
作者:Hangyu Guo, Kun Zhou, Wayne Xin Zhao,等
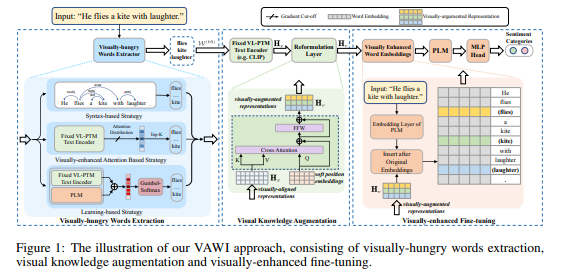
简介:本文研究通用的视觉增强微调方法。尽管预训练语言模型 (PLM) 通过纯文本自监督训练显示出令人印象深刻的性能,但人们发现它们缺乏视觉语义或常识,例如常见对象的大小、形状和颜色。现有解决方案通常依赖显式图像进行视觉知识增强(需要耗时的检索或生成),并且它们还对整个输入文本进行增强,而没有考虑在特定输入或任务中是否确实需要它。为了解决这些问题,作者提出了一种新颖的视觉增强微调方法,可以普遍应用于各种 PLM 或 NLP 任务,而无需使用任何检索或生成的图像,即 VAWI。具体来说,作者首先通过标记选择器从输入文本中识别视觉饥饿词(VH-words),其中提出了三种不同的方法,包括基于句法、注意力和学习的策略。然后,作者采用固定的 CLIP 文本编码器来生成这些 VH 词的视觉增强表示。由于它已经在大规模语料库上通过视觉语言对齐任务进行了预训练,因此能够将视觉语义注入到对齐的文本表示中。最后,视觉增强的特征将被融合并转化为基于VH-words的预先设计的视觉提示,可以将其插入到PLM中以丰富单词表示中的视觉语义。作者对十个 NLP 任务进行了广泛的实验,即 GLUE 基准、CommonsenseQA、CommonGen 和 SNLI-VE。实验结果表明,作者的方法可以在不同规模上持续提高 BERT、RoBERTa、BART 和 T5 的性能,并显着优于多个竞争基线。
论文下载:https://arxiv.org/pdf/2212.07937.pdf
源码下载:https://github.com/RUCAIBox/VAWI
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢