

论文链接:https://arxiv.org/pdf/2203.06844.pdf
论文代码:https://github.com/implus/RecursiveMix-pytorch
摘要
数据融合(mixed-sample data augmentation)式的增广策略对计算机视觉模型的学习卓有成效。然而我们发现目前工作如Mixup,CutMix以及基于此的改进工作都仅仅考虑融合当前批次的输入数据,而忽略了训练过程中的历史信息。
在本文中,我们通过探索一种利用历史<输入-预测-真实标签>的三元组的新型训练策略,对学习的样本进行迭代融合,我们称之为“RecursiveMix” (RM)。具体来说,对于每一轮输入的图像,在下一轮中,我们都将其缩放并粘贴到新一轮的图像上面,得到融合的图像,同时对应的标签也是按照相应比例进行混合。此外,我们还引入一个对比损失,用于学习新一轮图像相关区域特征与其历史特征之间的语义一致性,我们验证了这有助于让网络学习尺度不变的特征表示。基于ResNet-50,RM在CIFAR-100上将分类准确率提高了3.2%,在ImageNet上提高了2.8%,而RM的额外的计算/存储成本可以忽略不计。在下游的目标检测任务中,RM的预训练模型在COCO上基于ATSS检测器可以比基线提高2.1mAP,超过CutMix预训练的模型1.4mAP。在语义分割中,基于UperNet,RM在ADE20K上也分别超过基线和CutMix1.9和1.1mIoU。
背景与动机
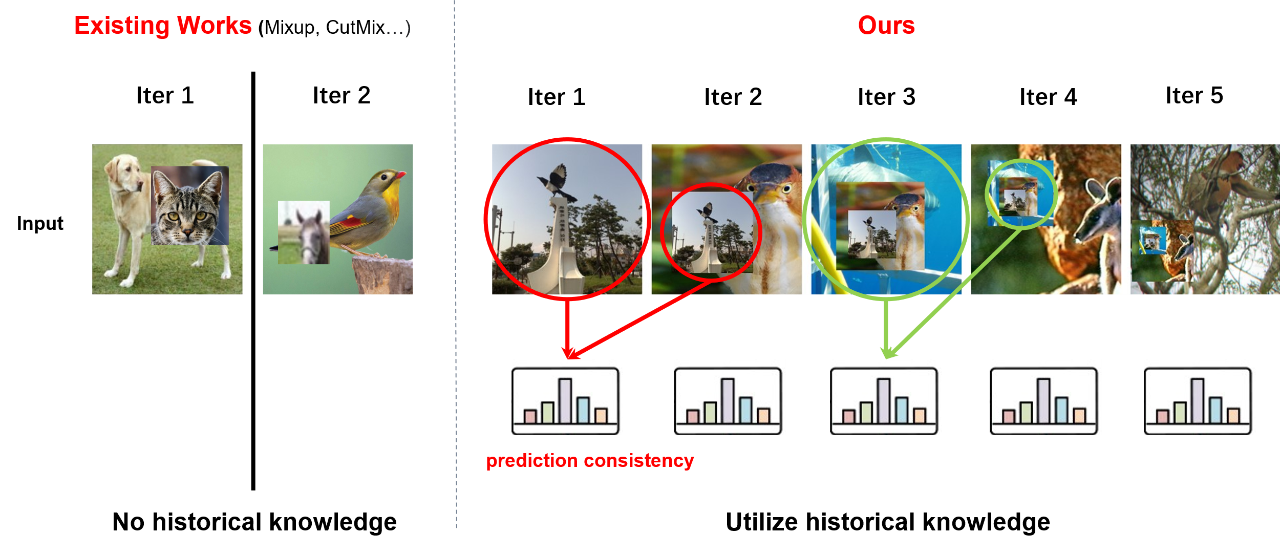
深度卷积神经网络(CNN)随着近年的发展取得了越来越好的表现,但是与此同时模型不可避免地变得更加复杂,而且对于数据的多样性要求越来越高。因此,一系列工作用正则化方法 [1、2]、数据增广方法 [3、4]防止网络过拟合。最近,基于数据融合的增广方法 [4,5、6、7]在多项基础图像任务展现了优越的性能。这些改进的方法局限于混合当前批次的输入图像,却无法利用网络学习过程中积累的历史信息,如图1所示,它们每一轮迭代过程都是相互独立的。在本文中,我们通过将前一轮输入缩放并贴在新图上,并构建前后网络相同语义区域输出的一致性,通过记录历史预测信息对空间语义进行约束,来帮助网络学习。
方法
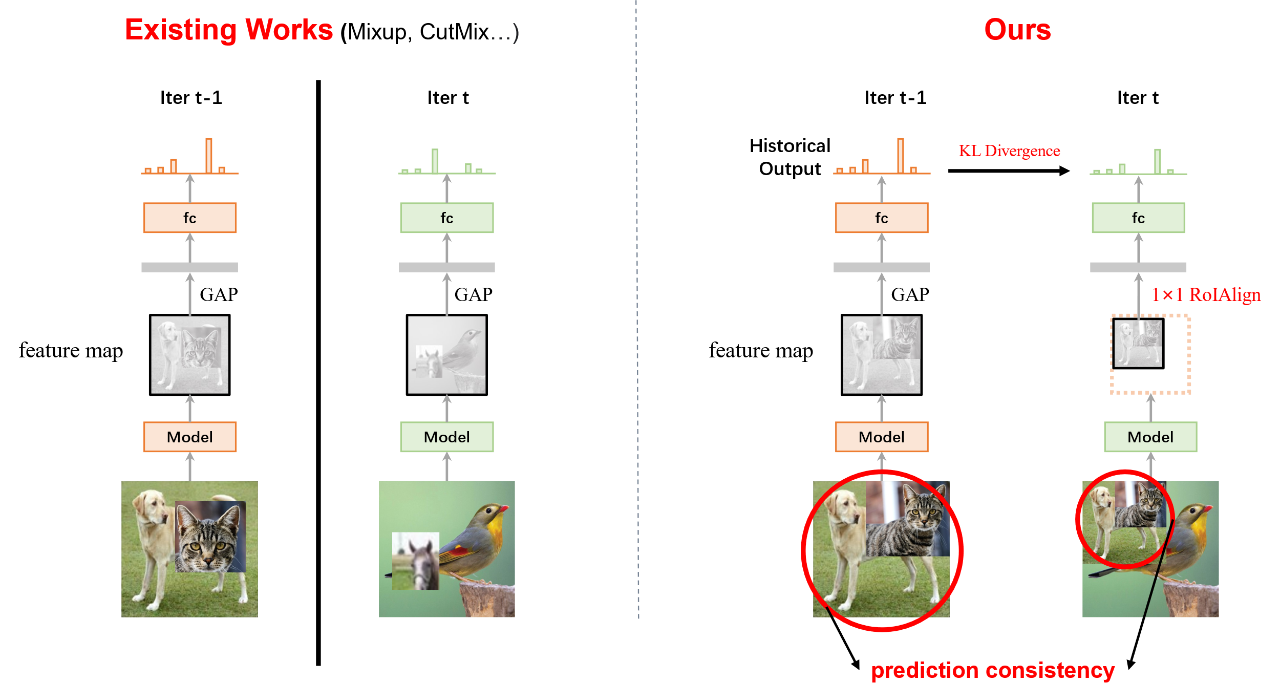
图2展示了每两个相邻的迭代的前向传播过程,已有方法直接将混合图像输入网络,全局池化后预测实例的混合类别。而我们将前一次迭代的输入贴在新的图像上来获得当前一轮的输入,同时构建出了一个一组具有语义一致性的输入,随后通过RoiAlign来获得相应部分的图像特征。最终我们通过KL散度损失来约束它与前一轮的历史预测之间的分布,从而巧妙、高效地利用了网络的历史输出信息。
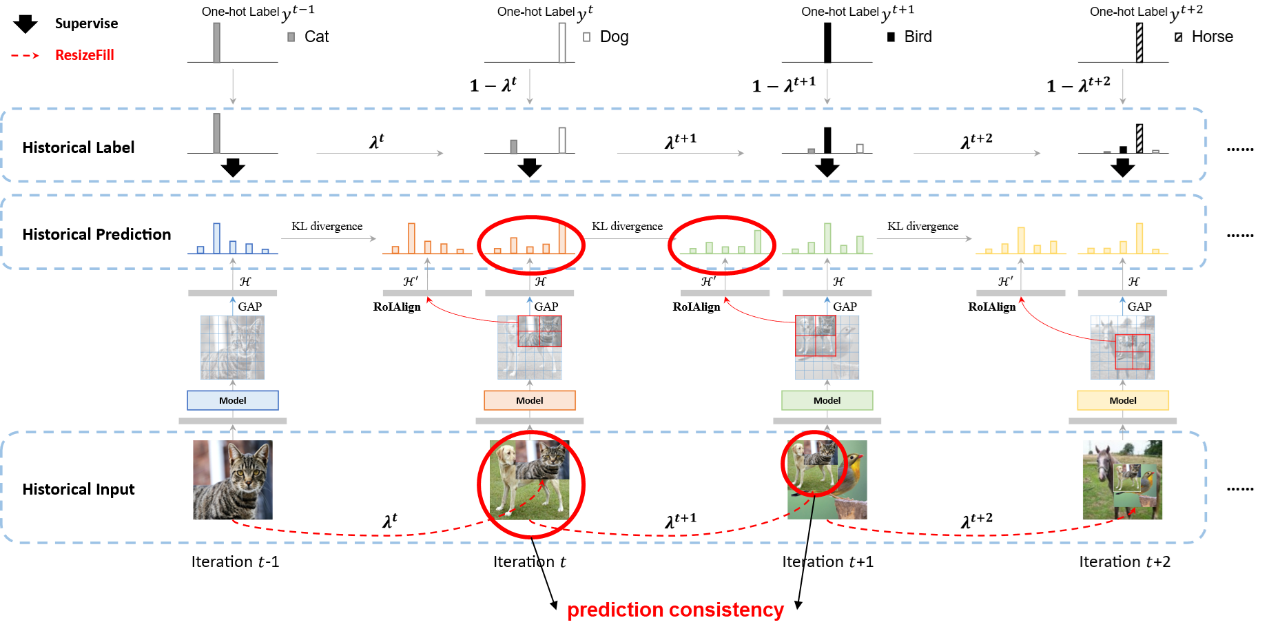
图3展示了RM的整体迭代流程。具体的,我们递归地使用了历史的(即上一个迭代的)输入、预测和真实标签,自然地实现多样化、多尺度的融合学习模式,同时可以以最小的代价引入空间语义对齐,从而综合提升网络的表征学习能力。
分析
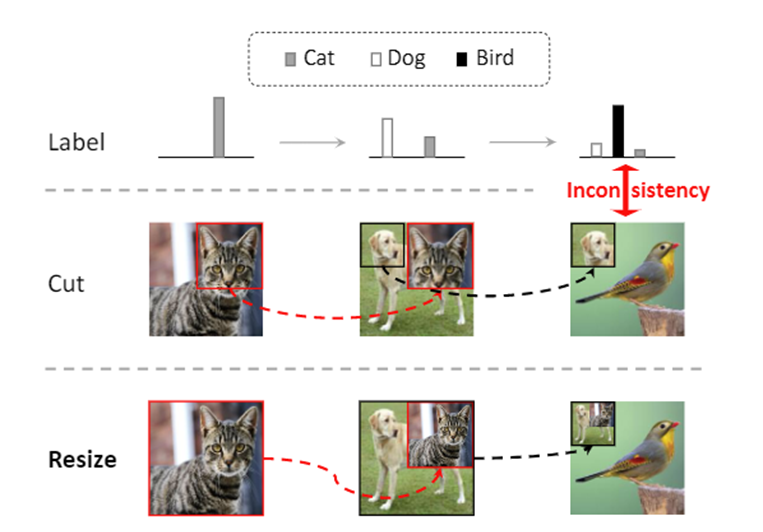
值得注意的是,在融合操作过程中,我们采用了resize而不是cut操作,因为原本cut操作可能会将含有语义的部分切掉导致学习无意义,resize的操作保证了循环粘贴时正确的语义保留(图4)。
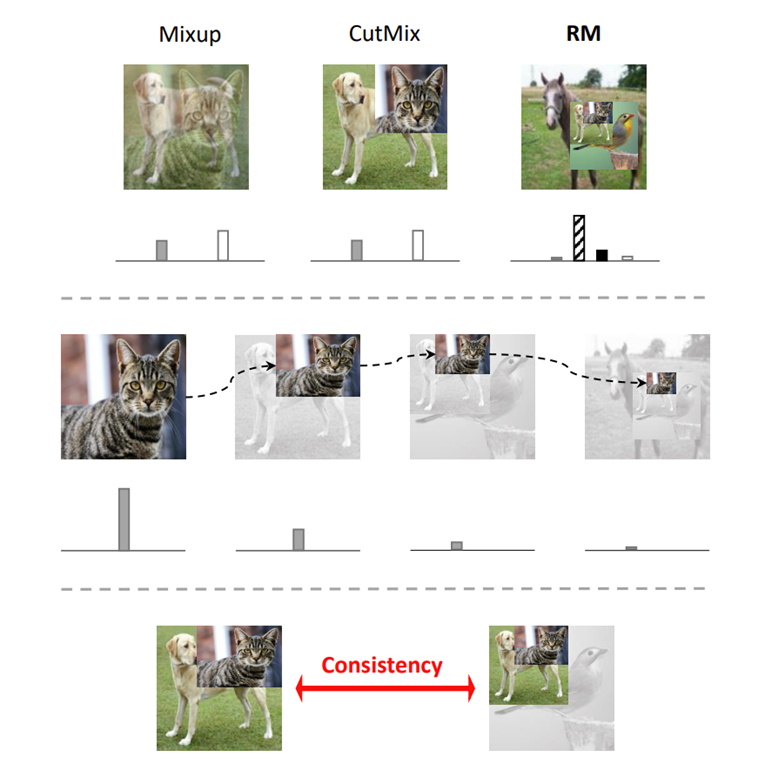
RM这种循环范式有图5所示的三个优势:
- 相对于mixup与cutmix仅包含2个对象的模式,RM增大了输入的多样性,使得一张图里通常能够包含较多物体。
据统计,采用RM后基本在一张图最多可以含有接近5个不同的物体对象,同时那些在更早期被贴上去的图像会因为不断的resize,最终越来越小逐渐消失,同理对应到label上的激活值也会降到10e-5以下,对应的监督效果也会消失。
-
利用递归的融合模式,自然地使得一个物体呈现多种尺寸的训练。
-
通过保持历史预测输出的一致性,利用了语义空间的一致性学习鲁棒的空间表征,而且也更加适合注重空间信息的下游任务。
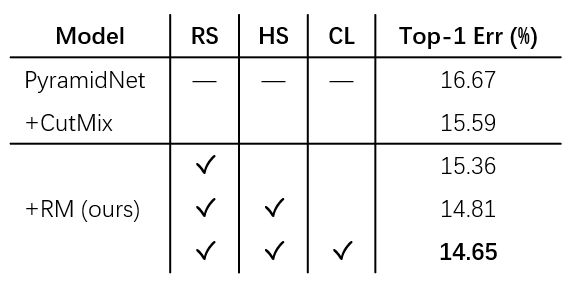
我们的消融实验表明以上的改进都对性能有所增益(表1)。
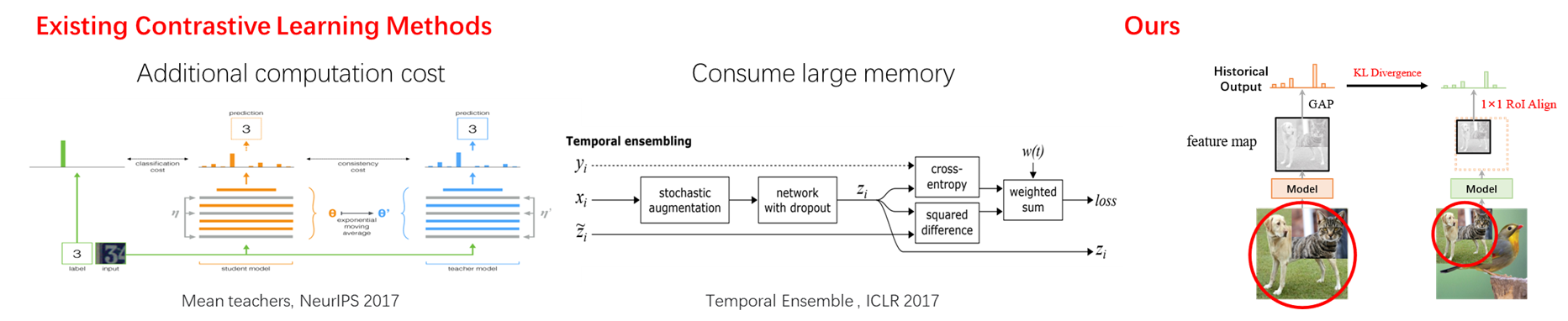
如图6所示,RM带来的另外一个好处就是,通过一种自然高效的方式引入了对比学习。如果不使用递归操作的情况下要实现对比学习,一般我们需要将每一个实例都额外通过一次网络,可能是将输入经过两种不一样的数据增广,或者像mean-teacher [8]一样额外通过一个经过EMA加权的网络。这种方式带来的问题就是需要额外的计算开销,训练时长也会大大增加。
第二种已有的方式虽然不用额外的前向次数,但是为了获取每一个实例对应的软标签,就需要把前一个epoch中每一张图的预测都记录下来,然后在下一个epoch作为对比学习的目标对象,例如Temporal Ensembling [9],这带来一个新的问题就是需要记录整个epoch的全部数据的信息,当我们的数据集很大,数量高达几十万乃至几百万的时候,就必须消耗大量的内存/显存来记录这些信息。
而RM不需要占用很多的计算以及内存消耗的方式实现,因为在递归范式中,历史输入会被贴到新一轮的图像上,在构建了输入的语义一致性同时,又包含了新的图像内容。所以我们不需要额外的重复前向传播,而且也只用存储一次迭代的输出并不断覆盖,相比于存一整个数据集这点开销可以忽略不计。
实验
接下来我们在CIFAR-10/100以及ImageNet数据上评估 RM 对于图像识别任务的效果,并在目标检测分割以及实例分割的下游任务上评估RM的性能。
表2展示了在CIFAR-10数据集上与其他已有方法的比较,可以看到基于PyramidNet-200 [8],RM 达到了 2.35% 的 Top-1 分类错误率,比基准线提升了1.5%。同时它也优于两个非常流行的数据混合方法 Mixup 和 CutMix,以及最新提出的一系列方法。
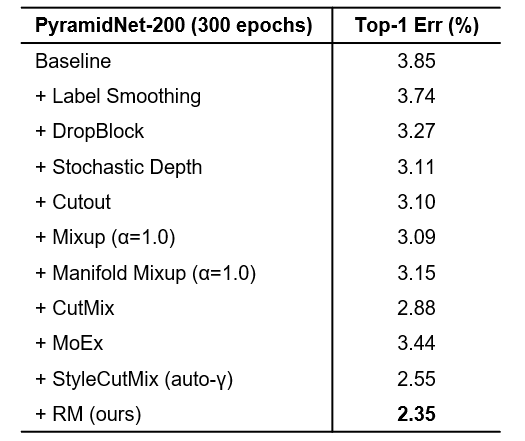
随后我们在CIFAR-100数据上开展基于多个骨干网络的性能验证,我们使用了5种不同的骨干网进行实验。表3显示RM有一致的提升。
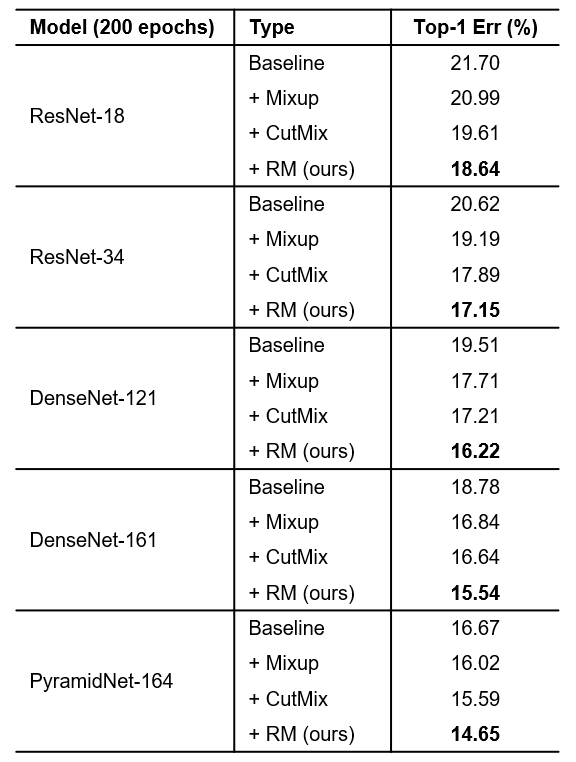
在ImageNet上的实验(表4)也表明RM取得了明显的优势。
接下来我们展示RM预训练的网络相比于其他数据增广算法在微调下游任务中的优越性。
首先在COCO 2017 dev上进行验证目标检测性能(表5),RM的预训练模型在COCO上基于ATSS检测器可以比基线提高2.1mAP,超过CutMix预训练的模型1.4mAP。
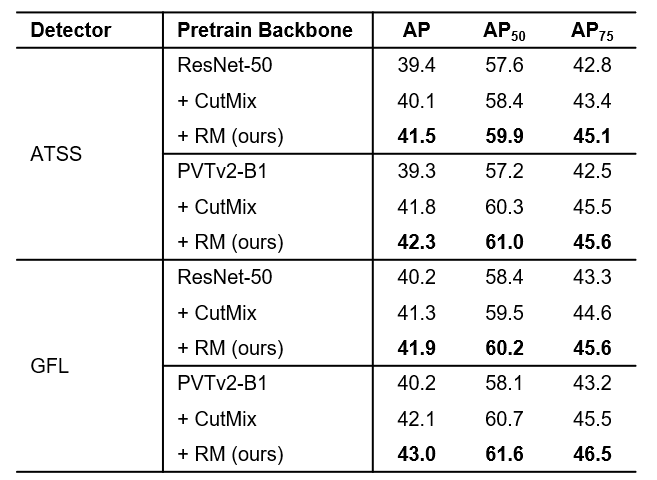
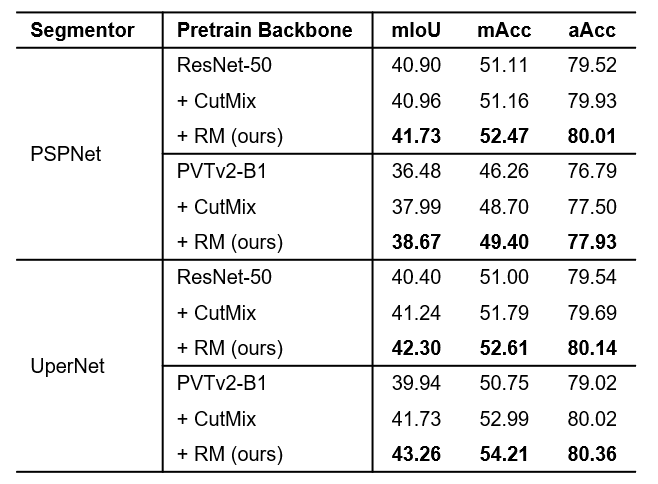
表6展示了在ADE20K上RM也有较大的提升。其中基于UperNet,RM在ADE20K上也分别超过基线和CutMix1.9和1.1mIoU。
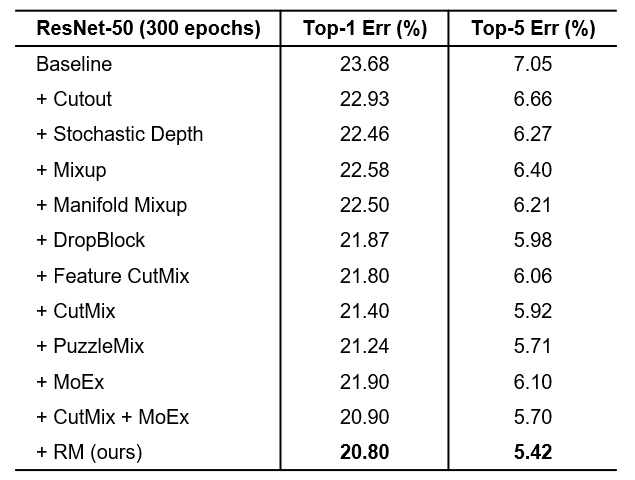
RM是非常轻量有效的,与其他的增广算法相比,计算量和参数量都基本相同,同时达到了更高的准确度(表7)。
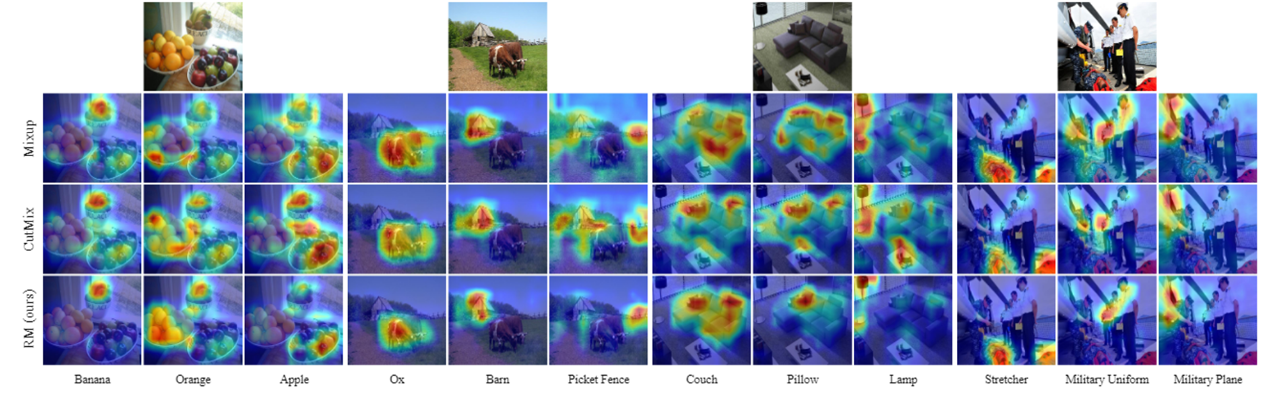
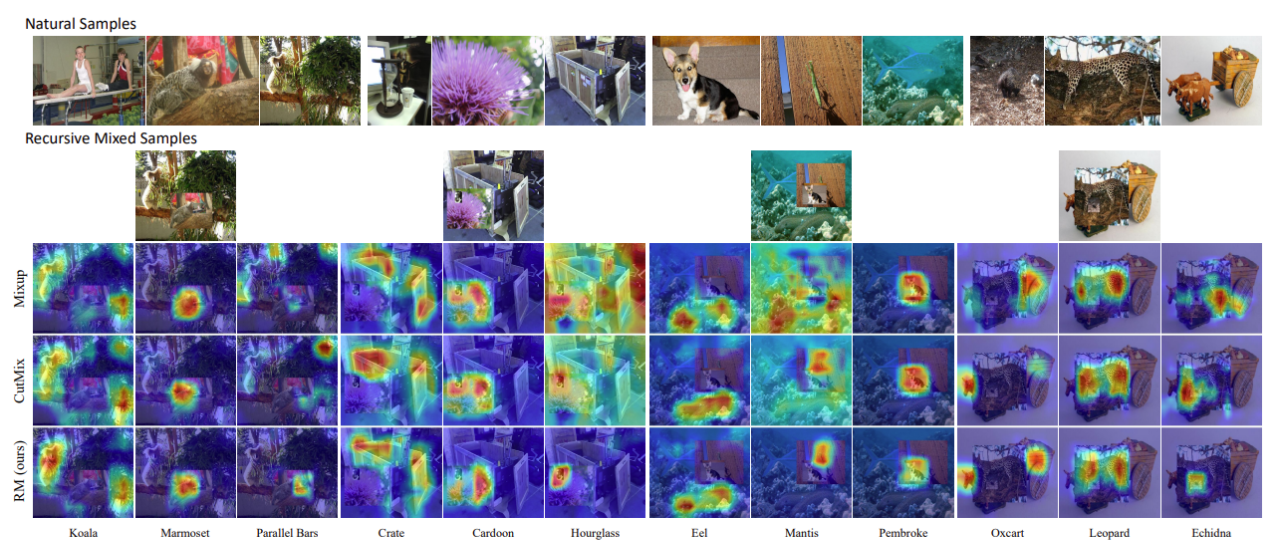
我们通过 CAM [10] 可视化类激活图展示RM的效果。我们首先选择了包含多个真实类别的单张图像,并为每个类别可视化了其热度图(图 7),结果显示 RM 比 基线,Mixup,CutMix 可以更准确地定位到相应类别的对象。图8展示了在RM迭代过程中生成的图像可视化结果,可以看出RM热度图的定位更加准确。这是因为RM 的递归范式使得模型在学习过程中,输入大部分都是具有多个对象 (>2) 的图像,增加了数据空间输入的多样性,并通过多尺度和空间变化的视图丰富了每个实例。因此,该模型更能够识别包含更多类别或大小差异很大的对象的复杂图像。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢