
作者:Zixian Ma、Jerry Hong、Mustafa Omer Gul、等
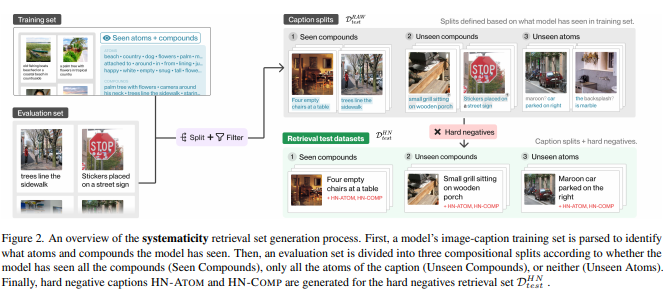
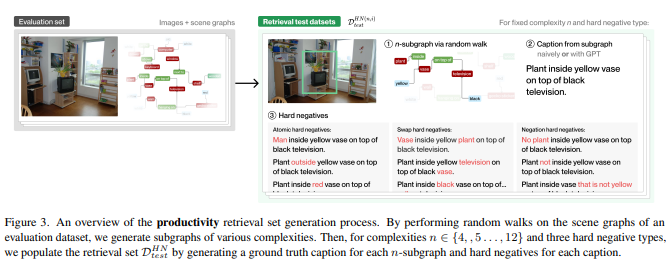
简介:本文研究组合性评估基准、以用于评估预训练的视觉语言模型的系统性和生产力。人类视觉和自然语言的一个共同基本特征是它们的组合性质。然而,尽管大型视觉和语言预训练带来了性能提升,但作者发现——在使用 4 种算法在海量数据集上训练的 6 种架构中——它们几乎没有表现出组合性。为了得出这个结论,作者引入了一个新的组合性评估基准 CREPE,它衡量认知科学文献确定的组合性的两个重要方面:系统性和生产力。为了衡量系统性,CREPE 由三个测试数据集组成。这三个测试集旨在测试在三个流行的训练数据集上训练的模型:CC-12M、YFCC-15M 和 LAION-400M。它们包含 385K、385K 和 373K 图像文本对以及 237K、210K 和 178K 硬底片字幕。为了测试生产力,CREPE 包含 17K 个具有九种不同复杂性的图像文本对,以及 246K 个带有原子、交换和否定箔片的硬负片字幕。数据集是通过重新利用 Visual Genome 场景图和区域描述并应用手工制作的模板和 GPT-3 生成的。对于系统性,作者发现当新颖的组合在检索集中占主导地位时,模型性能会持续下降,Recall@1 下降高达 8%。对于生产力,模型的检索成功率随着复杂性的增加而衰减,在高复杂性时经常接近随机机会。无论模型和训练数据集大小如何,这些结果都成立。

论文下载:https://arxiv.org/pdf/2212.07796.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢