
标题:Visually Grounded Commonsense Knowledge Acquisition
录用会议:AAAI 2023
作者:Yuan Yao, Tianyu Yu, Ao Zhang, Mengdi Li, Ruobing Xie, Cornelius Weber, Zhiyuan Liu, Haitao Zheng, Stefan Wermter, Tat-Seng Chua, Maosong Sun
单位:清华大学,新加坡国立大学,汉堡大学,腾讯
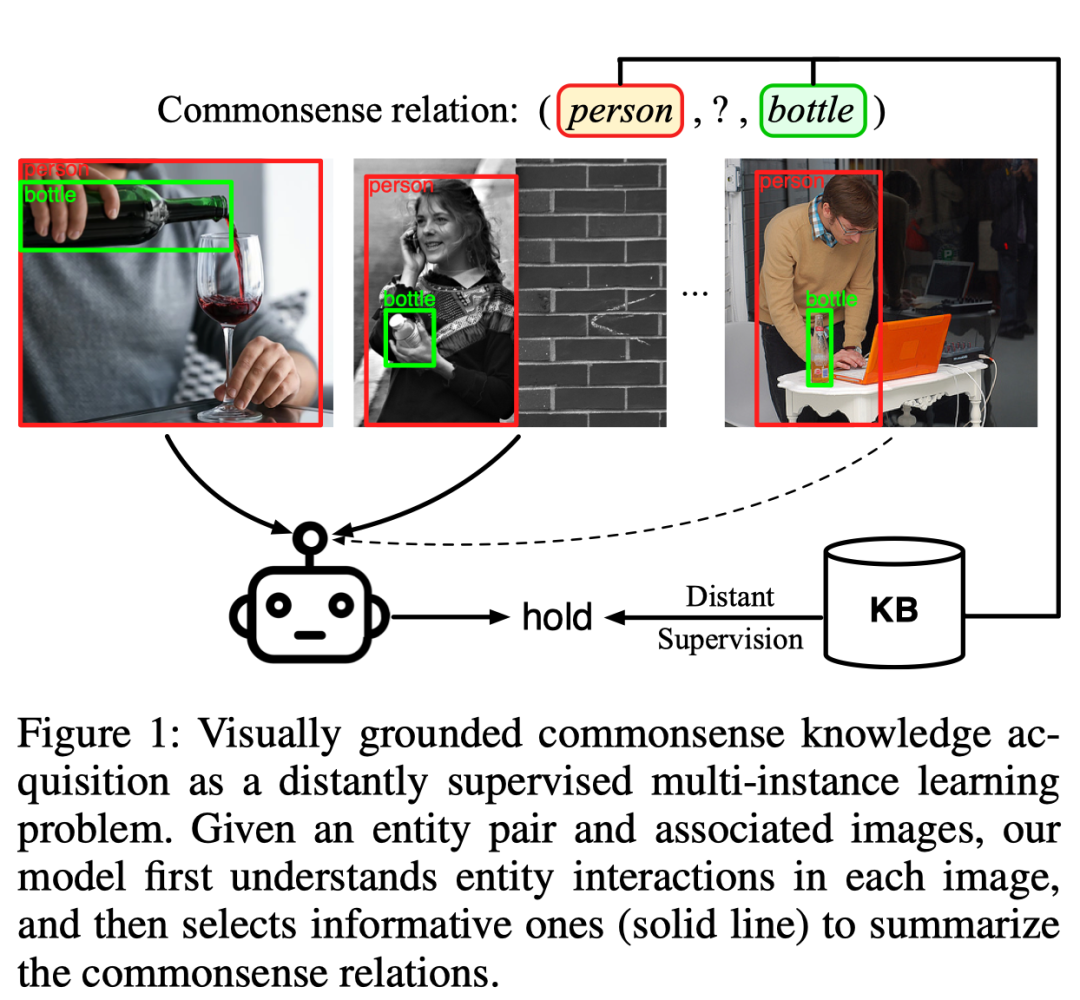
大规模的常识性知识库促进了许多人工智能应用,如计算机视觉、自然语言处理。常识知识的自动获取(CKE)因此成为了一个重要而具有挑战性的问题。基于文本进行常识知识的自动获取通常受限于文本中常识的稀疏性和报告偏差。相比而言,视觉感知提供了关于现实世界实体的丰富的常识知识,例如(人-可以抓握-瓶子)。在本工作中,我们提出将基于视觉感知的常识获取定义为一个远程监督的多样本学习任务(图 1),模型可以在不依赖任何图像中实体关系标注的情况下,从包含特定实体对(比如 人-瓶子)的大量图片中总结出实体之间的常识关系(比如 可以抓握)。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢