
来自今天的爱可可AI前沿推介
[CV] MetaPortrait: Identity-Preserving Talking Head Generation with Fast Personalized Adaptation
B Zhang, C Qi, P Zhang, B Zhang, H Wu, D Chen, Q Chen, Y Wang, F Wen
[Microsoft Research & USTC & HKUST]
MetaPortrait:快速个性化自适应身份保持说话头部生成
要点:
-
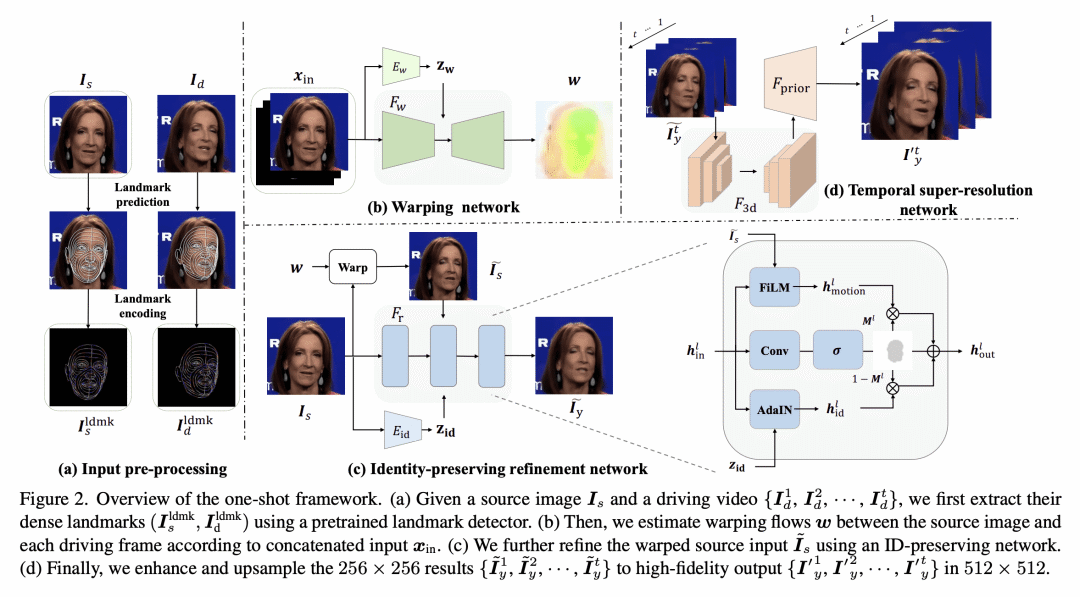
提出一种身份保持的说话头部生成框架,利用稠密特征点获得准确的几何感知流场,自适应融合源身份以更好地保持肖像关键特征来提高之前的方法; -
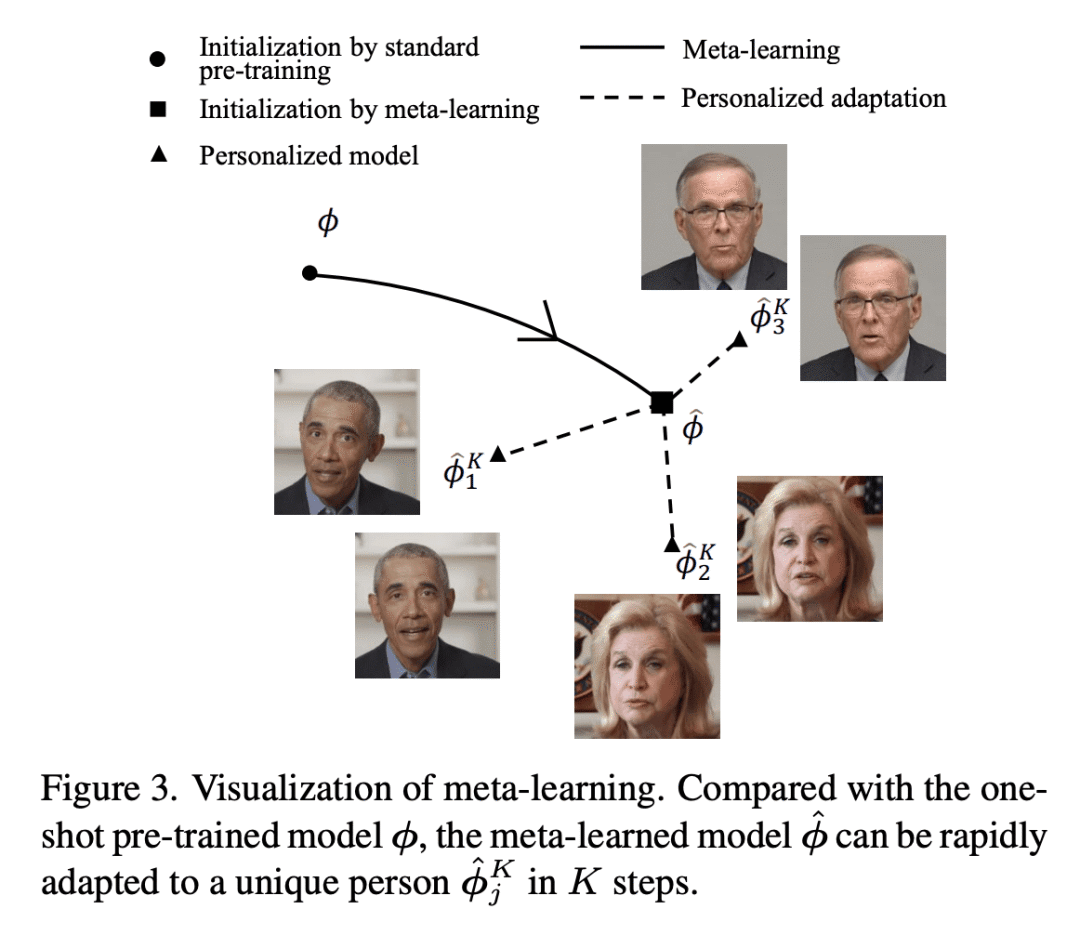
提出一种使用元学习方法的快速自适应模型,将个性化细节调整缩短到30秒; -
提出一种空间-时间增强模块,以提高细节和时间一致性。
摘要:
本文提出一种保留身份的说话头部生成框架,在两个方面推进了以前的方法。首先,相对于从稀疏流中插值,本文表面稠密的特征点对于实现精确的几何感知流场至关重要。第二,受换脸方法的启发,在合成过程中自适应地融合源身份,从而使网络更好地保留了图像肖像的关键特征。尽管所提出的模型在既定的基准上超过了之前的生成保真度,但为了进一步使说话徒步的生成符合实际使用,通常需要进行个性化的微调。然而,这个过程对计算的要求相当高,标准用户无法负担得起。为解决这个问题,本文提出了一种使用元学习方法的快速自适应模型。学习到的模型可以在30秒内自适应一个高质量的个性化模型。本文提出了一个空间-时间增强模块,在确保时间连贯性的同时改善精细的细节。广泛的实验证明所提出方法在单样本和个性化设置中都明显优于现有的技术水平。
In this work, we propose an ID-preserving talking head generation framework, which advances previous methods in two aspects. First, as opposed to interpolating from sparse flow, we claim that dense landmarks are crucial to achieving accurate geometry-aware flow fields. Second, inspired by face-swapping methods, we adaptively fuse the source identity during synthesis, so that the network better preserves the key characteristics of the image portrait. Although the proposed model surpasses prior generation fidelity on established benchmarks, to further make the talking head generation qualified for real usage, personalized fine-tuning is usually needed. However, this process is rather computationally demanding that is unaffordable to standard users. To solve this, we propose a fast adaptation model using a meta-learning approach. The learned model can be adapted to a high-quality personalized model as fast as 30 seconds. Last but not the least, a spatial-temporal enhancement module is proposed to improve the fine details while ensuring temporal coherency. Extensive experiments prove the significant superiority of our approach over the state of the arts in both one-shot and personalized settings. ?
论文链接:https://arxiv.org/abs/2212.08062

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢