
作者:温佳鑫、顾煜贤、柯沛、宋溢、郑楚杰、孙豪、冯卓尔、张哲昕、张正
本文转自人工智能THU公众号,阅读原文
本报告对近年国内外各高校和企业在大规模神经对话系统方向上的研究进行了梳理和总结,从任务特点、模型结构、训练方法以及训练数据等方面详细介绍了其中的代表性工作,并展望了该领域未来的发展趋势。
1 引言
对话系统是自然语言处理和人工智能领域的重要研究方向,受到学术界和工业界的广泛关注。早期的对话系统大多基于规则和模板构建,人力成本较高且迁移性弱[28]。随着深度学习的发展,基于神经网络的对话系统逐渐成为研究热点,该类对话系统大多采用编码器-解码器(Encoder-Decoder)结构[21],其中编码器通过编码对话上下文以获取其语义信息,而解码器则根据编码器得到的隐状态向量进行逐词解码,最终生成对话回复。近年基于Transformer[26]的大规模预训练模型兴起,诸如GPT[16]、BART[13]、T5[17]等模型在包括对话生成在内的各类自然语言生成任务上都取得当时的最优性能,这也让研究者们看到了大规模预训练模型在对话系统研究上的潜力。因此,国内外各高校和企业都开始研发基于大模型的神经对话系统,旨在提升其对话交互能力。
图1展示了近年来大规模神经对话系统的发展历程。从中可以看出,国内外众多知名研究机构均投身对话大模型的构建中,现有对话系统的交互能力也在预训练技术的加持下得到了飞速提升。对话系统领域的研究者既在对话数据构建和清洗上做了精细的工作[22,33],又在预训练过程中设计了众多预训练任务[2,10]来使模型捕捉到对话数据的特点,从而得到更好的生成性能。本文的后续将从任务特点、模型结构、训练方法以及训练数据等方面详细介绍其中的前沿研究工作。
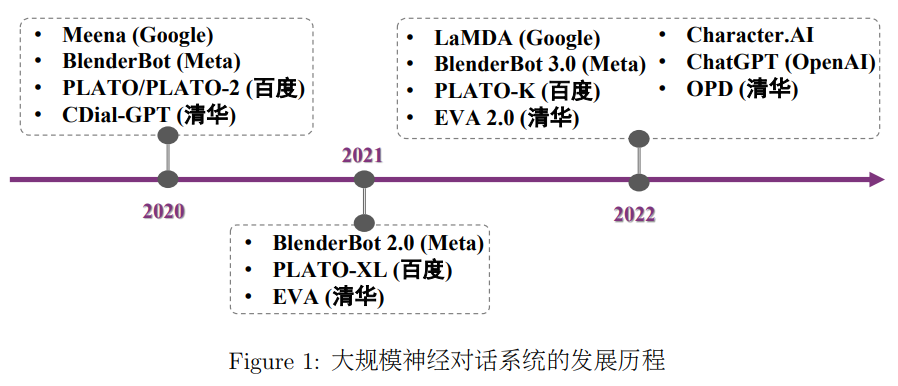
2 大规模神经对话系统
2.1Meena (Google)
Meena[1]是Google于2020年发布的对话系统。在Meena出现之前,小冰(XiaoIce)[34],kuki AI(mitsuku)等一系列产品,通过集成自然语言处理、信息检索等多种技术构建了闲聊对话系统。但是这些产品在对话过程中仍存在若干问题,如闲聊话题受限,生成违反常识的错误内容,回复过于通用、模糊等,从而在多轮对话上的表现较弱。
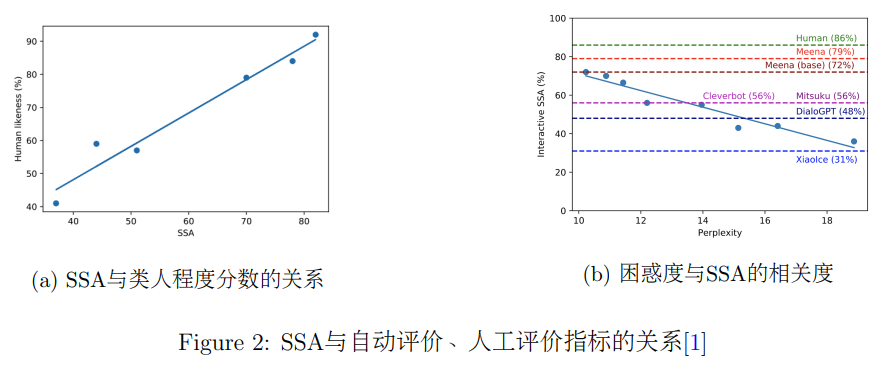
Google的研究者总结了对话系统的常见问题,首先提出了评价闲聊对话系统性能的人工评价指标SSA(Sensibleness Specificity Average),并且通过实验说明该指标与自动指标困惑度(Perplexity)在评价生成效果时具有较高的一致性。SSA主要对回复内容是否包含事实性错误以及是否含有丰富信息量这两个层面进行人工评价。人工标注者会针对系统生成的回复判断其是否符合事实。随后,没有事实性错误的回复会被根据内容判断具体程度,例如“上文:我喜欢网球。回复:那挺好。”的这类回复会被认为不够具体。团队发现该评价指标的得分与模型生成回复的类人程度之间具有较高的相关性。
此外,除了针对生成回复的静态评价,团队还开展交互性评价。标注者与模型进行至少 7 轮(14 回合)、至多 14 轮(28 回合)的交互,标注者会判断模型在交互上事实性表现。研究者发现,这个结果与PPL负相关。研究者也在几个通用的对话系统上进行了类似的人工评价。
为了构建更好的对话系统,Google的研究者在公开的社交平台上爬取了数据集,每条数据拥有一个根据回复方向诱导的树形结构。他们从树上采样一条通路,并且限制对话轮数为7,形成了训练数据的上文-回复(Context-Response)对,经过数据清洗后数量为 867M,数据集大小为 341 GB,是 GPT-2 训练数据(40GB)的20倍左右。随后,Google的研究者在该数据集上训练了Meena模型,它以一个单层 Evolved Transformer [24]作为编码器,13层 Evolved Transformer 作为解码器的序列到序列模型,共含有2.6B的参数。Meena 最大的模型在测试集上的困惑度是10.2,其自动评价和人工评价结果均优于基线模型。
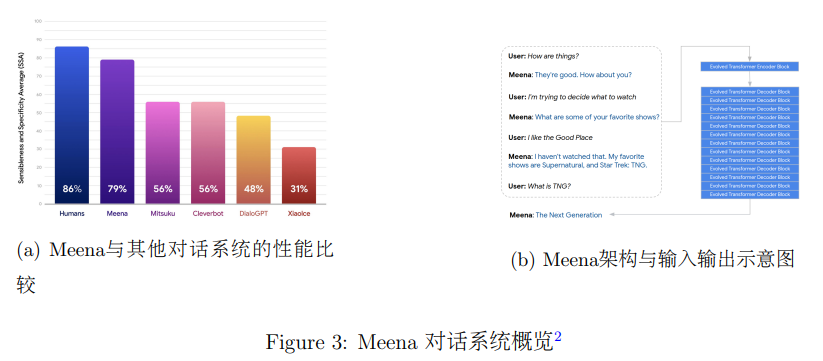
Google的研究者指出,优化算法、解码、架构、数据以提升对话系统性能是Meena 的目标。同时,他们也认为人格、事实性等都是对话系统在应用过程中需要重点考虑的因素。
2.2 BlenderBot (Meta)
BlenderBot系列模型由Meta AI(前FAIR)研发,截至2022年,共包含3代版本。
第一代 BlenderBot[20] 发布于2020年,它包含五个参数规模的预训练模型:90M, 400M, 1.4B, 2.7B和 9.4B,均为基于 Transformer[26] 的编码器-解码器结构。这一代的BlenderBot采用了两阶段的训练模式。在第一阶段时,模型在经过严格清洗的大规模Reddit语料[6] 上进行预训练。在第二阶段时,模型在人工构建的小规模、高质量语料上进行微调,这些语料特别突出了对话系统的人格化[31] 、知识性[8] 、共情性[19] 及这些特性的融合[23] 。此外,在构建第一代BlenderBot的过程中,研究者特别探究、分析了诸多影响对话性能的因素,例如:模型结构(生成式或检索式)、参数规模、解码算法(贪心搜索、束搜索或采样)、解码约束条件(长度与重复限制)。最终发现,生成式模型结合束搜索加以恰当的解码约束条件可以取得最佳的对话效果,并且模型性能随着参数量增加而提升(但2.7B和9.4B差距较小)。
第二代 BlenderBot 发布于 2021 年,它包含两个参数规模的预训练模型:400M 和 2.7B。BlenderBot 2继承了第一代模型的结构和全部能力,并增加了长时记忆[29] 与互联网搜索[12] 的能力,他们均基于检索增强[14] 的技术实现。在长轮次对话中,对话历史通常受限于模型输入长度限制而被截断,这使得模型无法处理较长的对话历史,产生遗忘的现象。BlenderBot 2的长时记忆模块通过将对话历史进行信息提取与总结、储存在记忆单元中,在回复生成的过程中融合记忆单元的信息,使得模型具备了记忆较长对话历史的能力。此外,由于训练语料具有时效性,模型在训练完毕之后,无法再获取动态变化的世界知识与信息。BlenderBot 2的互联网搜索模块通过调用公开可用的搜索引擎API,使得模型具备了利用即时更新的世界信息展开对话的能力。
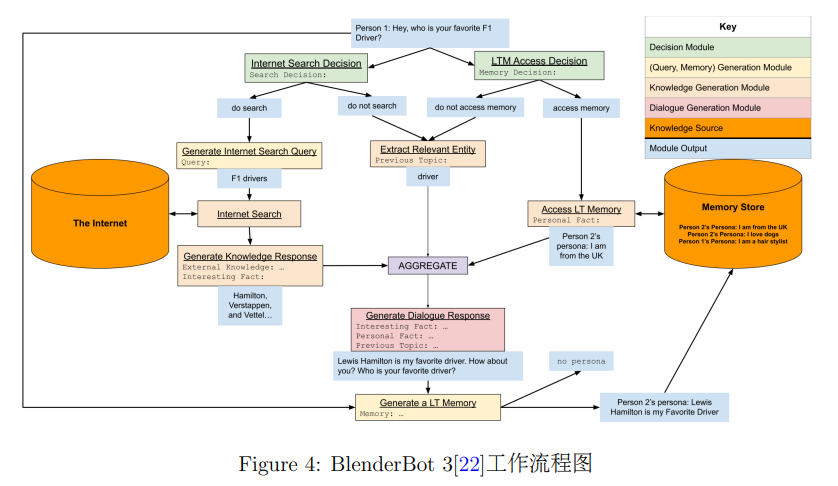
第三代BlenderBot发布于2022年,它包含三个参数规模的预训练模型:2.7B, 30B和175B,其中,2.7B 的版本为编码器-解码器结构,30B和175B的版本为单向解码器结构(由通用语言模型OPT[32] 的对应版本进行初始化)。相比起前两代BlenderBot,BlenderBot 3的核心差别在于:(1) 采用通用语言模型OPT为基座模型,并将参数规模提升至 175B;(2) 采用模块化的生成流程(如图4所示,包括检索决策、检索查询语句生成、知识性回复生成、长时记忆决策、长时记忆的读取与写入、实体抽取、回复整合等),并使用更大规模、更多样的人工构建语料进行针对性的微调;(3) 在开放领域闲聊的基础上,进一步拓展了以对话为载体的开放领域下的任务完成能力[30](例如查询信息等);(4) 侧重于模型的终身学习能力,结合BlenderBot 3演示系统的UI设计,系统能够持续收集用户反馈,并基于用户反馈不断提升。截至2022年,BlenderBot 3是性能最好的开源英文对话模型。
2.3 LaMDA (Google)
LaMDA模型由谷歌(Google)研发,于2022年发布 [25] 。
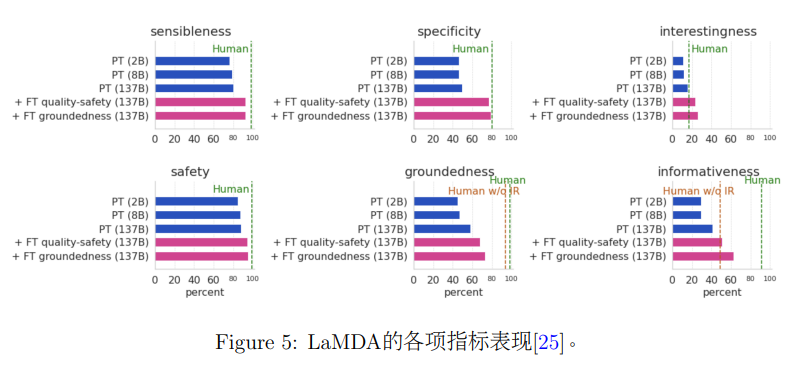
LaMDA模型的全称是Language Models for Dialog Applications,即将语言模型用于对话应用。在架构方面,LaMDA采用的是decoder-only的Transformer架构 [26] ,但将注意力替换成了和T5 [17] 一样的相对注意力的形式。LaMDA有3个不同参数量的版本,分别是2B,8B和137B。在预训练数据的选择方面,LaMDA综合使用了通用的文本数据和对话语料,使得其在通用语言建模和对话任务上都具备一定的能力,这也和它的全称“将语言模型用于对话应用”相对应。预训练的任务和标准的自回归语言模型一致,即最大化序列的生成概率。LaMDA强调了3个重要的评价维度,即质量(合理性,具体性,趣味性)、安全性和有根性。
为了提升模型生成回复的质量和安全性,作者团队让人和经过预训练的LaMDA进行多轮交互,并对LaMDA每一轮的回复给出相应维度的打分。这批有标注的数据会给预训练之后的LaMDA进行微调。值得注意的是,在进行微调时,模型不仅要生成回复,还需要学习人对于回复在各个维度的打分(也通过生成的方式来生成维度和对应的分数),这样模型就同时还具备了对回复进行评价的能力。作者团队随后利用微调后的LaMDA对预训练数据进行了筛选,得到了一批各维度打分较高的对话,再进一步在这些数据上微调LaMDA。LaMDA能够进行评价的另一个好处是能够在推理时生成多个回复,然后根据模型的自我评价筛选出各维度表现较好的回复。作者在文中的实验表明上述的做法显著地提升了模型在生成质量和安全性上的表现。
为了提升模型生成回复的有根性(即是否有根据,是否符合事实),LaMDA引入了一个工具包来辅助模型。这个工具包当中包括一个计算器、一个翻译器、以及一个信息检索系统,在给定合适的查询(例如询问某人的年龄)时,该工具包会返回实时查询或计算的结果。为了将这个工具包结合到LaMDA模型中,作者提出了两个微调任务:
● 根据对话历史和模型初步产生的回复生成需要输入给工具包的查询语句。
● 根据对话历史、模型初步回复、查询语句、工具包返回的结果生成最终的回复或者进一步输入给工具包的查询语句。
这两个任务的训练数据同样通过人工标注获得。
作者的实验主要对比了不同参数量的LaMDA,是否经过微调的LaMDA以及人类在合理性、具体性、趣味性、安全性、有根性、信息量这几个维度上的表现,结果如图5所示。从结果来看,增大模型参数量和额外进行微调都能明显提升模型的性能。和人类相比,LaMDA在合理性、具体性、安全性这几个维度上都能接近人类水平,在趣味性上甚至超过了人类水平,但是在有根性和信息量这两个维度上还是明显低于人类水平,表明即使是这种超大模型,在获取和利用知识的层面依然有较大的进步空间。
2.4 PLATO (百度)
PLATO由百度研发,由2019年底发布第一个版本开始,截至2022年底,已经历经四个版本,分别是PLATO-1[2],PLATO-2[3],PLATO-XL[4]和PLATO-K[5]。从PLATO-1开始,PLATO一直使用的是UniLM[9]的模型架构,以灵活地结合双向的上下文理解和单向的回复生成,该架构也被沿用到后续所有的PLATO版本中。
PLATO-1[2]发布于2019年末,彼时的文本预训练语言模型正呈现出惊人的实力,设计预训练任务一度成为最大的研究热点。而PLATO-1则在对话回复任务上提出了更适配的预训练方法。在对话回复预训练任务中,PLATO-1引入了离散隐变量加入到模型输入中,以建模在开放域对话中上下文和回复一对多的关系,并使用了Bag-of-Words (BOW)损失。另外,PLATO-1还引入了对话回复选择损失,以增强对话回复对上下文的相关性。最后,PLATO-1还首次使用了角色嵌入向量以使模型区分对话中的角色。
PLATO-2[3]发布于2020年,彼时研究者们已经逐渐发现加大训练数据和模型参数规模会使语言模型发生质的改变。PLATO-2使用了课程学习的训练方法以拓展PLATO-1的规模。在课程学习的第一阶段中,PLATO-2使用常规的一对一的上下文回复训练方式,在第二阶段中,PLATO-2使用了类似PLATO-1中的训练方式,以建模多样且相关的对话回复。PLATO-2发布了多个模型参数版本,包括93M,314M,和最大的1.6B。值得一提的是,PLATO-2还发布了336M参数规模的中文模型。在实验中,英文PLATO-2在自动指标和人工评估上均超过了BlenderBot[20],中文PLATO-2也大幅超过微软发布的小冰(XiaoIce[34])。
PLATO-XL[4]发布于2021年,PLATO的参数规模在这一版本中进一步增加,中英文均达到11B。PLATO-XL主体上采用了和PLATO-2相同的训练方式,额外引入了三方对话的数据。在三方对话中,可以超过两人参与对话,该对话方式也更加符合目前主流社交媒体的发帖回帖方式。PLATO-XL延续PLATO-1使用角色嵌入向量以区分多个对话中的角色。在人工评测中,PLATO-XL在多项指标中(如连贯性、一致性、信息性等)均为最佳。
PLATO-K[5]发布于2022年,其中的K指知识(Knowledge),PLATO-K旨在解决在开放域对话中信息缺乏和事实不准确的知识问题。PLATO-K进行了两阶段的训练,在第一阶段中常规地通过学习大量的对话数据以形成模型的内在知识,在第二阶段中,PLATO-K基于上下文训练生成一个查询(Query),并基于该查询搜索外部信息,模仿人类进行知识搜索,最后将搜索到的外部知识加入到上下文中进行对话回复生成。另外,PLATO-K进一步拓展模型到了22B参数规模。在实验中,PLATO-K在各项指标,尤其是知识性上优于PLATO-XL。
2.5 CDial-GPT (清华大学)
CDial-GPT[27]是由清华大学交互式人工智能课题组(CoAI)发布,是首个开源的大规模中文对话预训练模型。
在2020年前,虽然基于神经网络的对话系统已在英文领域取得了进展,但受限于中文对话数据的缺失,中文对话系统的性能依然无法令人满意。为此,该工作首先构建了大规模高质量对话数据集LCCC(Large-scale Cleaned Chinese Conversation),该数据集从多个公开的中文数据源(包括社交平台、字幕等)爬取数据,采用规则和分类器相结合的严格过滤流程。具体而言,规则主要去除了数据中含有的非对话内容(如平台特定的标识符、网址、广告、图片或视频的介绍等)和不安全行为(如脏话、敏感词等)。分类器过滤流程包含两个基于BERT[7]的分类器,第一个分类器在100,000条人工标注的对话数据上训练,用于去除包含回复不通顺、回复与对话上下文不相关等问题的噪声数据;第二个分类器在10,000条人工标注的对话数据上训练,用于过滤依赖外部信息且本身难以理解的对话数据。LCCC数据集包含LCCC-base和LCCC-large两个版本。其中LCCC-base包含约6.8M个中文对话数据,LCCC-large则包含约12M个中文对话数据,两个版本的区别在于LCCC-large的数据源更加丰富,所以数据的数量和多样性更高。然后在该数据集的基础上训练了开源的中文对话预训练模型CDial-GPT,该模型将所有对话历史拼接为一个句子作为输入,同时在模型的输入层添加了说话人的嵌入向量以区分对话历史中不同说话者的行为。CDial-GPT具有和GPT[16]相同的单向解码器结构,参数量为104M。和基于Transformer的非预训练对话模型以及在中文小说语料上训练的通用语言模型相比,CDial-GPT生成回复的自动指标显著(如Perplexity、BLEU、Distinct-n等)均优于基线模型。同时,在人工评价中,CDial-GPT的流畅性、相关性和信息量也显著优于基线模型。受益于高质量中文对话数据和大规模预训练模型,CDial-GPT还能在多轮人机交互能力和自闲聊(Self-Chatting)能力上都比之前的模型有显著提升。
作为首个开源的大规模中文对话数据集和预训练模型,CDial-GPT为后续中文对话大模型的发展奠定了基础。同时,LCCC数据集作为开源的中文对话数据集也在一定程度上弥补了中文对话数据集缺失的遗憾,后续研究工作也将其作为中文对话系统领域的标准评测集来评测对话模型的生成效果。
2.6 EVA (清华大学)
EVA 系列模型是由北京人工智能研究院和清华大学交互式人工智能课题组(CoAI)共同研发的中文对话模型,包含EVA1.0[33]和EVA2.0[11]两个版本。
EVA1.0模型发布于2021年,在发布时是当时最大的中文开放域对话模型,拥有28亿参数,在 181GB 的 WDC-Dialog[33]语料上训练而成。EVA1.0采用编码器-解码器结构,编码器输入对话上文,解码器输出回复。为了提升训练效率,EVA1.0使用了对话拼接,用较短的对话填满语言模型的输入,从而充分利用输入的最大长度,并且结合了ZERO-1[18]算法和混合精度训练。
在自动指标评测上,EVA1.0模型在单轮回复、多轮回复、长回复、问答回复四个方面的上下文相关性显著超越其他中文对话模型。人工指标的评测上,EVA1.0模型也普遍更受人类用户的偏好。
EVA2.0模型发布于2022年,拥有28亿、9亿和3亿三个模型参数的版本。其中,28亿参数的模型和 EVA1.0的参数量持平,并且仍然是发布时最大的开源中文对话模型。EVA2.0仍为编码器-解码器结构,并且在 EVA1.0模型的基础上从以下几个方面进一步提升了性能:(1)在数据处理方面,EVA2.0使用的训练数据经过了更加严格的过滤。数据主体由 WDC-Dialog构成,并且加入了更多数据源。经过数据集层面、上下文层面、规则层面和基于分类器的过滤,EVA2.0最终的训练数据为60G,虽然数据量相比WDC-Dialog减少,但是数据的上下文相关性、领域多样性明显提升。(2)在模型结构方面,EVA2.0为注意力机制加入了一个缩放因子,从而提升了模型训练的稳定性。同时,研究者还尝试了多种模型结构的变体,例如不同的编码器-解码器层数配比、是否引入对话角色编码等,并选择了最优的模型结构。(3)在训练方式方面,EVA2.0模型尝试了两种训练方式:从零开始预训练以及基于语言模型预训练。实验中发现,虽然基于语言模型的预训练可以继承较好的知识性,但是其闲聊能力会有所下降。因此EVA2.0最终从零预训练而成。(4)在解码方式上面,研究者也探究了不同的策略,例如波束搜索、长度和重复的惩罚、采样方式等等,尤其聚焦于中文模型的解码和英文模型的不同之处。最终,EVA2.0采用了带重复和长度惩罚的波束搜索与随机采样结合的解码方式。
自动指标的评测中,EVA2.0模型的单轮、多轮回复能力在相关性、多样性方面都显著超越了其他开源的中文对话模型。其中,3亿的EVA2.0模型就已经能达到和28亿的EVA1.0模型相似的效果。这充分说明了 EVA2.0 模型一系列优化的有效性。人工评测中,EVA2.0生成的回复也被认为更具有信息量和上下文相关性。同时,如果让模型自己和自己进行对话,EVA2.0所生成的对话段落也更加受到人类的偏好。在汇报模型性能之外,EVA2.0的研究者也分析了当前模型的一些问题,例如上下文一致性、知识性、回复的安全性和模型的共情能力,并指出了未来中文对话系统的研究方向。

2.7 OPD (清华大学)
Open-Domain Pre-trained Dialogue Model (OPD) 是清华大学交互式人工智能课题组(CoAI)继CDial-GPT和EVA之后研发的最新中文对话模型,于2022年11月发布。
OPD采用了UniLM[9]架构,共包含63亿参数,是目前最大的中文开放域对话模型。为保证OPD在多轮对话上具有较好的性能,我们将模型的最大截断长度设为512。考虑到OPD模型规模较大,我们尤其重视OPD在下游数据上参数高效微调的能力,因此我们在预训练阶段引入了soft prompt。在EVA的研发过程中,我们发现相比于通用预训练语言模型,对话预训练模型对于数据的质量更加敏感,对于数据清洗有更加严格的要求。因此,我们设计了严格、全面的数据清洗流程,对爬取的大规模原始对话数据进行清洗。最终,我们得到了70GB高质量对话数据用于OPD的预训练,数据留存率约10%。
在实验上,OPD不仅与开源中文对话模型(CDial-GPT[27], EVA[11])进行了对比,也与闭源中文对话模型(PLATO[3], PANGU-BOT[15])进行了对比。在自动指标评测实验中,OPD在BLEU-4和F1等自动指标上均能达到现有中文对话模型的最优性能,同时OPD在多样性指标Distinct-3/4上也能达到与PLATO相近的性能。在人工静态评测实验中,OPD在回复的具体性表现上尤其突出,显著超越了所有基线模型达到最优性能,并在一致性和相关性上也能与最优的基线模型达到相似的性能。OPD还进行了配对的静态人工评测实验,针对相同的对话输入,由OPD和基线模型分别生成回复,由标注者选择总体质量更高的回复。实验结果显示,OPD在配对人工评测中能够优于所有基线模型。为了进一步评测对话模型的能力,OPD在更具有挑战性的多轮交互情境下进行了人工评测。与静态人工评测实验的结果相似,OPD在具体性和总体质量上显著超过了所有基线模型,在一致性和相关性上与最优的基线模型表现相近。最后,在知识性上,OPD达到了与PANGU-BOT相近的性能,显著优于EVA2.0和PLATO。
总体而言,OPD兼顾出色的闲聊能力与知识问答能力。得益于此,OPD的多轮交互能力尤其突出,能够与用户进行多轮、深入的对话交互。在汇报模型性能之外,OPD的研究者也指出了一些未来的研发方向,例如从人类反馈中学习,以及下游技能(情感安抚、知识检索)的学习。
2.8 Character.AI / InWorld.AI
人格化对话机器人也在最近取得了长足的进步,人格化对话与开放域闲聊不同,不仅要求模型利用给定的知识和个人信息,更要能够模仿出特定人物的风格,这在之前的对话场景中是不常出现的。目前有很多公司开始尝试突破人格化对话的技术,如Character.AI、InWorld.AI等,允许用户给定角色的相关信息和示例对话,模型能够利用这些信息生成带有人物信息和风格的对话。目前Character.AI网站上已经有上百个角色以及过亿次的对话交互,引起了学术界和工业界的关注。
2.9 ChatGPT (OpenAI)
ChatGPT模型由OpenAI研发,与2022年11月发布。ChatGPT基于GPT-3.5系列模型,采用了和InstructGPT类似的方法,通过从人类反馈中进行强化学习(Reinforcement Learning from Human Feedback, RLHF)图7的方法进行微调,OpenAI之前已经在文本摘要和通用语言模型领域验证了RLHF的有效性,ChatGPT的出现证明了RLHF在对话领域也能够发挥很大的作用。首先收集人工编写的用户和AI助手交互的对话数据,基于这些数据对模型进行监督学习训练。然后让训练好的模型与人类对话,生成多个候选答案,让人工标注者对答案进行排序,并基于排序数据训练奖励函数。通过训练得到的奖励函数,可以采用强化学习的方法进一步更新模型的参数。
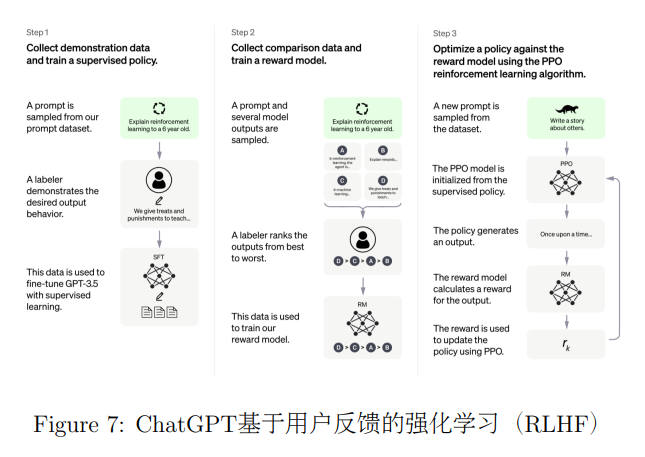
该模型能够回答用户的问题、承认自己的错误、质疑错误的前提以及拒绝用户不适当的请求,在AI安全和落地方面迈出了一大步(如图8所示)。与之前的GPT-3和Code-x对比,生成有害信息和虚假信息的比例大幅缩小。ChatGPT与之前的开放域闲聊对话不同,该模型的定位是智能助手,是一个开放领域的任务型对话系统,因其强大的对话能力受到了各领域研究者和从业者的广泛关注。

3 总结与未来工作
本报告对当前典型的大规模神经对话系统进行了简要介绍。随着模型规模和数据规模的快速提升,大规模神经对话系统在交互能力上进步迅速,成为了人工智能领域中的研究前沿和产业热点。可以预见,未来对话系统将突破现有研究的限制,不再严格区分种类(如闲聊式和任务式、检索式和生成式等),朝着人格化、专业化的综合智能助手不断发展。大规模预训练技术也将逐渐成为当代对话系统中的核心技术,助力提升对话系统的性能。
References
[1] Daniel Adiwardana, Minh-Thang Luong, David R So, Jamie Hall, Noah Fiedel, Romal Thoppilan, Zi Yang, Apoorv Kulshreshtha, Gaurav Nemade, Yifeng Lu, et al. Towards a human-like open-domain chatbot. arXiv preprint arXiv:2001.09977, 2020.
[2] Siqi Bao, Huang He, Fan Wang, Hua Wu, and Haifeng Wang. PLATO: Pre-trained dialogue generation model with discrete latent variable. In ACL, pages 85-96, 2020.
[3] Siqi Bao, Huang He, Fan Wang, Hua Wu, Haifeng Wang, Wenquan Wu, Zhen Guo, Zhibin Liu, and Xinchao Xu. PLATO-2: Towards building an open-domain chatbot via curriculum learning. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 2513-2525, Online, August 2021. Association for Computational Linguistics.
[4] Siqi Bao, Huang He, Fan Wang, Hua Wu, Haifeng Wang, Wenquan Wu, Zhihua Wu, Zhen Guo, Hua Lu, Xinxian Huang, Xin Tian, Xinchao Xu, Yingzhan Lin, and Zheng-Yu Niu. PLATO-XL: Exploring the large-scale pre-training of dialogue generation. In Findings of the Association for Computational Linguistics: AACL-IJCNLP 2022, pages 107-118, Online only, November 2022. Association for Computational Linguistics.
[5] Siqi Bao, Huang He, Jun Xu, Hua Lu, Fan Wang, Hua Wu, Han Zhou, Wenquan Wu, Zheng-Yu Niu, and Haifeng Wang. Plato-k: Internal and external knowledge enhanced dialogue generation. arXiv preprint arXiv:2211.00910, 2022.
[6] Jason Baumgartner, Savvas Zannettou, Brian Keegan, Megan Squire, and Jeremy Blackburn. The pushshift reddit dataset. In AAAI, 2020.
[7] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In NAACL, pages 4171-4186, 2019.
[8] Emily Dinan, Stephen Roller, Kurt Shuster, Angela Fan, Michael Auli, and Jason Weston. Wizard of wikipedia: Knowledge-powered conversational agents. In ICLR, 2018.
[9] Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, and Hsiao-Wuen Hon. Unied language model pre-training for natural language understanding and generation. CoRR, abs/1905.03197, 2019.
[10] Xiaodong Gu, Kang Min Yoo, and Jung-Woo Ha. Dialogbert: Discourse-aware response generation via learning to recover and rank utterances. In AAAI, pages 12911-12919, 2021.
[11] Yuxian Gu, Jiaxin Wen, Hao Sun, Yi Song, Pei Ke, Chujie Zheng, Zheng Zhang, Jianzhu Yao, Xiaoyan Zhu, Jie Tang, and Minlie Huang. EVA2.0: Investigating open-domain chinese dialogue systems with large-scale pre-training. arXiv preprint arXiv:2203.09313, 2022.
[12] Mojtaba Komeili, Kurt Shuster, and Jason Weston. Internet-augmented dialogue generation. In ACL, 2022.
[13] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. BART: denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In ACL, pages 7871-7880, 2020.
[14] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Kuttler, Mike Lewis, Wen-tau Yih, Tim Rocktaschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. NeurIPS, 2020.
[15] Fei Mi, Yitong Li, Yulong Zeng, Jingyan Zhou, Yasheng Wang, Chuanfei Xu, Lifeng Shang, Xin Jiang, Shiqi Zhao, and Qun Liu. Pangubot: Ecient generative dialogue pre-training from pre-trained language model. arXiv preprint arXiv:2203. 17090, 2022.
[16] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. OpenAI Blog, 2018.
[17] Colin Rael, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J Liu, et al. Exploring the limits of transfer learning with a unied text-to-text transformer. J. Mach. Learn. Res., 21(140):1-67, 2020.
[18] Samyam Rajbhandari, Je Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC '20, 2020.
[19] Hannah Rashkin, Eric Michael Smith, Margaret Li, and Y-Lan Boureau. Towards empathetic open-domain conversation models: A new benchmark and dataset. In ACL, 2019.
[20] Stephen Roller, Emily Dinan, Naman Goyal, Da Ju, Mary Williamson, Yinhan Liu, Jing Xu, Myle Ott, Eric Michael Smith, Y-Lan Boureau, and Jason Weston. Recipes for building an open-domain chatbot. In EACL, 2021.
[21] Lifeng Shang, Zhengdong Lu, and Hang Li. Neural responding machine for short-text conversation. In ACL, pages 1577-1586, 2015.
[22] Kurt Shuster, Jing Xu, Mojtaba Komeili, Da Ju, Eric Michael Smith, Stephen Roller, Megan Ung, Moya Chen, Kushal Arora, Joshua Lane, et al. Blenderbot 3: a deployed conversational agent that continually learns to responsibly engage. arXiv preprint arXiv:2208.03188, 2022.
[23] Eric Michael Smith, Mary Williamson, Kurt Shuster, Jason Weston, and Y-Lan Boureau. Can you put it all together: Evaluating conversational agents' ability to blend skills. In ACL, 2020.
[24] David So, Quoc Le, and Chen Liang. The evolved transformer. In International Conference on Machine Learning, pages 5877-5886. PMLR, 2019.
[25] Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kul-shreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239, 2022.
[26] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in neural information processing systems, 2017.
[27] Yida Wang, Pei Ke, Yinhe Zheng, Kaili Huang, Yong Jiang, Xiaoyan Zhu, and Minlie Huang. A large-scale chinese short-text conversation dataset. In NLPCC, pages 91-103, 2020.
[28] Joseph Weizenbaum. ELIZA - a computer program for the study of natural language communication between man and machine. Commun. ACM, 9(1):36-45,1966.
[29] Jing Xu, Arthur Szlam, and Jason Weston. Beyond goldsh memory: Long-term open-domain conversation. In ACL, May 2022.
[30] Jing Xu, Megan Ung, Mojtaba Komeili, Kushal Arora, Y-Lan Boureau, and Jason Weston. Learning new skills after deployment: Improving open-domain internet- driven dialogue with human feedback. arXiv preprint arXiv:2208.03270, 2022.
[31] Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, and Jason Weston. Personalizing dialogue agents: I have a dog, do you have pets too? In ACL, 2018.
[32] Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.
[33] Hao Zhou, Pei Ke, Zheng Zhang, Yuxian Gu, Yinhe Zheng, Chujie Zheng, Yida Wang, Chen Henry Wu, Hao Sun, Xiaocong Yang, Bosi Wen, Xiaoyan Zhu, Minlie Huang, and Jie Tang. EVA: An open-domain chinese dialogue system with large- scale generative pre-training. arXiv preprint arXiv:2108.01547, 2021.
[34] Li Zhou, Jianfeng Gao, Di Li, and Heung-Yeung Shum. The design and imple-mentation of XiaoIce, an empathetic social chatbot. Computational Linguistics, 46(1):53-93, 2020.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢