
符尧(yao.fu@ed.ac.uk),爱丁堡大学 (University of Edinburgh) 博士生,本科毕业于北京大学。他与彭昊、Tushar Khot在艾伦人工智能研究院 (Allen Institute for AI) 共同完成英文原稿,与剑桥大学郭志江共同翻译为中文。
感谢上海交通大学何俊贤,加州大学洛杉矶分校鲁盼,达特茅斯学院刘睿博对初稿的讨论与建议。感谢 Raj Ammanabrolu (Allen Institute for AI), Peter Liu (Google Brain), Brendan Dolan-Gavitt (New York University), Denny Zhou (Google Brain) 对终稿的讨论和建议,他们的建议极大程度上增加了本文的完整度。
最近,OpenAI的预训练模型ChatGPT给人工智能领域的研究人员留下了深刻的印象和启发。毫无疑问,它又强又聪明,且跟它说话很好玩,还会写代码。它在多个方面的能力远远超过了自然语言处理研究者们的预期。于是我们自然就有一个问题:ChatGPT 是怎么变得这么强的?它的各种强大的能力到底从何而来?在这篇文章中,我们试图剖析 ChatGPT 的突现能力[1](Emergent Ability),追溯这些能力的来源,希望能够给出一个全面的技术路线图,来说明 GPT-3.5[2] 模型系列以及相关的大型语言模型[3] 是如何一步步进化成目前的强大形态。我们希望这篇文章能够促进大型语言模型的透明度,成为开源社区共同努力复现 GPT-3.5 的路线图。
目录

重点突出一下当前阶段 GPT-3.5 的进化历程:
到目前为止,我们已经仔细检查了沿着进化树出现的所有能力,下表总结了演化路径:
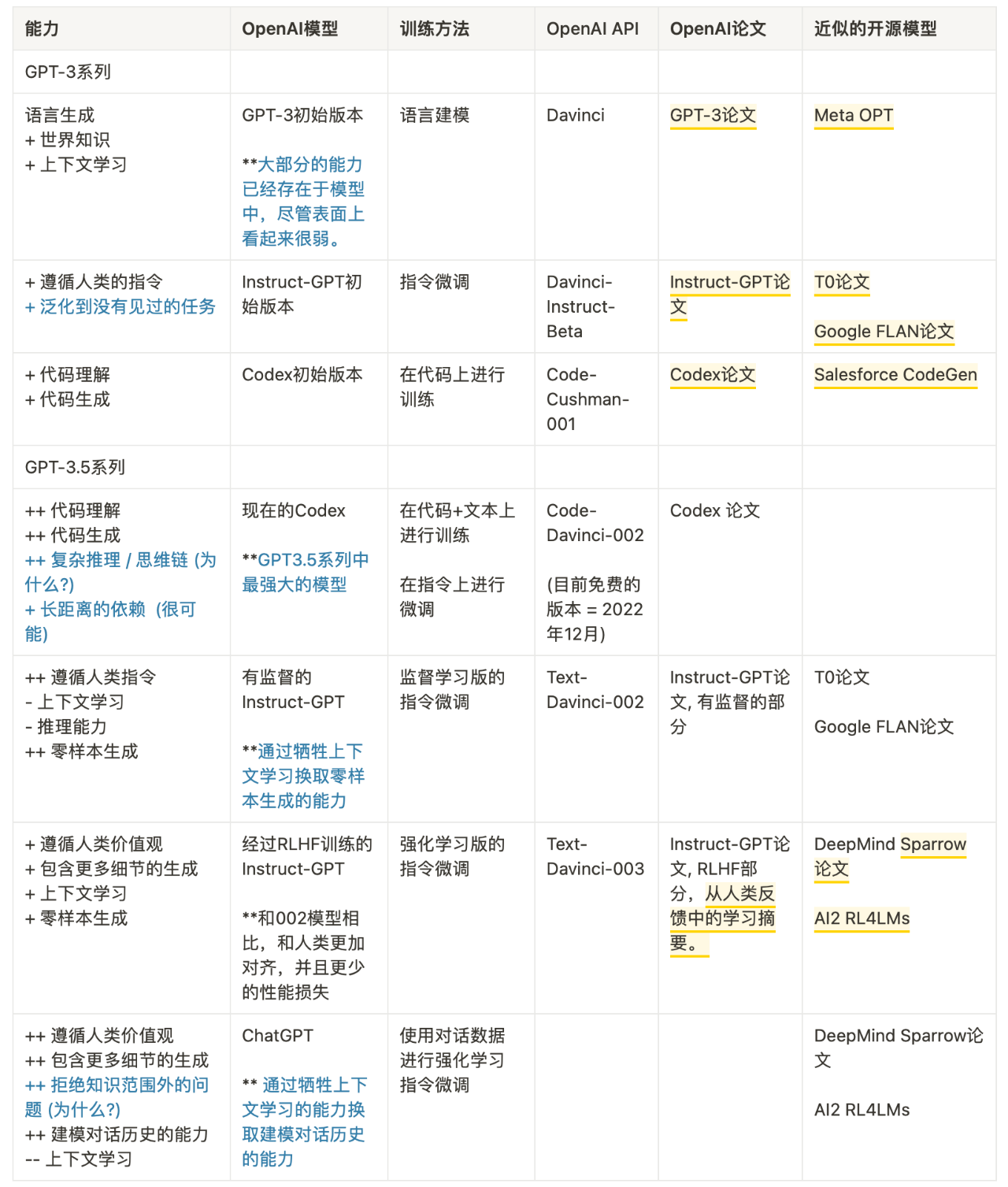
我们可以得出结论:
-
语言生成能力 + 基础世界知识 + 上下文学习都是来自于预训练(
davinci) -
存储大量知识的能力来自 1750 亿的参数量。
-
遵循指令和泛化到新任务的能力来自于扩大指令学习中指令的数量(
Davinci-instruct-beta) -
执行复杂推理的能力很可能来自于代码训练(
code-davinci-002) -
生成中立、客观的能力、安全和翔实的答案来自与人类的对齐。具体来说:
-
如果是监督学习版,得到的模型是
text-davinci-002 -
如果是强化学习版 (RLHF) ,得到的模型是
text-davinci-003 -
无论是有监督还是 RLHF ,模型在很多任务的性能都无法超过 code-davinci-002 ,这种因为对齐而造成性能衰退的现象叫做对齐税。
-
对话能力也来自于 RLHF(
ChatGPT),具体来说它牺牲了上下文学习的能力,来换取: -
建模对话历史
-
增加对话信息量
-
拒绝模型知识范围之外的问题
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢