
作者:Yekun Chai, Shuohuan Wang, Chao Pang, 等
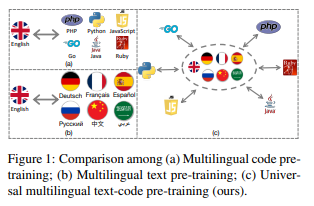
简介:本文研究计算机程序的通用跨语言预训练。使用相同编程语言 (PL) 的软件工程师可能会说不同的自然语言 (NL),反之亦然,这为沟通和工作效率设置了巨大的障碍。最近的研究已经证明了计算机程序中生成预训练的有效性,但它们总是以英语为中心。在这项工作中,作者朝着弥合大型语言模型 (LLM) 的多语言 NL 和多语言 PL 之间的差距迈进。作者发布了 ERNIE-Code:这是一个统一的预训练语言模型,适用于 116 个 NL 和 6 个 PL。作者采用两种方法进行通用跨语言预训练:从单语 NL 或 PL 学习模式的跨度破坏语言建模;基于枢轴的翻译语言建模依赖于许多 NL 和 PL 的并行数据。广泛的结果表明,ERNIE-Code 在代码智能的广泛最终任务中优于以前的 PL 或 NL 多语言 LLM,包括多语言代码到文本、文本到代码、代码到代码和文本到-文本生成。作者进一步展示了其零样本提示在多语言代码摘要和文本到文本翻译方面的优势。
论文下载:https://arxiv.org/pdf/2212.06742.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢