

论文链接:
代码链接:
导读
现有的半监督算法大多着眼于改善训练方式,而忽略了“数据集中的哪部分需要标注”这个问题。我们的 Unsupervised Selective Labeling(USL)着眼于从完全无标注的情况下从无标注数据集中选择一部分数据来获取标注,然后再运行传统的半监督学习算法,从而以更少的标注成本来达到更高的半监督学习的效果。我们的方法在半监督学习里的常用数据集上达到了远好于现有选择方法的效果(使用原来 1/8 到 1/25 的标注数据,在半监督学习上达到原有选择方案的精确度)。
背景
众所周知,深度学习算法在很多应用领域都取得了很大的成功。但是最常用的监督学习算法训练出的模型效果严重依赖于数据量,尤其是数据标注的量。
半监督学习(Semi-supervised Learning,简称 SSL)旨在解决这个问题:因为无标注数据在大多数情况下很容易获取,然而手工标注需要大量的时间和成本,半监督学习使用部分标注的数据集来对模型来训练。通过利用未标注的数据,半监督学习可以只使用很少的标注数据来达到和标注整个数据集差不多的效果。半监督学习这个领域很大,本文关注 CV 领域的半监督分类问题。
半监督学习领域发展得非常迅猛,就拿 ImageNet 来说,只需要 1% 的标注数据(每个 class 给大约 13 张标注图片),SimCLRv2 就能达到 76.6% 的 Top-1 精确度(同样的模型给 100% 数据标注也只能达到 80.5%)。使用 Transformer 模型和 1% 的数据,新发布的 Semi-ViT 方法能达到 80% 的 Top-1 精确度。这也就是说在实际运用中,我们完全有可能可以只标注数据集的一部分,然后让模型也达到很高的精度。
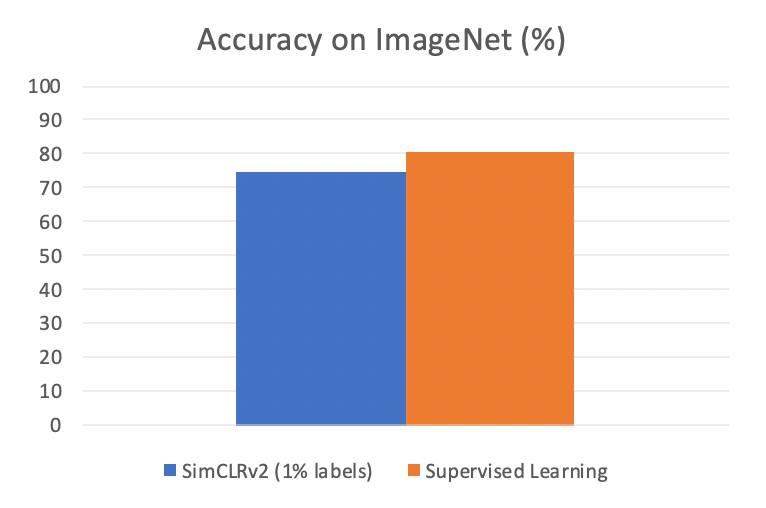
可是这里出现了一个问题:我们到底要标注数据集的哪个部分呢?这个问题是值得探讨的:如果不按照一定规律选择的话,我们完全可能会遇到几种情况:
1. 目前标注的这个数据其实之前有类似的数据标过了,我们完全可以让模型自己去推算这个数据的标注。
2. 目前标注的数据是一个outlier,这样标注的数据集很可能会导致半监督算法没办法稳定训练,甚至崩溃(collapse)。
这两种情况都没有办法给模型的训练提供有效信息,也就浪费了珍贵的标注预算。
大部分半监督领域的工作(例如 SimCLRv2)都直接绕过了这个问题,如下图(右)所示:这类算法假设我们已经有一个数据集,并且其中有一些部分已经是标注好的,然后直接在上面运行算法。
很多现有半监督领域的工作都是在半监督方法上做改进,以模型的训练方式为中心,我们这里称之为 Model-Centric SSL 方法。而这个数据集的标注方式其实就是随机抽取:我们随机在未标注的数据集里面,按照我们的标注预算来选择一部分数据(例如 1% 数据),来进行标注。
另一个大部分半监督领域的工作绕过的问题是,大部分的半监督领域的工作其实对数据分布做了假设:它们假设有标注数据集里面每个类的分布是平衡的。也就是说,在一个 1% 标注的 ImageNet 数据集里面,每个类基本都有 12 到 13 张图片是有标注的。我们称之为 stratified sampling。在像 ImageNet 这样的数据集上,其实我们其实是知道每张图片的标注的,所以我们可以在每个类内选出一定数目的图片来构成平衡的数据集,然后让它作为标注数据。
然而这在实际应用中是个问题:实际应用中的数据集都是没标注的,在这种情况下很难采集到一个有标注的数据集,然后这个数据集还需要是类别平衡的。
当然我们可以实事求是,在整个数据集里面随机选 1%,然后标注。我们称之为 random sampling,这也是在应用中实际可行的一个 setting。然而很多半监督算法在这种情况下的效果并不好。
我们当然可以通过提升半监督算法的方式来尝试环节这个问题(我们 CVPR 2022 文章 DebiasPL 提出了 de-bias 的方法来尝试解决,感兴趣的读者可以搜索 Debiased Learning from Naturally Imbalanced Pseudo-Labels),但假如输入的标注实在是不好(就比如前面提到的重复标注和标注 outlier 浪费了标注预算,以至于我们需要标注的地方没标注到),再怎么改进半监督算法也很难补足缺失的信息。
我们的方法跟上面所述的 Model-Centric 半监督方法不同,应该归类为 Data-Centric 方法:我们的目的是要找到值得标注的数据,然后在我们的标注预算之内进行标注,然后再把这个数据集给其他现有的(或者未来的)半监督算法进行训练。我们的方法对下游的 SSL 算法是无感的,也就是说,同一份标注的数据集,可以拿去给不同的 SSL 算法来进行训练。
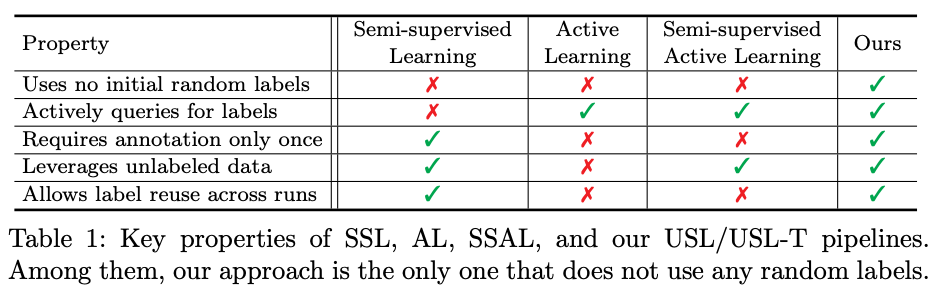
我们的方法是从一个啥标注都没有的数据集来选择数据给手工标注者来进行标注,因此叫做 Unsupervised Selective Labeling。下面这个表格比较了我们的方法和 SSL/Active Learning/Semi-Supervised Active Learning,可以看得出来,我们相比其他类似的模式在实际运用上更简单易用,并且标注预算的利用效率更高:
在实际效果上,我们的最终效果不但超越了 random sampling 这个 baseline,还超越了 stratified sampling(可别忘了 stratified sampling 其实看了数据集里面所有数据的标注来选择平衡的数据集),而没有使用原数据集的标注来选择数据。我们的方法选择的数据在类的选择覆盖率和平衡度上都远好于 baseline。
方法
半监督学习所使用的数据集该如何标注
对于如何为半监督学习选取所要标注的数据,我们提出了 2 个标准:
1. Representative:我们所选取的数据需要具有代表性,这样才能将我们从人类标注员那里获取的信息更多的进行推演,来获得强泛化能力。
2. Diverse:我们所选取的数据需要多样化,这样才能有效地将整个数据集的不同部分都获取足够的了解从而进行充分学习。
基于这两个标准,我们设计了两套算法。为了易用性考虑,我们设计了一套不需要训练(training-free)的算法,我们称之为 USL。这套算法使用预训练模型,在实际选取数据的时候不需要额外的训练。另外一套算法含有训练的步骤,其设计目标是通过训练获得更好的选择数据的能力,从而选取更有效的数据,我们称之为USL-T(T 代表 training-based)。
无论是 USL 还是 USL-T,这两套算法在实际使用的时候都遵循一个三步的 pipeline:
1. 无监督学习(可以使用现有的预训练模型如 MoCo,SimCLR,或者 CLD)
2. 无监督数据选择(我们的 USL 或者 USL-T 方法)并且获取标注
3. 使用有标注的数据和原有的无标注数据集来进行半监督训练(使用现有的 SSL 方法,例如 FixMatch)
我们的方法着重探索第二步。我们的方法使用的每一步都有很高效的 GPU 实现,因此跟很多 Active Learning 的方法不同,我们的方法可以很高效的运行在大数据集上面。同时 Training-free 方法需要的运算力和显存占用很低,适合运算有限的下游任务。
Unsupervised Selective Labeling(Training-Free)
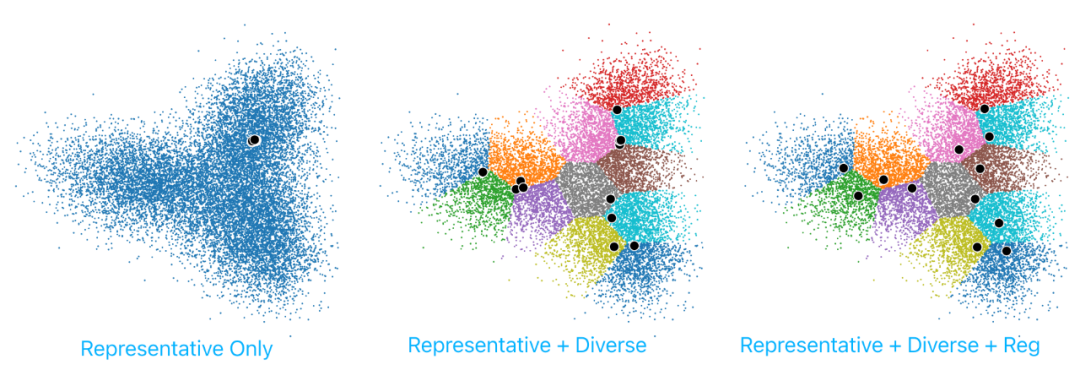
上面我们说了,被选择的 sample 需要具有代表性和多样性。如果我们只强调代表性,那么我们很可能会选择很多几乎一样的图片,而只关注数据集里面的一小块大量数据相似的区域,因为这个区域里的每一张图片都可以代表整个区域。如果我们只强调多样性,那么很可能我们会选择 outlier(毕竟它离谁都很远),可这样就对我们实际性能提升意义很小。因此我们需要合并这两个 metric,来获得对半监督任务最有效的样本来进行标注。
代表性:我们提出通过 sample density estimation 来估计代表性。首先我们拿一个无监督预训练模型 f(比如 MoCo 模型),获取它的 Feature 并计算距离:
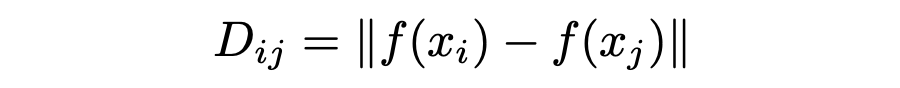
在 USL 方法中,一个 sample 的代表性可以通过这个 kNN density estimator 的变体来获取:
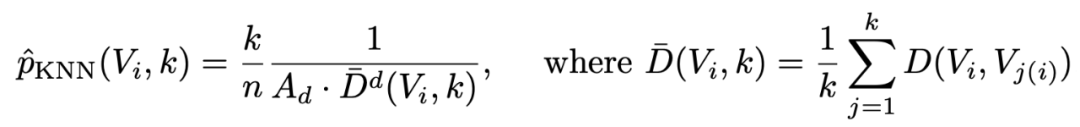
其中 k 是 neighbor 的数量,k(i) 代表 i 的第 k 个 neighbor, A 是一个体积常数(感兴趣的读者可以阅读文章)。我们选择 density 最高(最有代表性)的 sample 作为我们标注的 sample。
多样性:上面说的,只有代表性是不够的。实现多样性的方法很多,但也有很多不好实现或者不适合大数据集使用。因此我们提出了使用 clustering 算法来实现多样性的概念:一个 clustering 可以认为包含了相似的一系列图片,我们只在每一个 cluster 里面选择一个 sample(cluster 数量就是我们需要选择 sample 的数量),而选择 sample 的方式就是在上面提到的代表性 metric。最后达到的效果就是我们选择了每一个 cluster 中的最有代表性的 sample,也避免了多样性不足的问题。
因为有很高效的 GPU 实现,USL 使用了 k-Means 算法:
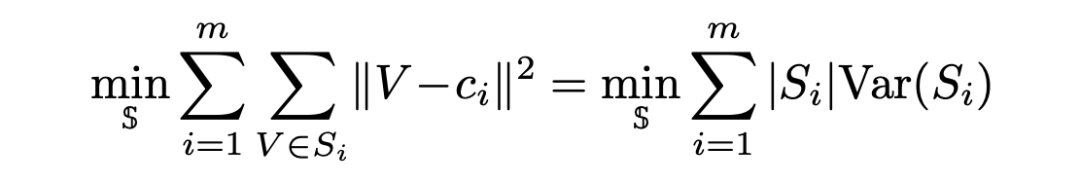
上面提出的这套方案理论上应该能提供代表性和多样性,可是我们会发现,clustering 这种硬性的限制很容易让 sample 聚集在 cluster 周围,降低多样性(如下图中间)。这主要是因为 cluster 之间完全是独立选择的,没有沟通。因此我们构建了一个 cross-channel communication 的 regularization 方法来协调不同 cluster 的选择。
Unsupervised Selective Labeling(Training-Based)
感兴趣的读者可能会说了,上面我们直接用了无监督方法(例如 MoCo)的 feature,但是这些 feature 并不是为了 sample 选择设计的。换句话说,这些无监督方法其实并不知道我们在下游拿它选择 sample。那有没有办法能 adapt 这些 feature 来获取更好的 sample 呢?
为了回答这个问题,我们提出了 USL-T,就是在 USL 上面做了改进,通过训练的方式提升 feature 质量和在样本选择上的能力。而这里说的训练同样不需要标注。这个部分有比较多的细节,原文有详细的解释,欢迎感兴趣的读者阅读。
Global Constraint:
我们先是从 K-Means clustering 方法开始,推导出一个可学习版本的聚类变体:
对于一个 feature similarity 函数 s,我们可以得到一个 one-hot assignment:

同时我们有一个 soft 版本的 assignment:
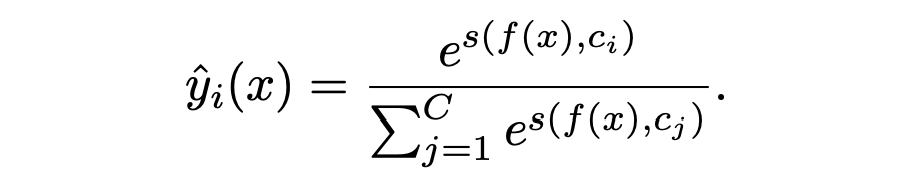
我们的训练目的是让神经网络把整个数据集 group 成不同的部分,以此来达到我们所说的多样性,以及每个部分的代表性,因此我们想要 soft 的 assignment 和 hard assignment 尽量接近:
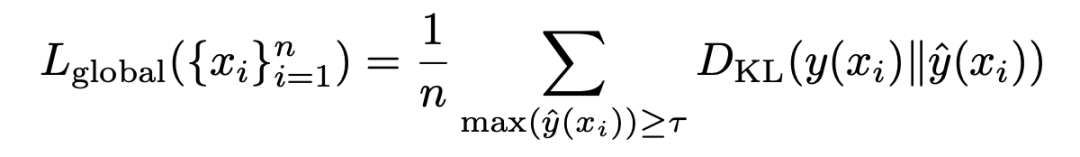
我们把这个 constraint 叫做 global constraint,因为它有对这个数据集内的所有 group 进行协调的功能。
Local constraint:
我们发现在一开始训练的时候,大部分的 sample 的 confidence 都很低,没有办法被 global constraint 所捕获。因此我们增加了一个 local constraint,来启动整个学习的过程。这个 local constraint 优化的是接近的 neighbor 之间的关系:如果两个 sample 很接近,那么这两个 sample 就应该有很类似的 assignment(也就是这两个 sample 的 assignment 的 KL divergence 应该很小)。
然而在实际训练过程中我们发现 local constraint 其实实现起来很 tricky,很容易就会让训练崩溃。我们发现了 2 种 collapse 的情况:
1. one-cluster collapse:整个 dataset 被 assign 到一个 group(也可以称为cluster)里面。
2. even-distribution collapse:整个 dataset 都被 assign 了一个 uniform distribution
我们针对这两种情况设计了一个损失函数,这个损失函数用 logit adjustment 来避免 one-cluster collapse(和 debias 有一些像),用 sharpen 来避免 even-distribution collapse:

优化函数是这两个 constraint 的结合:
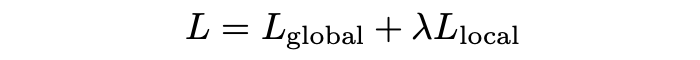
而最终我们的选择和 USL 类似,也是直接选择每个 cluster 里面预测概率最高的 sample。
至此,USL 方法就描述完成了,方法本身不复杂,实现起来也很高效,欢迎大家在各种数据集上尝试,我们也提供了像 CIFAR/ImageNet 上面选择的数据,如果大家碰巧在研究半监督方法,欢迎使用我们的标注/无标注数据 split,也许会比现有的 random split 有很大提升。
实验
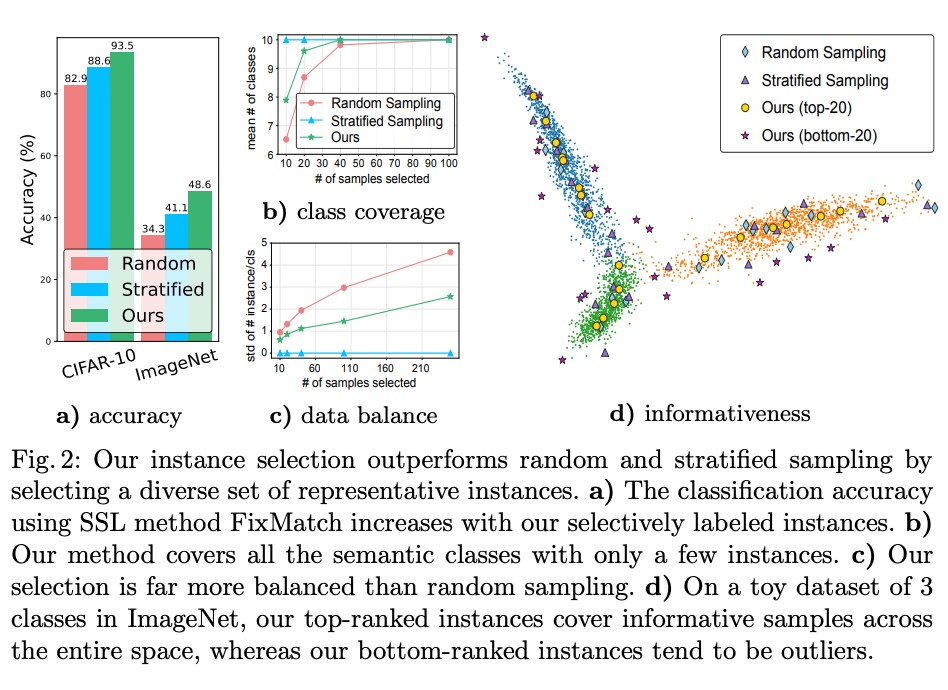
我们的方法,无论是 USL 还是 USL-T(training-based),在 CIFAR-10 上的 sample efficiency 都远超过其他方法(包括产用的 random selection,stratified selection,专门设计来选择数据的 Active Learning 方法)。只选择 40 个 sample 来标注的情况下,我们的方法在 FixMarch 上可以达到 93.5 的精确度,相比之下,如果随机选择 sample,则精确度只有 82.9。
上面有提到,很多半监督算法(例如 FixMatch)其实默认使用的是 stratified sampling 方法,也就是本质上使用了整个数据集的label进行平衡数据选择,这在真实情况里是不能做到的。然而就算如此,我们的方法仍然超越了 stratified sampling。
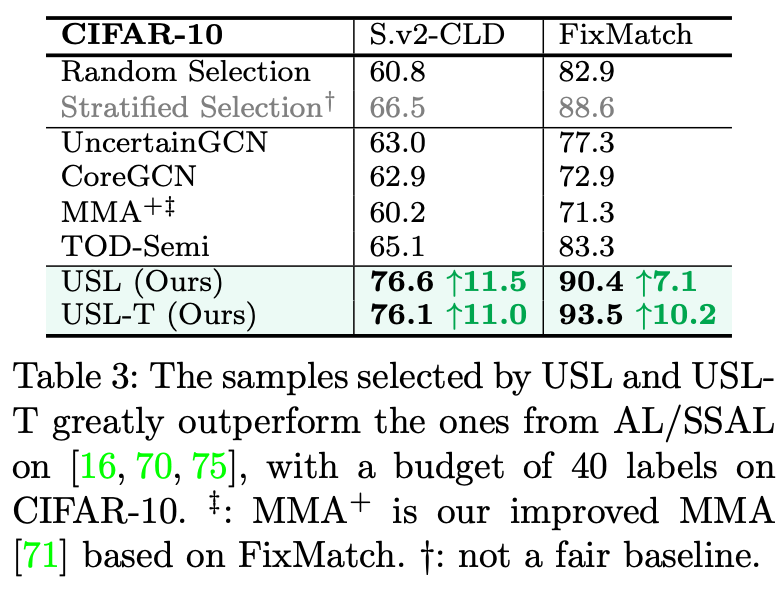
跟同样选择 sample 来进行标注的 Active Learning 方法比,我们的方法在 sample efficiency 上远超过 Active Learning。可以看到常见的 Active Learning 算法的 budget 基本都是 7500 起步,而我们只需要正常半监督学习所用的 40 个样本即可。
一个很重要的原因是:Active Learning 方法需要一些随机选择的 sample 来进行标注,以此获得一些任务相关的信息,然而在只有 40 个 sample 来标注的情况下,如果我们拿 10 个 sample 进行随机选择,那么我们就只剩下 30 个 sample 是可选的了。这样极大地限制了选择的空间。而且 Active Learning 尝试用随机获取的 sample 的 label 对任务进行估计,这本身在 sample 数量少的情况下就不怎么精确。
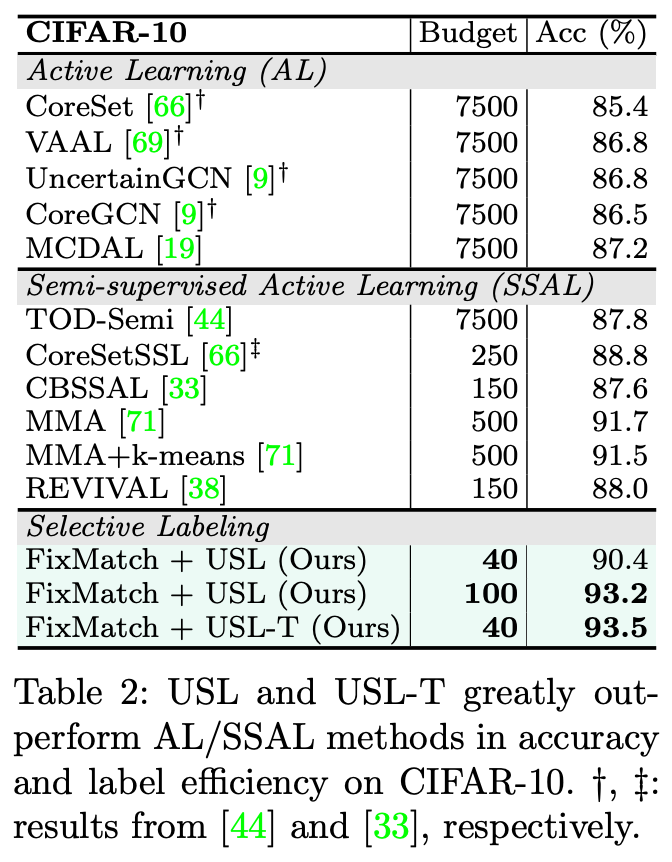
我们的方法对下游半监督算法是无感的,也就是说我们选择一次的样本可以适用于各种下游半监督算法和各种调参,而不是像 Active Learning 那样,每次模型调参或者重新运行就需要重新来进行一次数据标注,一次标注就只能训练一个模型。在运用到下游任务上的时候,同样的标注数据选择能在不同的半监督算法上都达到很大的提升。
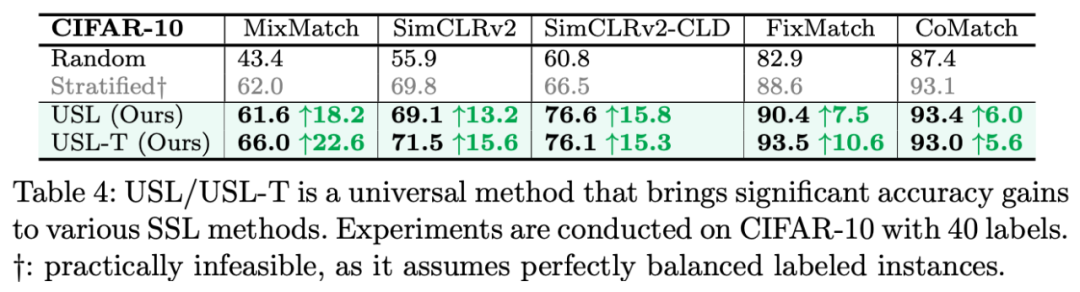
我们的方法也可以使用在较大的数据集上,相比 Active Learning 的方法基本上都只适用于小数据集(比如 CIFAR),我们只需要 1x 2080 Ti GPU就能在 ImageNet 上运行我们的方法。我们的方法选取 SimCLRv2 和 FixMatch 作为我们的半监督方法。使用我们选择的标注数据,半监督精度有很大的提升:
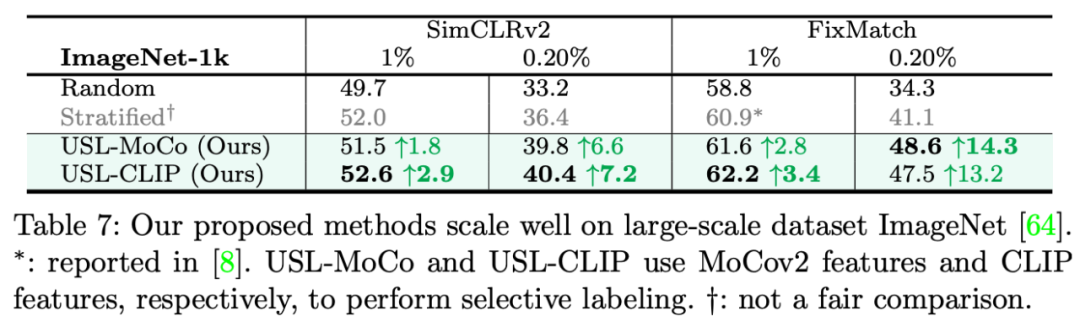
更巧妙的是,不光无监督预训练模型可以使用,就算是多模态训练的 CLIP 模型也可以跟 USL 一起使用。尽管 CLIP 没有在 ImageNet 上训练过,它仍然可以在 ImageNet 数据标注部分的选择上有很好的效果。这也证明了,如果我们有一个刚收集好的,完全没有标注的数据集,我们不需要在上面跑无监督预训练,而可以直接使用像 CLIP 这样的通用模型来进行 USL 选择。
以 CIFAR-10 为例,我们选择的 40 个 sample 无论是在类别平衡度还是代表性和多样性而言都远好于 baseline:

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢