
【哈佛+MIT+普林斯顿联合团队】基于模仿学习的自回归知识蒸馏 【论文标题】Autoregressive Knowledge Distillation through Imitation Learning 【作者团队】Alexander Lin,Jeremy Wohlwend,Howard Chen,Tao Lei 【发表时间】2020/09/15 【论文链接】https://arxiv.org/abs/2009.07253
【推荐理由】
本文来自明星人工智能创业公司 ASAPP,由该公司雇佣的来自哈佛大学、MIT、普林斯顿大学的研究人员合作完成,旨在通过模仿学习技术进行面向自然语言生成自回归模型的知识蒸馏。
近年来,随着自注意力机制、Transformer 等技术的发展,自然语言处理涌现出了以 EMLO、BERT、GPT 为代表的一系列备受瞩目的研究成果,并且在机器翻译、对话系统、摘要生成等自然语言生成任务中大放异彩。然而,要想将这些模型部署于真实世界的应用中还存在着诸多的挑战,例如:(1)模型的规模过大,包含数十亿参数,从而大大降低了推理的速度(2)目前选用的自回归模型架构逐渐从 RNN 转变为了 Transformer,Transformer 的自注意力机制在提升表征性能的同事也在测试时带来了更高的计算复杂度。 为此,研究人员提出了各种压缩神经网络模型的方法,知识蒸馏就是其中之一。知识蒸馏旨在将预训练好的大型「老师」模型学到的信息迁移到较小的未训练的「学生」模型上。与权值剪枝等方式不同,知识蒸馏可以得到架构与原始的「老师」模型差异很大的压缩模型,因此可以同时保证压缩模型的性能和计算效率。
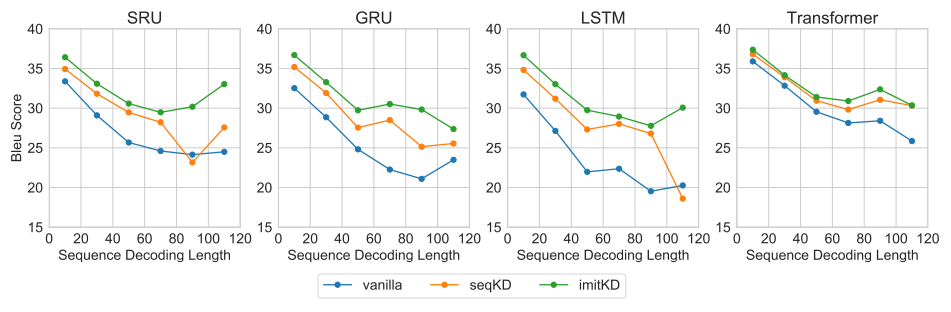
本文作者认为,目前流行的序列级的知识蒸馏方式(SeqKD)还未能完全发挥「老师」模型的潜力,这类模型使用由「老师」模型生成的修正后的数据集以及标准的负对数似然目标函数来训练「学生」模型,这会导致自然语言生成领域中常见的暴露偏差(exposure bias)问题,即推理和训练时使用的输入不同,在训练时每一个词输入都来自真实样本,而在推理时当前输入用的却是上一个词的输出。常见的解决该问题的方法有:「scheduled-sampling」、正则化技术、强化学习等。在本文中,作者受模仿学习的启发,设计了一种名为「基于模仿的知识蒸馏」(ImitKD)自回归模型,将「老师」模型作为金标准,从而指导「学生」模型生成自然语言序列。
本文在机器翻译和摘要生成任务上的实验结果表明,ImitKD 的性能要始终优于其它的知识蒸馏方法,它在 BLEU 和 ROUGE 两种指标上的性能相较于未使用「老师」网络的模型分别提升了 1.4 和 4.8。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢