
作者:Chengzhi Mao,Scott Geng, Junfeng Yang,等
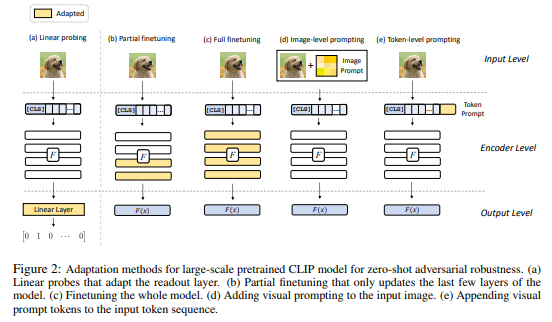
简介:本文研究大规模视觉语言模型的零样本对抗鲁棒性。预训练的大规模视觉语言模型(如 CLIP)对未见过的任务表现出很强的泛化能力。然而,难以察觉的对抗性扰动会显着降低 CLIP 在新任务上的表现。在这项工作中,作者确定并探索了为零样本对抗鲁棒性调整大规模模型的问题。作者首先确定模型适应过程中的两个关键因素:训练损失和适应方法——它们会影响模型的零样本对抗鲁棒性。然后,作者提出了一种文本引导的对比对抗性训练损失,它将文本嵌入和对抗性视觉特征与一小组训练数据的对比学习对齐。作者将这种训练损失应用于两种自适应方法:即模型微调和视觉提示调优。作者发现:在没有文本的情况下,视觉提示调整更有效;而在有文本指导的情况下,微调更胜一筹。总体而言,作者的方法显着提高了 CLIP 的零样本对抗鲁棒性,与 ImageNet 和 15 个零样本数据集相比平均提高了 31 点以上。作者希望这项工作能够阐明对大规模模型的零样本对抗鲁棒性的理解。
论文下载:https://arxiv.org/pdf/2212.07016.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢