
有很多文章已经详细介绍了各类生成模型,比如自回归模型Autoregressive Model (AR),生成对抗网络Generative Adversarial Network (GAN),标准化流模型Normalizing Flow (Flow),变分自编码器Variational Auto-Encoder (VAE),去噪扩散模型Denoising Diffusion Probablistic Model (Diffusion)等等。这篇文章不对各个模型做详细介绍,而是通过形象的比喻来解释比较各个生成模型。
生成模型的数据生成过程,可以看成是将一个先验分布的采样点Z变换成数据分布的采样点X的过程。下面这张图是网上流传得比较广的比较各个生成模型联系和区别的示意图(我重新画的),可以清楚地看到各个模型是如何将采样点Z映射到数据X的。
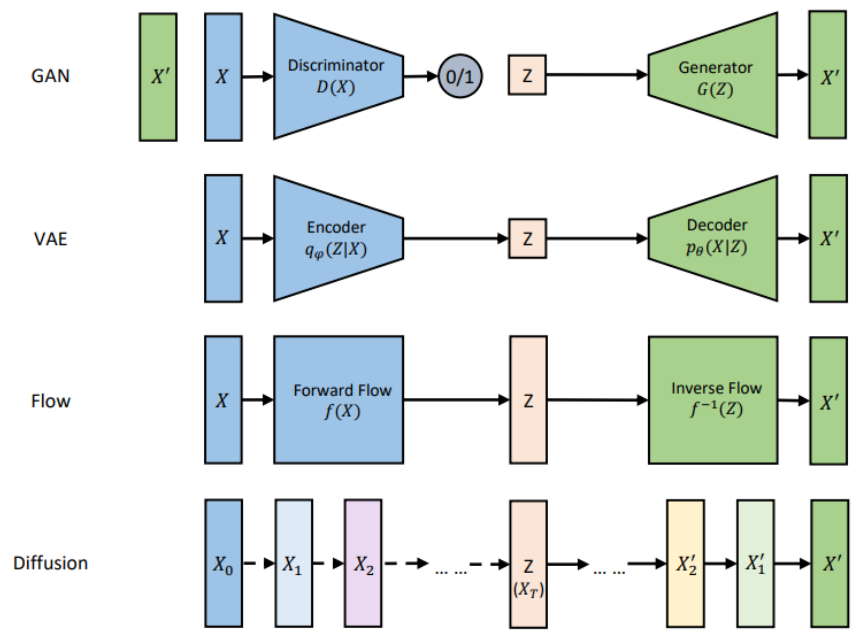
现在我们通过一个比喻来说明它们之间的区别。我们把数据的生成过程,也就是从Z映射到X的过程,比喻为过河。河的左岸是Z,右岸是X,过河就是乘船从左岸码头到达右岸码头。船可以理解为生成模型,码头的位置可以理解为样本点Z或者X在分布空间的位置。不同的生成模型有不同的过河的方法,如下图所示,我们分别来分析。
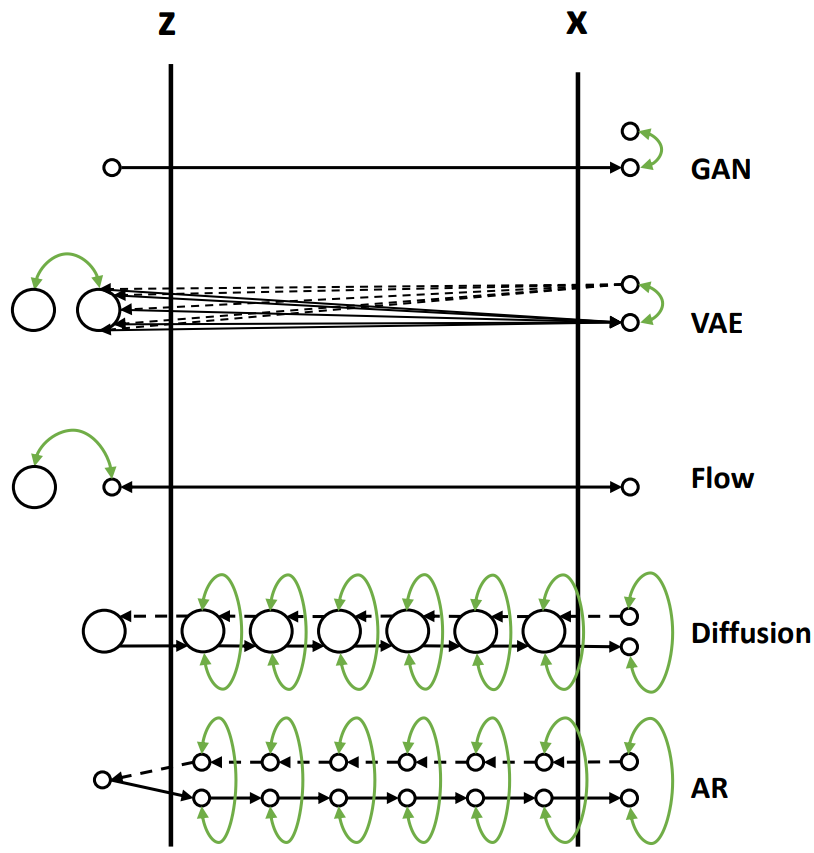
1. GAN的过河方式
从先验分布随机采样一个Z,也就是在左岸随便找一个码头,直接通过对抗损失的方式强制引导船开到右岸,要求右岸下船的码头和真实数据点在分布层面上比较接近。
2. VAE的过河方式
1)VAE在过河的时候,不是强制把河左岸的一个随机点拉到河右岸,而是考虑右岸的数据到达河左岸会落在什么样的码头。如果知道右岸数据到达左岸大概落在哪些码头,我们直接从这些码头出发就可以顺利回到右岸了。
2)由于VAE编码器的输出是一个高斯分布的均值和方差,一个右岸的样本数据X到达河左岸的码头位置不是一个固定点,而是一个高斯分布,这个高斯分布在训练时会和一个先验分布(一般是标准高斯分布)接近。
3)在数据生成时,从先验分布采样出来的Z也大概符合右岸过来的这几个码头位置,通过VAE解码器回到河右岸时,大概能到达真实数据分布所在的码头。
3. Flow的过河方式
1)Flow的过河方式和VAE有点类似,也是先看看河右岸数据到河左岸能落在哪些码头,在生成数据的时候从这些码头出发,就比较容易能到达河右岸。
2)和VAE不同的是,对于一个从河右岸码头出发的数据,通过Flow到达河左岸的码头是一个固定的位置,并不是一个分布。而且往返的船开着双程航线,来的时候从什么右岸码头到达左岸码头经过什么路线,回去的时候就从这个左岸码头经过这个路线到达这个右岸码头,是完全可逆的。
3)Flow需要约束数据到达河左岸码头的位置服从一个先验分布(一般是标准高斯分布),这样在数据生成的时候方便从先验分布里采样码头的位置,能比较好的到达河右岸。
4. Diffusion的过河方式
1)Diffusion也借鉴了类似VAE和Flow的过河思想,要想到达河右岸,先看看数据从河右岸去到左岸会在哪个码头下船,然后就从这个码头上船,准能到达河右岸的码头。
2)但是和Flow以及VAE不同的是,Diffusion不只看从右岸过来的时候在哪个码头下船,还看在河中央经过了哪些桥墩或者浮标点。这样从河左岸到河右岸的时候,也要一步一步打卡之前来时经过的这些浮标点,能更好约束往返的航线,确保到达河右岸的码头位置符合真实数据分布。
3)Diffusion从河右岸过来的航线不是可学习的,而是人工设计的,能保证到达河左岸的码头位置,虽然有些随机性,但是符合一个先验分布(一般是高斯分布),这样方便我们在生成数据的时候选择左岸出发的码头位置。
4)因为训练模型的时候要求我们一步步打卡来时经过的浮标,在生成数据的时候,基本上也能遵守这些潜在的浮标位置,一步步打卡到达右岸码头。
5)如果觉得开到河右岸一步步这样打卡浮标有点繁琐,影响船的行进速度,可以选择一次打卡跨好几个浮标,就能加速船行速度,这就对应diffusion的加速采样过程。
5. AR的过河方式
1)可以类比Diffusion模型,将AR生成过程 \( X_0, X_{0:1}, …, X_{0:t}, X_{0:t+1}, …, X_{0:T} \) 看成中间的一个个浮标。从河右岸到达河左岸的过程就好比自回归分解,将 \( X_{0:T} \) 一步步拆解成中间的浮标,这个过程也是不用学习的。
2)河左岸的码头 可以看成自回归生成的第一个START token。AR模型河左岸码头的位置是确定的,就是START token对应的embedding。
3)在训练过程中,自回归模型也一个个对齐了浮标,所以在生成的时候也能一步步打卡浮标去到河右岸。
4)和Diffusion不同的是,自回归模型要想加速,跳过某些浮标,就没有那么容易了,除非重新训练一个semi-autoregressive的模型,一次生成多个token跨过多个浮标。
5)和Diffusion类似的是,在训练过程中都使用了teacher-forcing的方式,以当前步的ground-truth浮标位置为出发点,预测下一个浮标位置,这也降低了学习的难度,所以通常来讲,自回归模型和Diffusion模型训练起来都比较容易。
希望通过这些类比分析能为大家提供一个理解生成模型更加形象的方式。如果要了解各个生成模型工作的原理,请查询相关的资料。同时,如果对生成模型在语音合成中的应用感兴趣,可以参考之前我做的一个Talk:
Deep Generative Models for Text-to-Speech Synthesis
https://www.microsoft.com/en-us/research/uploads/prod/2022/12/Generative-Models-for-TTS.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢