正在用几种不同的方式来解决这个问题:
-
开放数据集:例如,LAION-5B和The Pile。这些数据集已经针对Waifus、日语、中文和俄语进行了修改。
-
开放模型:通常通过研究论文发布——如果提供了足够的细节,人们就可以自己重新实现,就像GPT3和Dreambooth那样。
-
开放权重:这个新的潮流源于HuggingFace的BigScience(发布了BLOOM),然后由Stability AI应用于text-to-image,并由OpenAI Whisper接续(其经济性在问题1中讨论过)。
-
开放接口:不只提供了可供调用的API,就像OpenAI在GPT3中所做的那样,而是直接提供了对代码的访问,为的是方便用户修改和编写他们自己的CLI、UI和其他任何他们想要的东西。
-
开放Prompt:用户(像Riley Goodside)和研究人员(像Aran Komatsuzaki)分享了Prompt技术的突破,释放了FM的潜力。
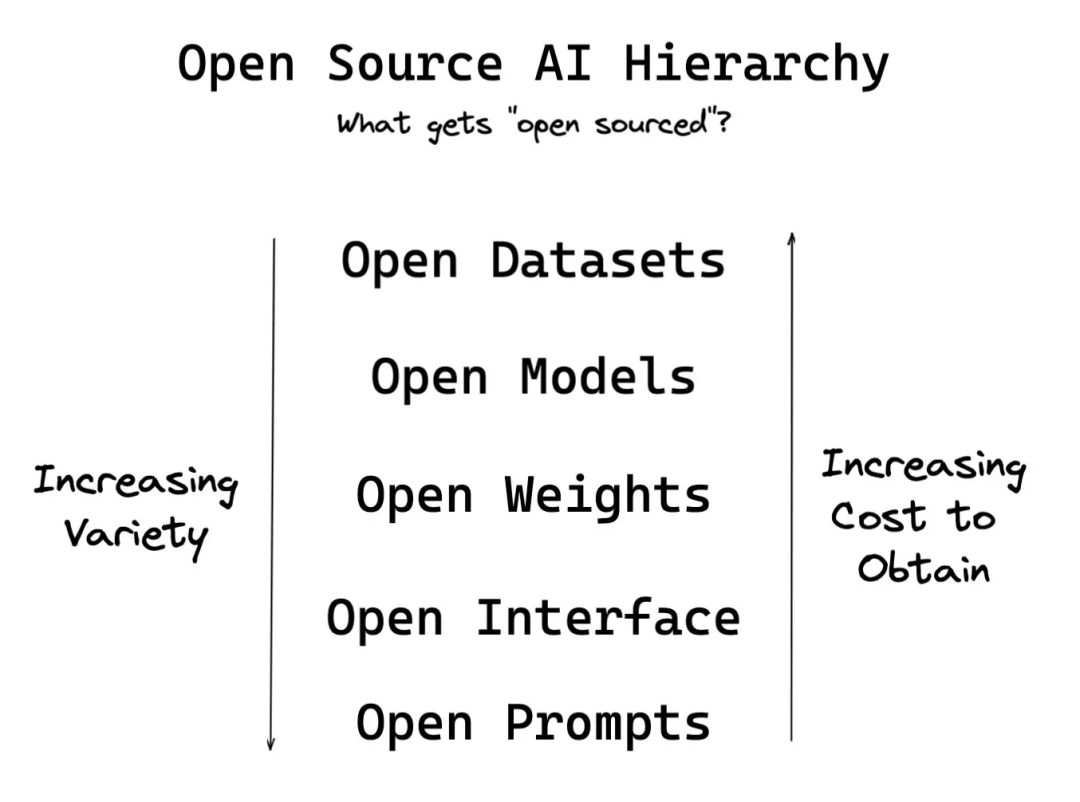
上述内容的确切顺序会根据实际的进展和背景的变化而变化,但这感觉对吗?
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢