
自监督学习是让机器仅仅通过观察世界来学习图像、语音和文本的结构。这一领域在语音(如 wav2vec 2.0),计算机视觉(如 MAE)和自然语言处理(如 Bert)等方面取得了许多突破。但是训练大模型需要许多 GPU,因此对计算的要求很高。训练模型速度比最流行的快16倍

一年前,Meta AI 推出了第一个高性能自监督系统 Data2vec(Meta AI 发布 data2vec)以相同的方式学习语音,视觉和文本等三种不同的模式,将文本理解方面的研究进展应用于图像分割或语音翻译任务变得更加容易。近期 Meta AI 发布的新算法 Data2vec 2.0 效率更高,与最新的计算机视觉自监督算法精度相同,但速度提高了 16 倍。
Data2vec 2.0 与其前身相似,预测数据的上下文表示(神经网络的层),而不是图像的像素或者文本的单词/语音。与大多数其他算法不同,这些目标表示是 contextualized(语境化的),考虑了整个训练示例,因此带来了更丰富的学习任务,并使得 Data2vec 2.0 比其他算法学习得更快。
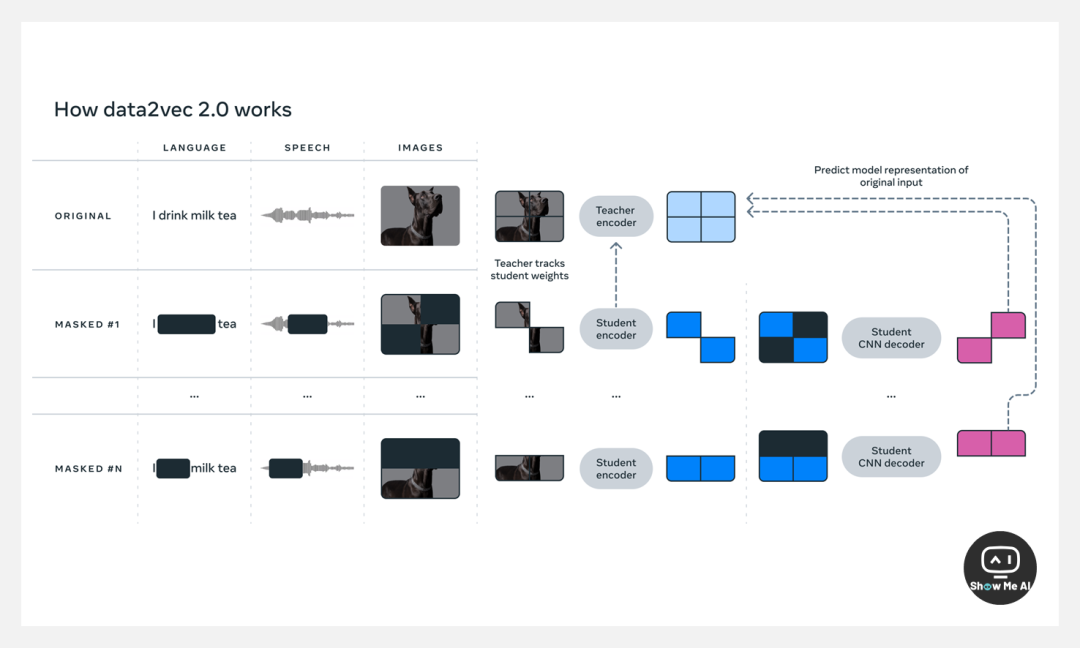
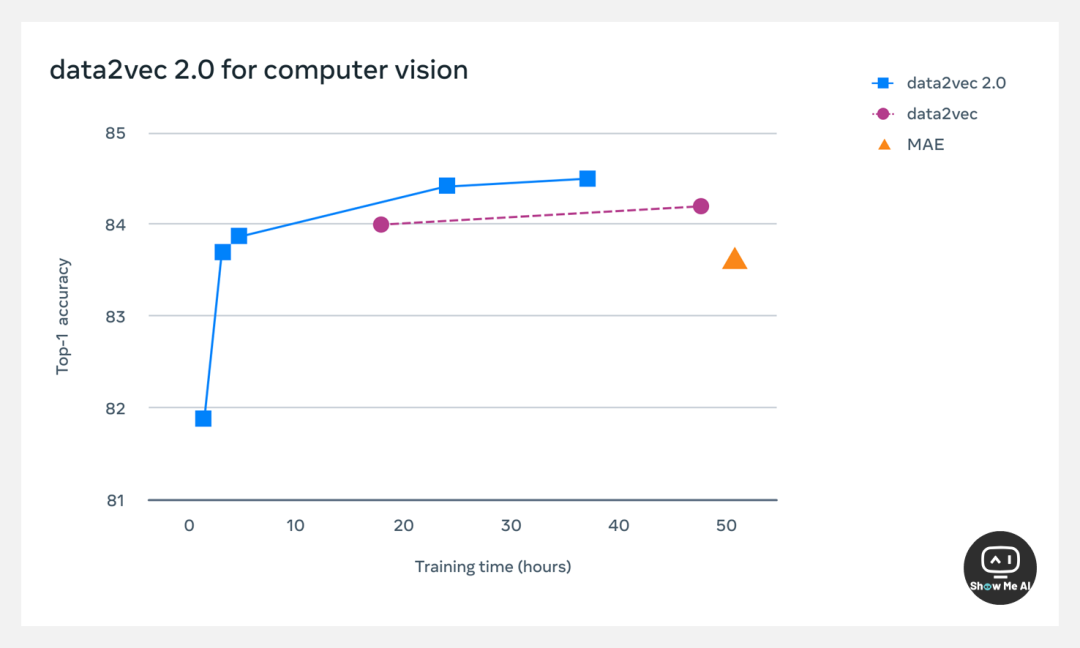
作者团队通过“为特定训练示例构建目标表示并将其重用于掩码版本”、“使用更高效的解码器模型”几种方式提高了 Data2vec 2.0 算法的效率,并与 Data2vec 算法进行了效率比较。在标准 ImageNet-1K 图像分类基准上,Data2vec 2.0 比 MAE 快 16 倍,同时保持相同的精度。
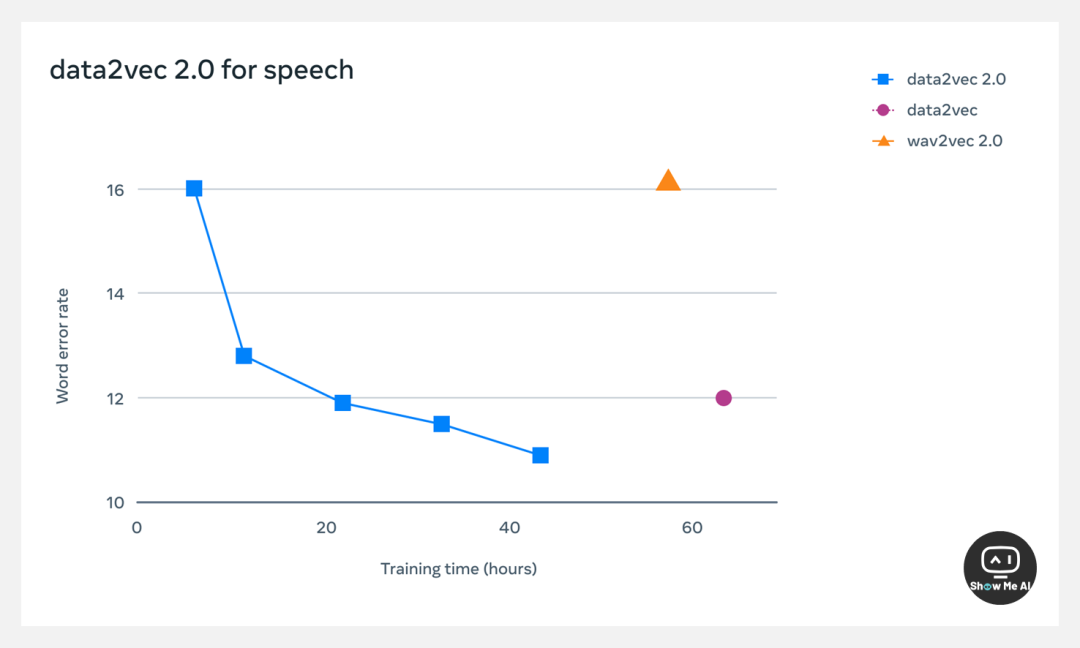
在 LibriSpeech 语音识别基准测试上,Data2vec 2.0 比 wav2vec 2.0 快 11 倍,在准确性方面不相上下。
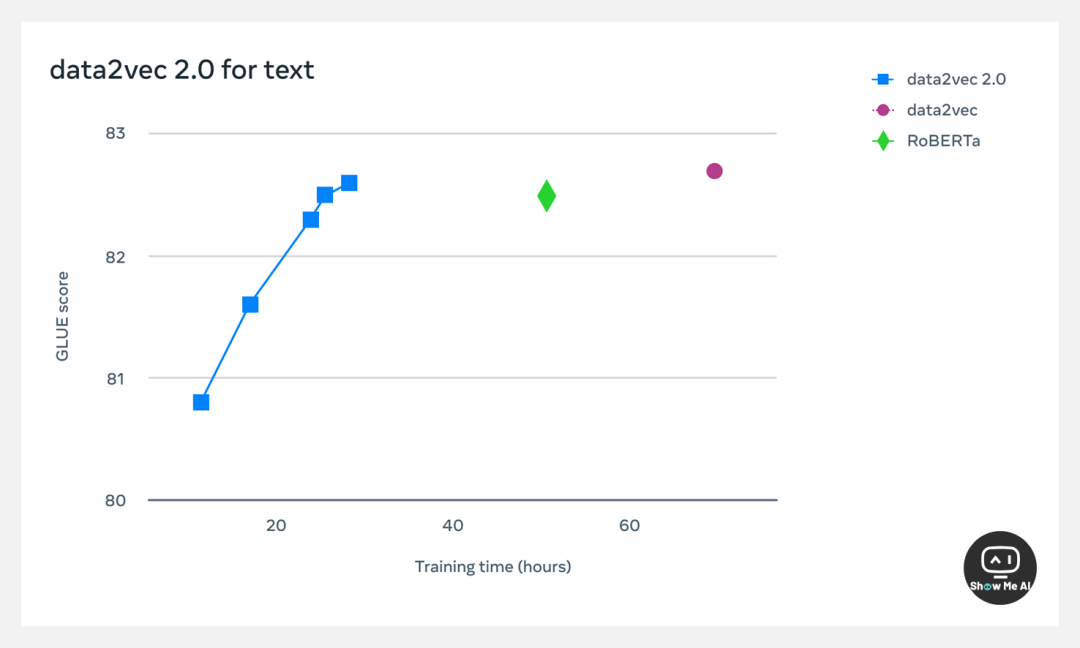
团队也在广泛使用的 NLP 通用语言理解评估基准上进行了测试。结果表明,Data2vec 2.0 与 RoBERTa 准确率相同。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢