
来自今天的爱可可AI前沿推介
[CV] 3DHumanGAN: Towards Photo-Realistic 3D-Aware Human Image Generation
Z Yang, S Li, W Wu, B Dai
[Shanghai AI Lab & SenseTime Research]
3DHumanGAN: 逼真3D人体图像生成研究
要点:
-
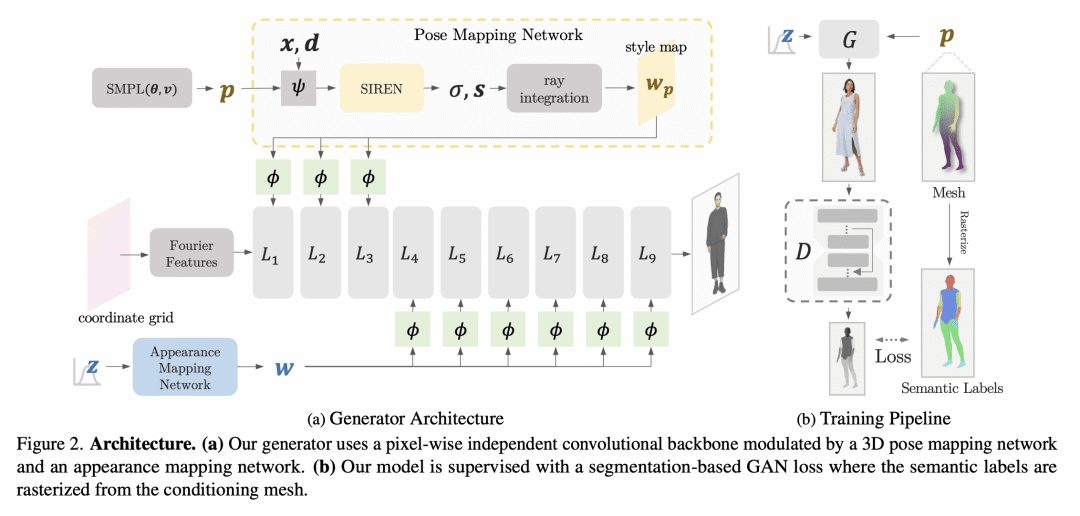
提出3DHumanGAN,一种3D感知生成对抗网络(GAN),用于合成逼真的全身人体图像; -
提出一种新的2D-3D混合生成器体系结构,既高效又富有表现力; -
采用基于分割的GAN损失进行监督,以建立3D坐标和2D人体语义之间的映射。
摘要:
本文提出3DHumanGAN,一种3D感知生成对抗网络(GAN),可以合成在不同视角和身体姿态的具有一致外观的人体全身图像。为解决合成人体铰接结构的表征和计算挑战,本文提出一个新的生成器架构,其中2D卷积主干被3D姿态映射网络所调制。3D姿势映射网络被表述为一个可渲染的隐函数,以摆好的3D人体网格为条件。这种设计有几个优点:i)允许利用2D GAN的能力来生成逼真的图像;ii)在不同的视角和可指定的姿态下生成一致的图像;iii)可以从3D人体先验中受益。所提出模型是通过对抗学习从网络图像集中获得的,不需要人工标注。
We present 3DHumanGAN, a 3D-aware generative adversarial network (GAN) that synthesizes images of full-body humans with consistent appearances under different view-angles and body-poses. To tackle the representational and computational challenges in synthesizing the articulated structure of human bodies, we propose a novel generator architecture in which a 2D convolutional backbone is modulated by a 3D pose mapping network. The 3D pose mapping network is formulated as a renderable implicit function conditioned on a posed 3D human mesh. This design has several merits: i) it allows us to harness the power of 2D GANs to generate photo-realistic images; ii) it generates consistent images under varying view-angles and specifiable poses; iii) the model can benefit from the 3D human prior. Our model is adversarially learned from a collection of web images needless of manual annotation.
论文链接:https://arxiv.org/abs/2212.07378


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢