
来自今天的爱可可AI前沿推介
[CL] ROSCOE: A Suite of Metrics for Scoring Step-by-Step Reasoning
O Golovneva, M Chen, S Poff, M Corredor, L Zettlemoyer, M Fazel-Zarandi, A Celikyilmaz
[Meta AI Research]
ROSCOE: 面向逐步推理评分的度量方法
要点:
-
提出ROSCOE,一套可解释的无监督自动评分,可改善和扩展之前的文本生成评估指标; -
提出一个推理错误的分类,用来生成和评估所提出的指标; -
实验结果与之前基于语义和词汇类似的基准指标相比,在文本生成方面表现出卓越的性能。
摘要:
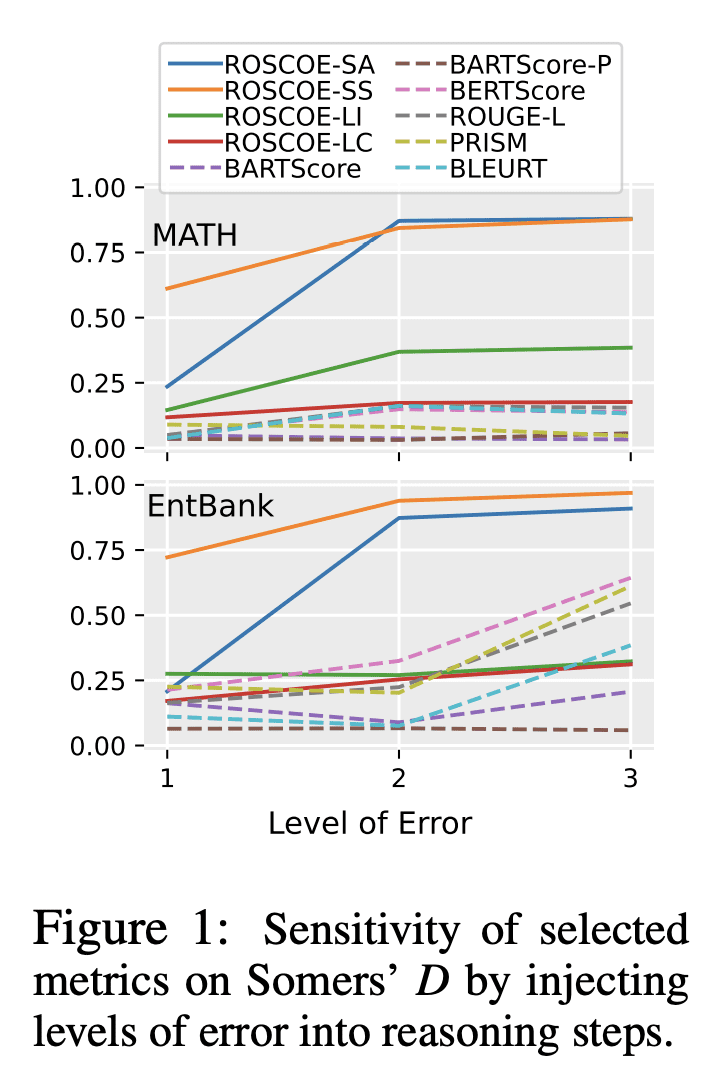
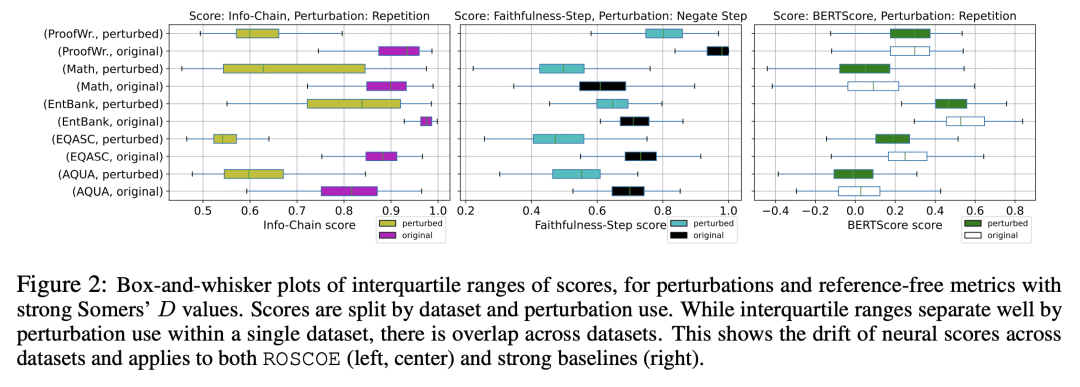
大型语言模型在被提示生成分步推理以证明其最终答案时,显示出改进的下游任务性能。这些推理步骤极大地提高了模型的可解释性和验证性,但是如果没有可靠的自动评估方法,客观地研究其正确性(独立于最终答案)是很困难的,根本不知道所述的推理步骤实际支持最终的终端任务预测的频率。本文提出ROSCOE,一套可解释的、无监督的自动评分,改进并扩展了之前的文本生成评价指标。为了评估ROSCOE与基线指标的对比,本文设计了一个推理错误的分类学,并在常用的推理数据集上收集合成和人工的评价分数。与现有的指标相比,ROSCOE可以通过利用分步推理的特性来衡量语义一致性、逻辑性、信息量、流畅性和事实性——以及其他特征。在五个人工标注的和六个程序干扰的诊断数据集上实证验证了所提指标的强度——涵盖了需要推理技能的各种任务,并表明ROSCOE可以持续地超越基线指标。
Large language models show improved downstream task performance when prompted to generate step-by-step reasoning to justify their final answers. These reasoning steps greatly improve model interpretability and verification, but objectively studying their correctness (independent of the final answer) is difficult without reliable methods for automatic evaluation. We simply do not know how often the stated reasoning steps actually support the final end task predictions. In this work, we present ROSCOE, a suite of interpretable, unsupervised automatic scores that improve and extend previous text generation evaluation metrics. To evaluate ROSCOE against baseline metrics, we design a typology of reasoning errors and collect synthetic and human evaluation scores on commonly used reasoning datasets. In contrast with existing metrics, ROSCOE can measure semantic consistency, logicality, informativeness, fluency, and factuality - among other traits - by leveraging properties of step-by-step rationales. We empirically verify the strength of our metrics on five human annotated and six programmatically perturbed diagnostics datasets - covering a diverse set of tasks that require reasoning skills and show that ROSCOE can consistently outperform baseline metrics.
论文链接:https://arxiv.org/abs/2212.07919
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢