
来自今天的爱可可AI前沿推介
[LG] Transformers learn in-context by gradient descent
J v Oswald, E Niklasson, E Randazzo, J Sacramento, A Mordvintsev, A Zhmoginov, M Vladymyro
[Google Research & ETH Zürich]
Transformer基于梯度下降的上下文学习
要点:
-
Transformers 可以仅凭少量样本进行上下文学习; -
Transformers 成为上下文学习器的机制可以与基于梯度的元学习配置屁且相关; -
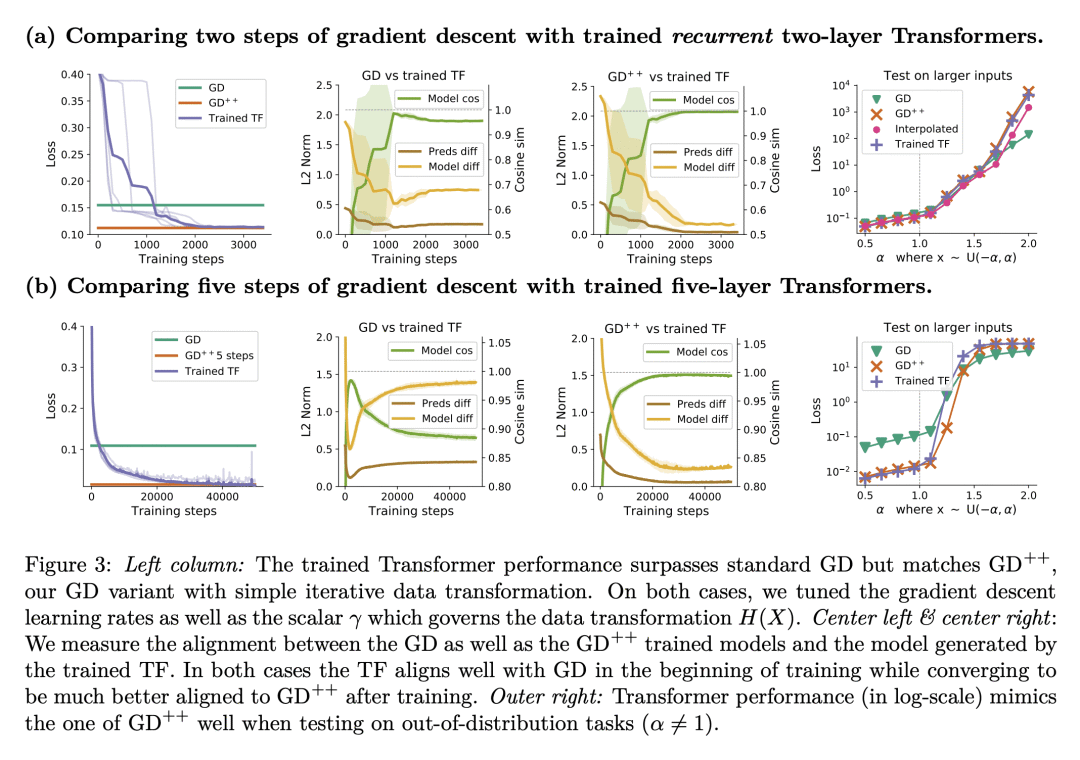
Transformers 通过迭代曲率校正超越常规梯度下降,并通过在深层表示上学习线性模型来解决非线性回归任务。
摘要:
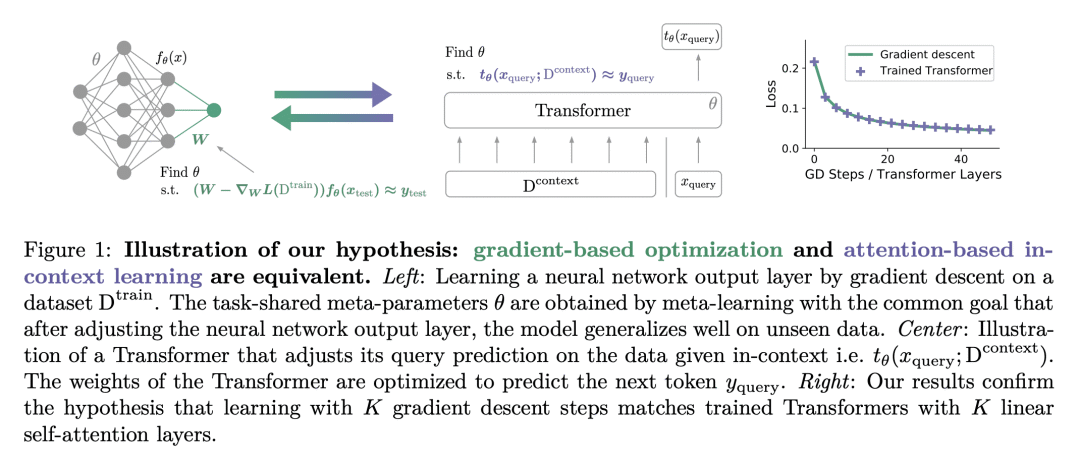
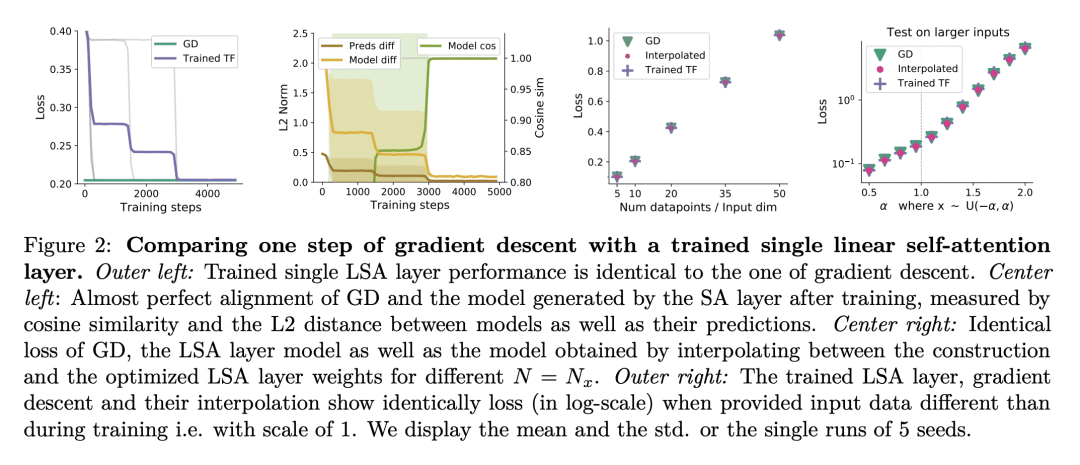
Transformer已经成为机器学习众多领域中最先进的神经网络架构。这部分是由于他们著名的迁移能力和基于少数样本的上下文学习能力。然而,Transformer成为上下文学习器的机制还没有被很好地理解,大部分仍然是一种直觉。本文认为在自回归任务上训练Transformer可以与著名的基于梯度的元学习公式密切相关。提供了一个简单的权重结构,显示了由 1) 单一线性自注意力层 和 2) 回归损失上的梯度下降(GD)引起的数据变换的等效性。在该结构的激励下,通过经验表明,当在简单的回归任务上训练仅有自注意力的Transformer时,由GD和Transformer学习的模型显示出极大的相似性,值得注意的是,通过优化找到的权重与该结构相匹配。本文展示了经过训练的Transformer是如何在其前向通道中实现梯度下降的。这使得至少在回归问题域,能机械地理解优化后的Transformer的内部运作。此外,本文确定了Transformer是如何通过迭代曲率修正超越普通的梯度下降,并在深度数据表示上学习线性模型来解决非线性回归任务。最后,讨论了与一种被认为对上下文学习至关重要的机制的有趣相似之处,这种机制被称为感应头,并展示了如何将其理解为Transformer内通过梯度下降进行上下文学习的一个具体案例。
Transformers have become the state-of-the-art neural network architecture across numerous domains of machine learning. This is partly due to their celebrated ability to transfer and to learn in-context based on few examples. Nevertheless, the mechanisms by which Transformers become in-context learners are not well understood and remain mostly an intuition. Here, we argue that training Transformers on auto-regressive tasks can be closely related to well-known gradient-based meta-learning formulations. We start by providing a simple weight construction that shows the equivalence of data transformations induced by 1) a single linear self-attention layer and by 2) gradient-descent (GD) on a regression loss. Motivated by that construction, we show empirically that when training self-attention-only Transformers on simple regression tasks either the models learned by GD and Transformers show great similarity or, remarkably, the weights found by optimization match the construction. Thus we show how trained Transformers implement gradient descent in their forward pass. This allows us, at least in the domain of regression problems, to mechanistically understand the inner workings of optimized Transformers that learn in-context. Furthermore, we identify how Transformers surpass plain gradient descent by an iterative curvature correction and learn linear models on deep data representations to solve non-linear regression tasks. Finally, we discuss intriguing parallels to a mechanism identified to be crucial for in-context learning termed induction-head (Olsson et al., 2022) and show how it could be understood as a specific case of in-context learning by gradient descent learning within Transformers.
论文链接:https://arxiv.org/abs/2212.07677
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢