
Embedding(嵌入)是自然语言中的概念转变为数值表示的一种处理,用来测量文本字符串之间的相关度,在NLP中应用广泛。
据官方博客介绍,新模型 text-embedding-ada-002 统一替代了原来用于text-similarity, text-search-query, text-search-doc, code-search-text and code-search-code等任务的5个模型。
而且超越了此前最强的Davinci。
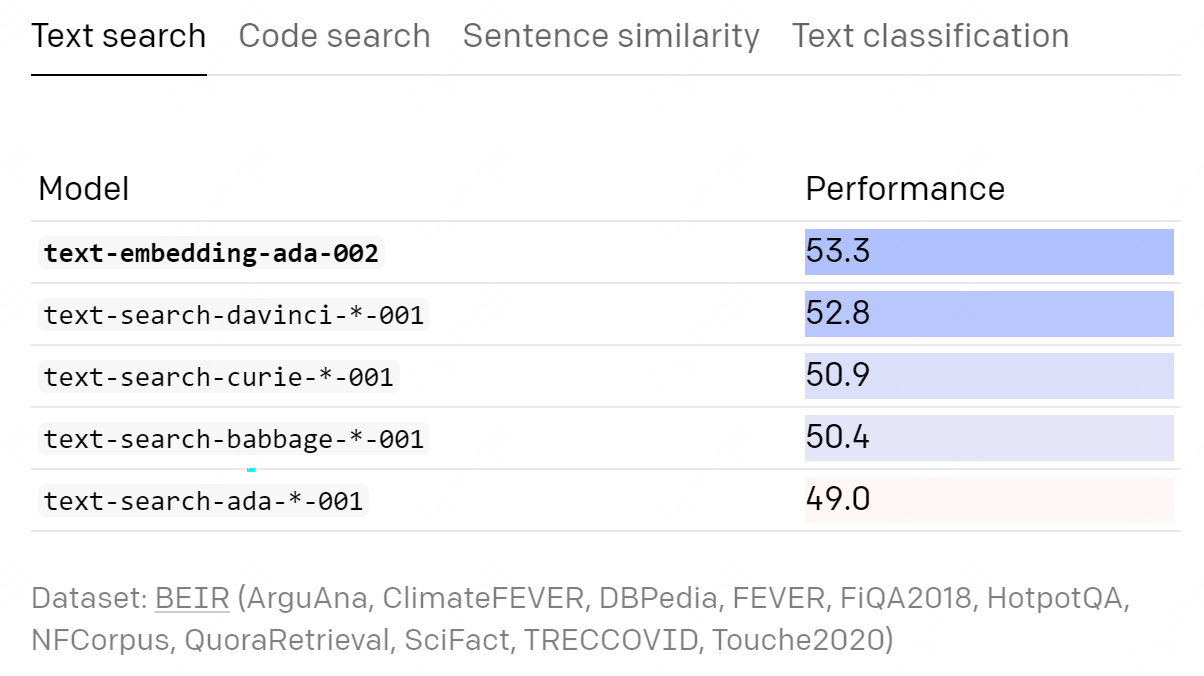
当然,这是一个收费服务,好消息是新版本价格降低了 99.8% 。现在的价格是1K token 0.04美分,少了1到两个数量级。

小的改进还有:
上下文更长。 增加了四倍,从 2048到 8192,处理长文档更方便。
更小的嵌入尺寸。 新模型只有 1536 维,是
davinci-001的八分之一,使用向量数据库时成本更低。
值得注意的是:
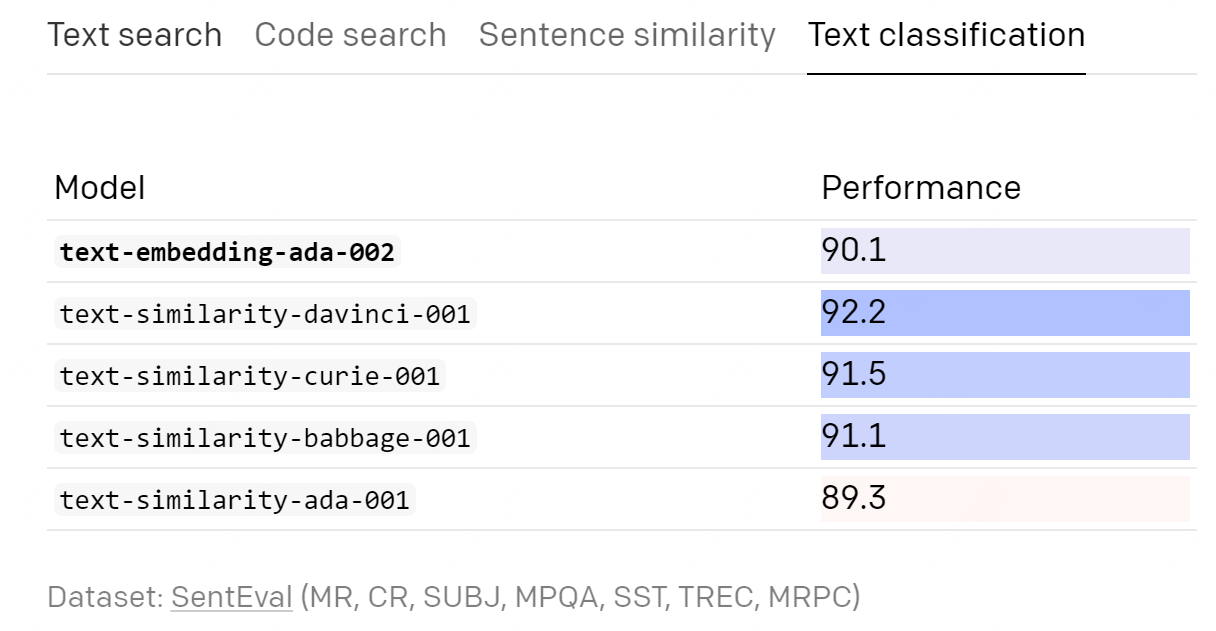
新的模型在 SentEval 线性探测分类基准上的表现没有超过原来的
text-similarity-davinci-001。 对于需要在嵌入向量之上训练轻量级线性层以进行分类预测的任务,我们建议将新模型与text-similarity-davinci-001进行比较。
博客中也提供了相应数据:
更多细节请访问文档: https://beta.openai.com/docs/guides/embeddings

项目负责人Ryan Greene(LinkedIn)是一位大学辍学生(Illinois州立2016级),他2019年加入Facebook工作了两年多,今年2月加盟OpenAI。他在Twitter上表示这是自己在OpenAI第一个公开的成果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢