
来自今天的爱可可AI前沿推介
[CL] Teaching Small Language Models to Reason
L C Magister, J Mallinson, J Adamek, E Malmi, A Severyn
[Google Research & University of Cambridge]
教小型语言模型推理
要点:
-
用较大的教师模型产生的思维链对学生模型进行微调,可以提高各种数据集的任务性能; -
从大型语言模型中生成思维链,并在少样本提示中提供任务的解决方案很重要; -
由于较小模型的容量有限,因此知识蒸馏应限于单个任务。
摘要:
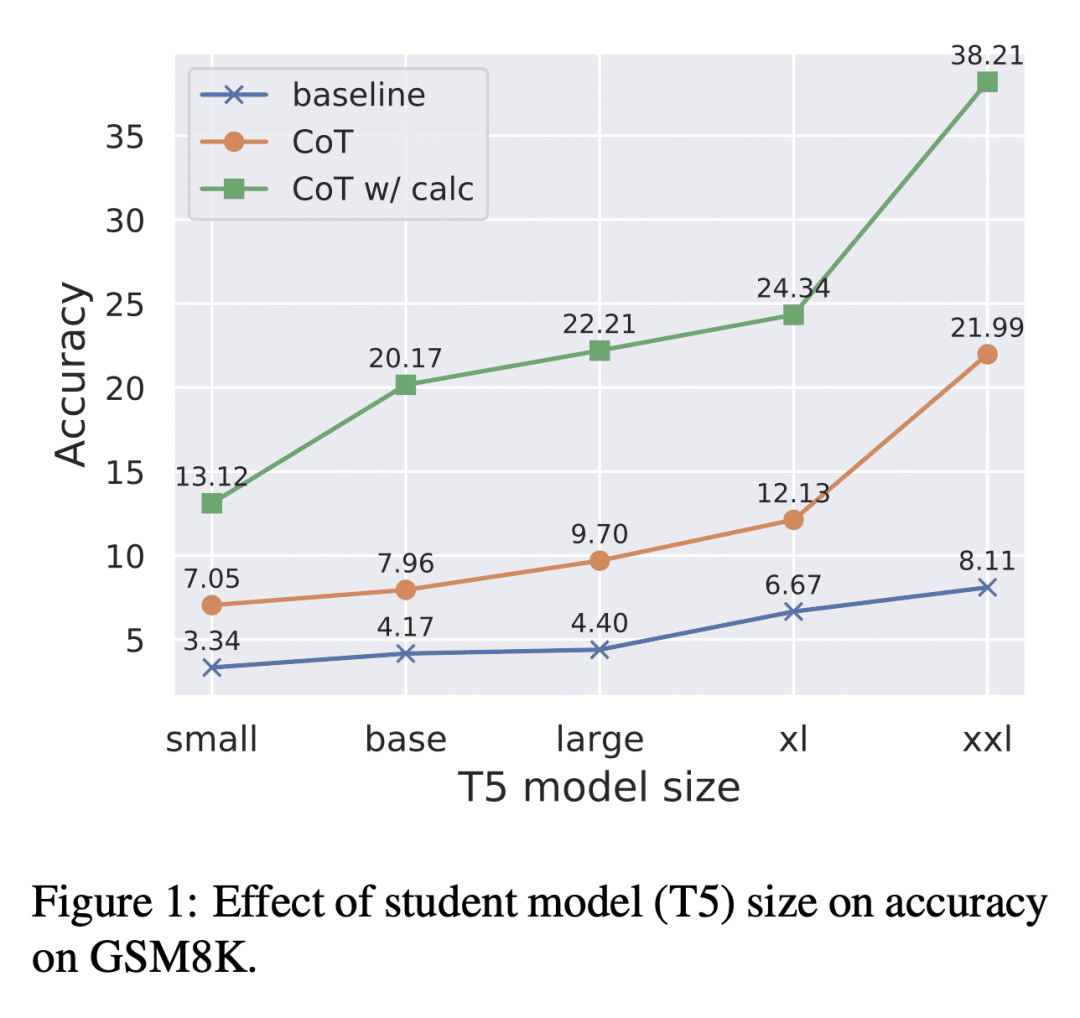
思维链提示成功地提高了大型语言模型的推理能力,在一系列的数据集上取得了最先进的结果。然而,这些推理能力似乎只在参数规模超过1000亿的模型中出现。本文探索了通过知识蒸馏将这种推理能力迁移到参数少于1000亿的模型中。用较大的教师模型产生的思维链对学生模型进行微调,实验表明,该方法提高了算术、常识和符号推理数据集的任务性能。例如,当对PaLM-540B生成的思维链进行微调时,GSM8K上的T5 XXL的准确性从8.11%提高到21.99%。
Chain of thought prompting successfully improves the reasoning capabilities of large language models, achieving state of the art results on a range of datasets. However, these reasoning capabilities only appear to emerge in models with a size of over 100 billion parameters. In this paper, we explore the transfer of such reasoning capabilities to models with less than 100 billion parameters via knowledge distillation. Specifically, we finetune a student model on the chain of thought outputs generated by a larger teacher model. Our experiments show that the proposed method improves task performance across arithmetic, commonsense and symbolic reasoning datasets. For example, the accuracy of T5 XXL on GSM8K improves from 8.11% to 21.99% when finetuned on PaLM-540B generated chains of thought.
论文链接:https://arxiv.org/abs/2212.08410
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢