
来自今天的爱可可AI前沿推介
[CL] Efficient Long Sequence Modeling via State Space Augmented Transformer
S Zuo, X Liu, J Jiao, D Charles, E Manavoglu, T Zhao, J Gao
[Microsoft & Georgia Institute of Technology]
基于状态空间增强Transformer的高效长序列建模
要点:
-
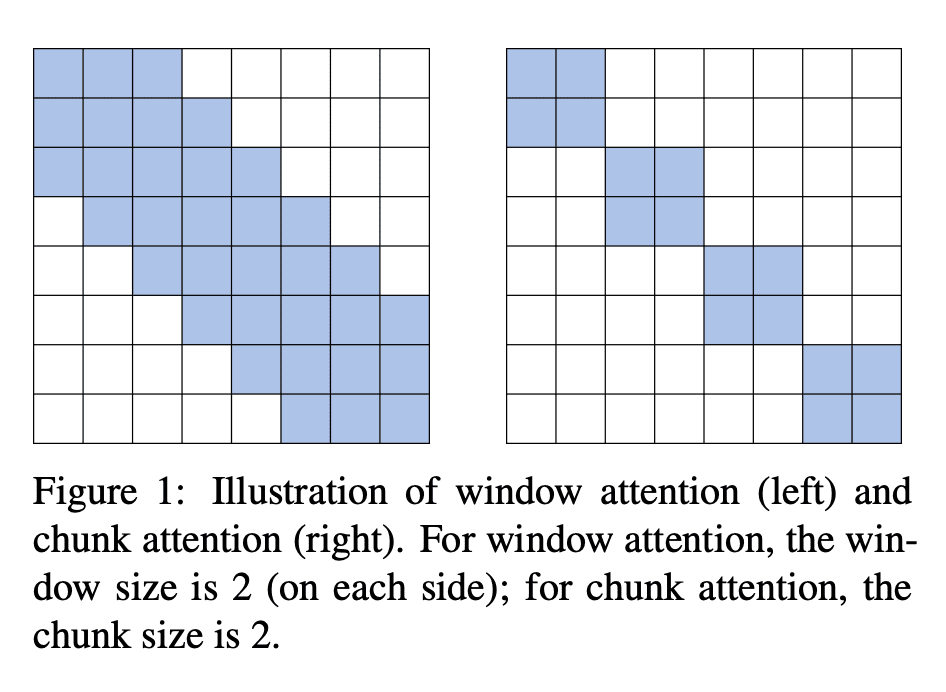
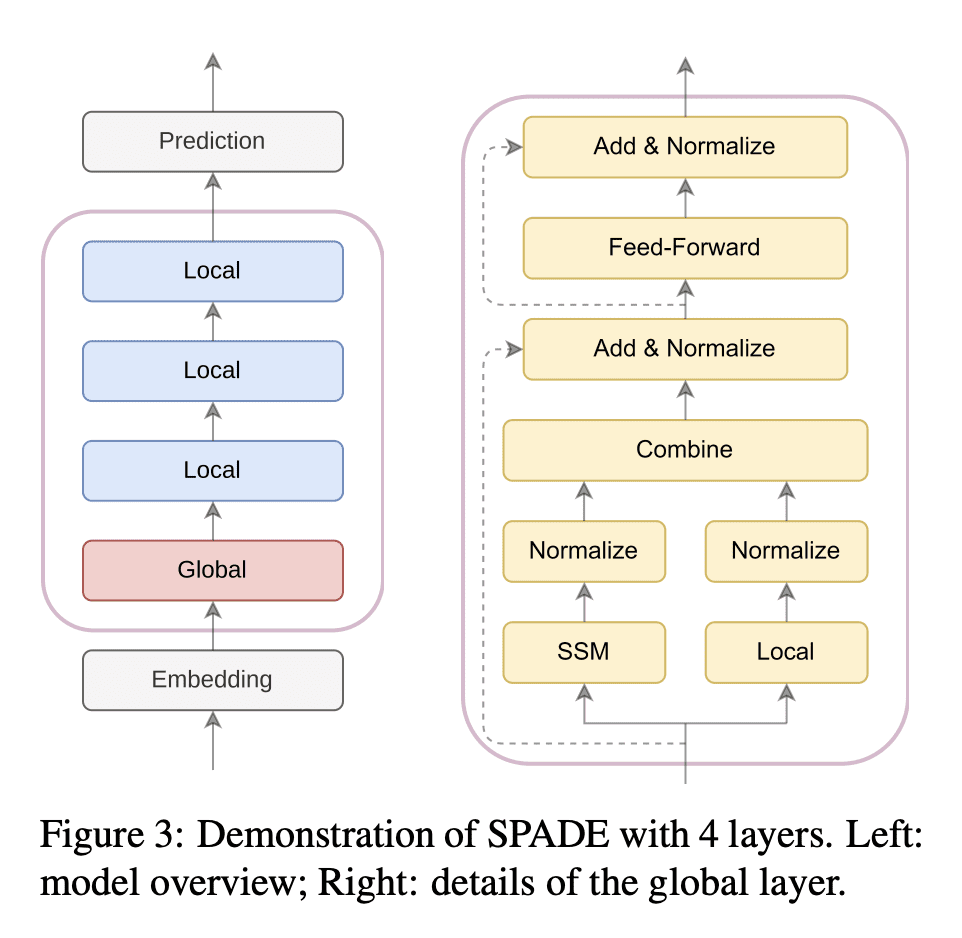
SPADE是一种多层Transformer模型,用SSM来增强粗粒度全局信息,并用高效的局部注意力方法来细化; -
SPADE具有线性时间和空间计算复杂度,可以有效且高效地处理长序列; -
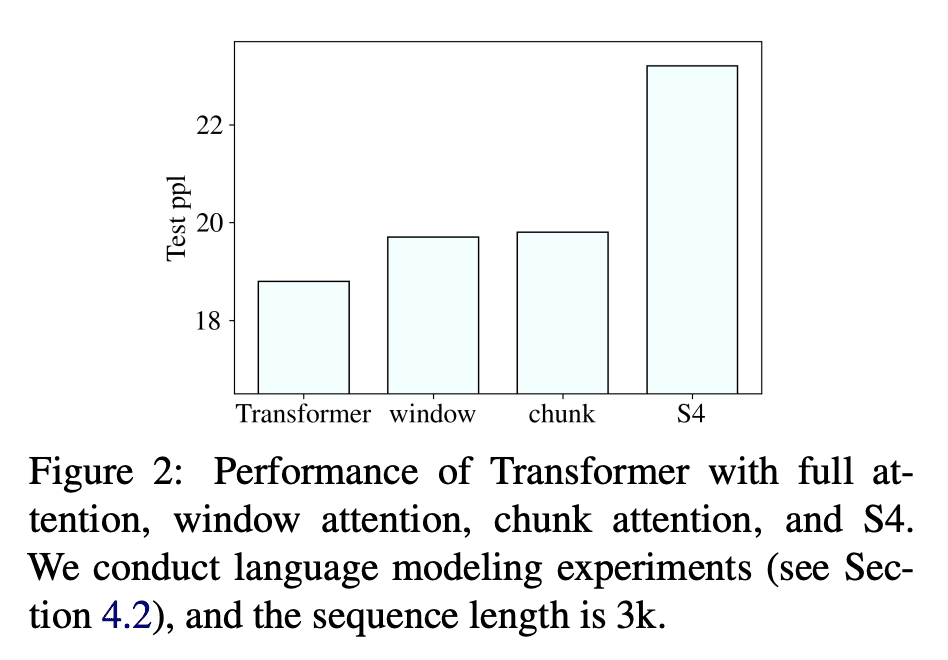
通过Long Range Arena(LRA)基准和语言建模数据集,以及自然语言理解(GLUE)和生成(摘要)任务的实验,证明了SPADE的有效性和效率。
摘要:
Transformer模型在各种自然语言处理任务中都取得了卓越的性能。然而,注意力机制的二次计算成本限制了它对长序列的实用性。现有的注意力变体可以提高计算效率,但有效计算全局信息的能力有限。与Transformer模型相比,状态空间模型(SSM)是为长序列量身定做的,但不够灵活,无法捕捉复杂的局部信息。本文提出SPADE,即State sPace AugmenteD TransformEr。在SPADE的底层增加了一个SSM,并在其他层采用了有效的局部注意力。SSM增强了全局信息,这补充了局部注意力中缺乏长程依赖的问题。在Long Range Arena基准和语言建模任务上的实验结果证明了所提方法的有效性。为进一步证明SPADE的可扩展性,预训练了大型编-解码器模型,并在自然语言理解和自然语言生成任务上展示了微调结果。
Transformer models have achieved superior performance in various natural language processing tasks. However, the quadratic computational cost of the attention mechanism limits its practicality for long sequences. There are existing attention variants that improve the computational efficiency, but they have limited ability to effectively compute global information. In parallel to Transformer models, state space models (SSMs) are tailored for long sequences, but they are not flexible enough to capture complicated local information. We propose SPADE, short for State sPace AugmenteD TransformEr. Specifically, we augment a SSM into the bottom layer of SPADE, and we employ efficient local attention methods for the other layers. The SSM augments global information, which complements the lack of long-range dependency issue in local attention methods. Experimental results on the Long Range Arena benchmark and language modeling tasks demonstrate the effectiveness of the proposed method. To further demonstrate the scalability of SPADE, we pre-train large encoder-decoder models and present fine-tuning results on natural language understanding and natural language generation tasks.
论文链接:https://arxiv.org/abs/2212.08136
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢