
作者王思若,本文转自夕小瑶的卖萌屋
从20年开始,“最大语言模型”的桂冠被各大研究机构和科技公司竞相追逐,堆砌参数,猛上算力,开启了“大炼丹”时代,模型参数量仿佛越大越好,甚至GPT-4模型参数量将超过100万亿的传闻甚嚣尘上。
当把视角落在今年下半年,大模型的“军备竞赛”似乎戛然而止,22年4月,Google发布了5400亿参数的PaLM荣登“大模型”榜首,然而到现在,似乎也没有出现更大规模的模型。在所有人热情和兴奋消退的背后,其实是盲目跟风追求大模型之后的“一地鸡毛”,改改框架,换换数据,加大参数量,这种万能的公式似乎不太奏效了,更大的模型似乎也只是产生了渐进式的进步。
问题出在了哪里?DeepMind在模型投入产出比角度进行了分析,研究表明,目前大多数大型语言模型训练不足,GPT-3、Gopher、Megatron-Turing NLG等一众大模型在成倍增大参数规模的时候,并没有成比例的增加训练数据,导致并没有完全实现大模型的最大功效,研究工作发表在NeurIPS2022并获得了Outstanding Paper。
论文题目:
Training Compute-Optimal Large Language Models
论文链接:
https://arxiv.org/pdf/2203.15556.pdf
重新定义缩放法则(Scaling Laws)
在大模型训练时,有三个及其重要的考量,分别是:计算量,模型参数规模以及数据集大小。早在2020年,OpenAI对其进行了探讨并提出了缩放法则(Scaling Laws),训练最佳计算效率的模型需要在相对适中的数据量上训练非常大的模型并在收敛之前early stopping,简单来说,模型参数规模几乎就是一切![1]
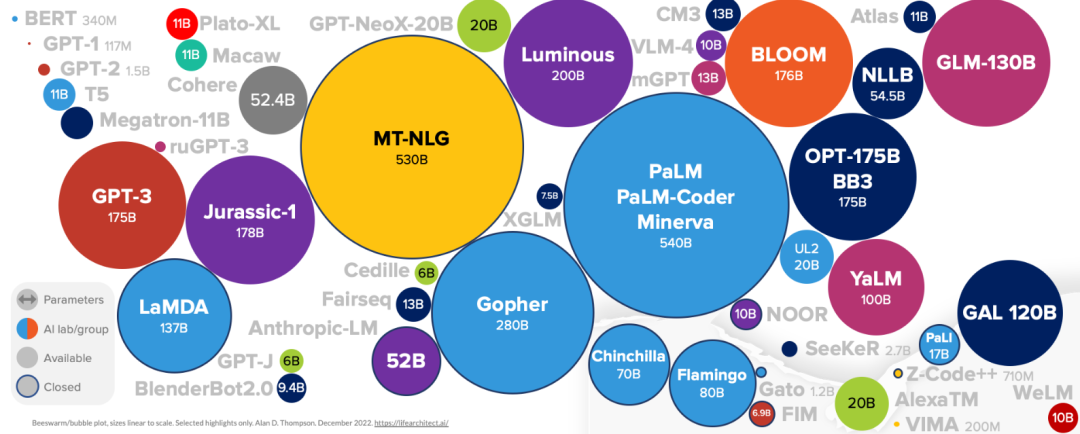
上图所示,给定计算量,模型性能的提升主要在于增加参数规模,例如,计算量增加10倍,模型规模要增加5倍,训练数据增加2倍;计算量增加100倍,模型规模增加10倍,训练数据仅增加4倍即可。
这给了后续工作足够的动力去专注于提升参数规模,设计越来越大的模型,而不是在更多的数据上训练较小的模型,由此,模型“大炼丹”时代开启,从NLP,CV再到AI4Science,大规模语言模型俨然成为了AI社区的主流研究方向。
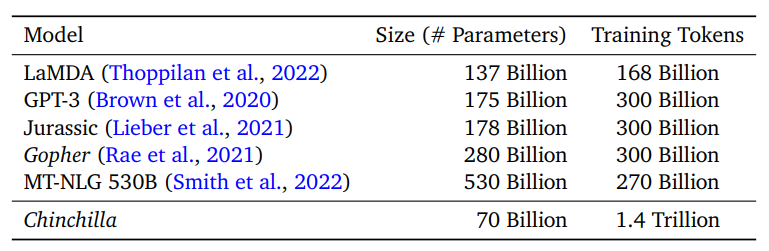
然而,DeepMind证伪了OpenAI的大模型缩放法则,重现定义了最优模型训练的参数规模和训练数据量之间的关系,再此基础上训练了最优的语言模型Chinchilla,实现了700亿参数量性能超越5300亿参数量的MT-NLG。
大规模语言模型受到不同因素的影响,其中,模型性能强烈依赖于参数规模N,数据集大小D和计算量C,DeepMind研究人员围绕这样的问题进行了探索:在给定计算量(FLOPs,即每秒浮点运算次数)时,如何权衡模型参数规模和训练数据集大小?
我们从两个角度进行分析:
1. 固定模型参数规模
研究人员构造了从70M到10B不同参数规模的模型,每个模型都在4种不同规模大小的训练数据集上进行训练。随着模型训练步数的增加(计算量FLOPs从增加到),训练loss逐渐降低(左图)。从所有训练曲线中,观察固定计算量的前提下训练loss最低的模型曲线,进而,我们可以画出不同计算量下最优模型的参数规模(中间图)和训练数据量(右图)。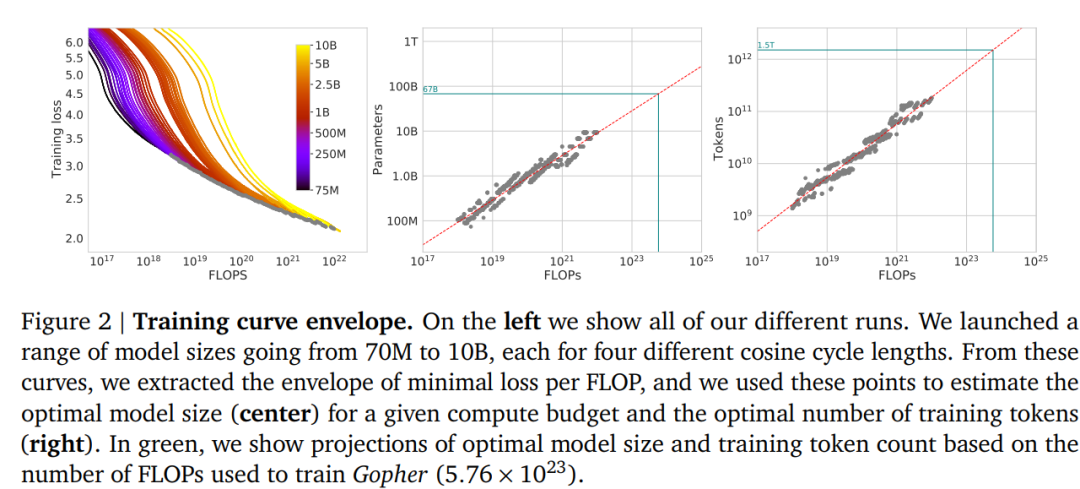
由此,我们可以获得给定计算量,最佳计算效率的模型参数规模、训练数据集大小,其中和值都是0.5。由此,模型训练时,训练数据集要随着模型参数规模的增加而同等扩增。
2. 固定计算量
在给定计算量的前提下,可以看到参数规模和训练数据更加直观的关系,对于到 9种不同规模的计算量(右图),每条曲线反应了不同参数规模的模型在给定计算量下的训练loss,在每条曲线最小值的左侧,模型规模太小了——在较少数据下训练较大模型将是一种改进;在每条曲线最小值的右侧,模型规模太大了——在较多数据下训练较小模型将是一种改进,计算效率最优的模型位于曲线最小值处。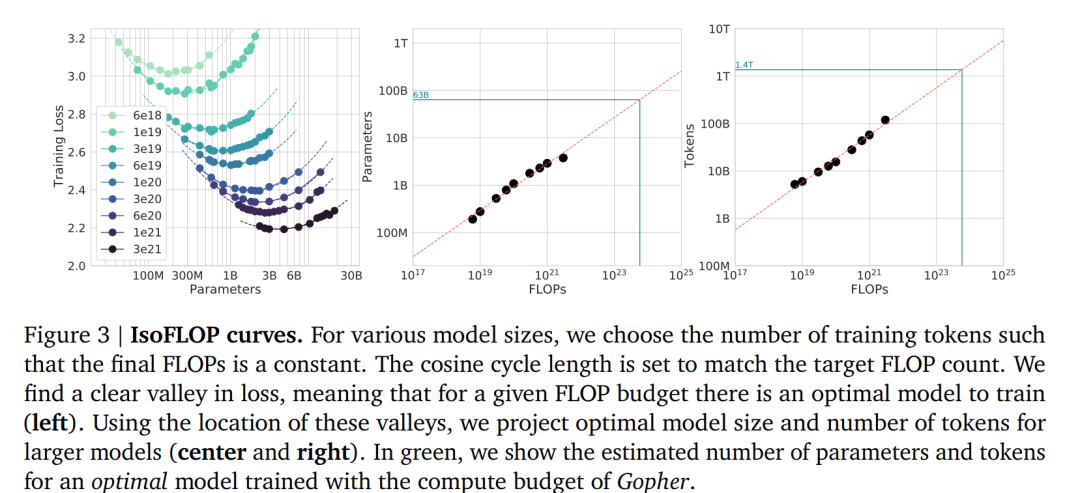
如果把每条曲线的最小值连接起来,你其实就会发现大模型全新的缩放法则,即模型规模增加一倍,训练数据集也应同样加倍(中间图和右图所示),模型训练时,数据规模和参数量同等重要。
为了进一步验证该定律,DeepMind使用与2800 亿参数的 Gopher 相同的计算量,训练了仅700亿参数的模型Chinchilla,参数规模缩减到1/4的同时,训练数据增加了4倍。
通过将Chinchilla和其他大模型在问答能力、常识、阅读理解和大型多任务语言理解能力基准数据集上进行比较,Chinchilla的评测结果都显著优于Gopher,甚至比参数规模是其7.6倍的MT-NLG性能都优越,稳坐大模型性能排行的第二把交椅(第一是目前参数规模最大的模型PaLM)。
结语
DeepMind通过实证分析为业内盲目扩增模型参数规模的现状敲响了警钟,在您拥有 200 倍于Chinchilla 所使用的计算量之前,您不会需要构造万亿参数量的大模型。在过去的道路里,大型语言模型的大小每年都在增长 10 倍[2],慢慢的大家开始认识到继续这条道理会导致收益递减、成本增加同时伴随着新的风险,因此,未来的趋势将不再是海量数据+超大算力的暴力美学,超大模型的拥趸们不用在执着于参数规模,如何发掘大模型的全部潜能将成为新的聚焦点。
没有人知道未来通用人工智能(AGI)究竟会以何种方式达到,但值得确信的一点是绝不可能是通过堆砌参数实现,而过往的两年间,国内似乎有太多研究机构去争抢“最大规模模型”的称谓,他们不清楚单凭规模是否可以引导我们走向智能,他们同样不清楚之后要走向哪里。借用曹越在知乎的发言“希望各个领域的研究者,特别是相对比较senior的研究者们,真的花些时间去理解现在世界最前沿的研究进展到了什么阶段,多看一些墙内墙外的examples,甚至自己去试一试,努力去理解后GPT3时代语言模型的能力,这真的比再在自己的领域中固步自封重要太多了。[3]”
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢