

-
论文链接:https://arxiv.org/abs/2212.08751
-
项目链接:https://github.com/openai/point-e
简介
文本生成图像的 AI 最近已经火到了圈外,不论是 DALL-E 2、DeepAI 还是 Stable Diffusion,人人都在调用 AI 算法搞绘画艺术,研究对 AI 讲的「咒语」。不断进化的技术推动了文生图生态的蓬勃发展,甚至还催生出了独角兽创业公司 Stability AI。
技术发展的脚步并没有停止,下个突破可能是 3D 模型生成了:本周,OpenAI 开源的 3D 模型生成器 Point-E 引发了 AI 圈的新一轮热潮,刚摆上 GitHub 一天就获得了 800 多个 star。
根据与开源内容一并发布的论文介绍,Point-E 可以在单块 Nvidia V100 GPU 上在一到两分钟内生成 3D 模型。相比之下,现有系统(如谷歌的 DreamFusion)通常需要数小时和多块 GPU。

方法
Point-E 不输出传统意义上的 3D 图像,它会生成点云,或空间中代表 3D 形状的离散数据点集。Point-E 中的 E 是「效率」的缩写,表示其比以前的 3D 对象生成方法更快。不过从计算的角度来看,点云更容易合成,但它们无法捕获对象的细粒度形状或纹理 —— 这是目前 Point-E 的一个关键限制。

在独立的网格生成模型之外,Point-E 主要由两个模型组成:文本到图像模型和图像到 3D 模型。文本到图像模型类似于 OpenAI 自家的 DALL-E 2 和 Stable Diffusion 等生成模型系统,在标记图像上进行训练以理解单词和视觉概念之间的关联。在图像生成之后,图像到 3D 模型被输入一组与 3D 对象配对的图像,训练出在两者之间有效转换的能力。
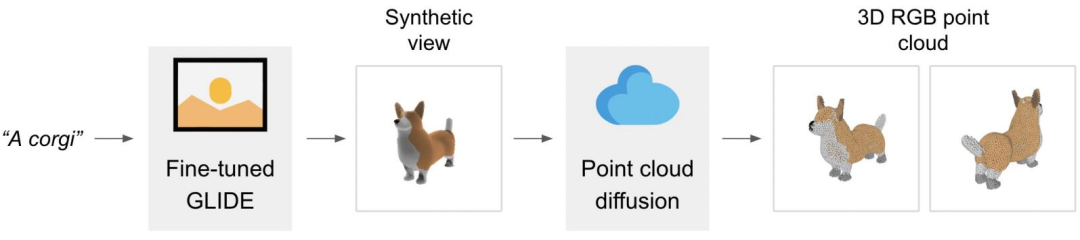
当人们给出一个文本提示 —— 例如,「一个可 3D 打印的齿轮,一个直径为 3 英寸、厚度为半英寸的齿轮」时,AI 会生成符合描述的内容:

Point-E 通过 30 亿参数的 GLIDE 模型生成综合视图渲染,内容被馈送到图像到 3D 模型,通过一系列扩散模型运行生成的图像,以创建初始图像的 3D RGB 点云 —— 先生成粗略的 1024 点云模型,然后生成更精细的 4096 点云模型。
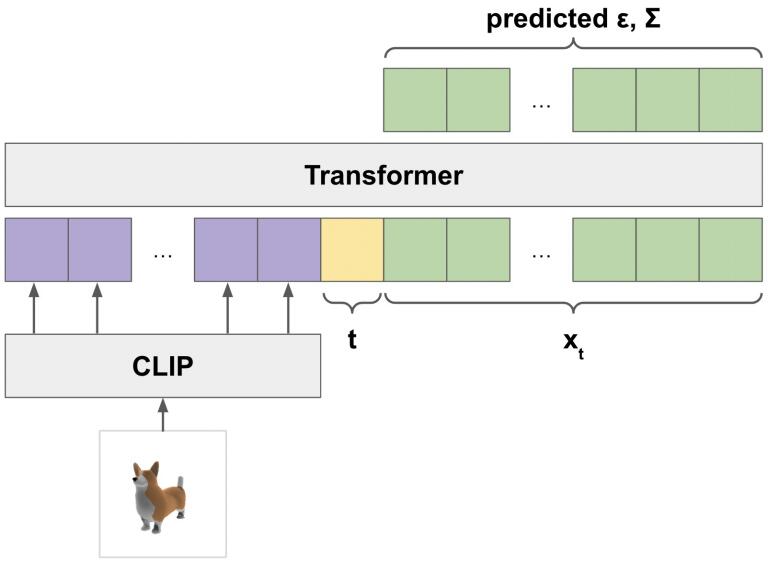
OpenAI 研究人员表示,在经过「数百万 3D 对象和相关元数据的数据集上训练模型后,Point-E 拥有了生成匹配文本提示的彩色点云的能力。Point-E 的问题和目前的生成模型一样,图像到 3D 转换过程中有时无法理解文本叙述的内容,导致生成的形状与文本提示不匹配。尽管如此,根据 OpenAI 团队的说法,它仍然比以前的最先进技术快几个数量级。

OpenAI 在论文中表示,「虽然 Point-E 在评估中表现得比 SOTA 方法差,但它只用了后者一小部分的时间就可以生成样本。这使得 Point-E 对某些应用程序更实用,或者可以利用效率获得更高质量的 3D 对象。」
实验
从生成时间来看,无论是DreamFields、还是DreamFusion,在生成上都需要以小时为单位计数。
其中DreamFields是效果比较好的AI文本生成3D模型,但生成一个模型几乎需要200个V100时(V100连续运行200个小时)。
DreamFusion是DreamFields的进化版,即便如此它也需要12个V100时。
相比之下,Point·E的几个不同大小的模型,基本都以分钟为单位,在1分钟~1.5分钟内就能完成文本生成3D点云模型。
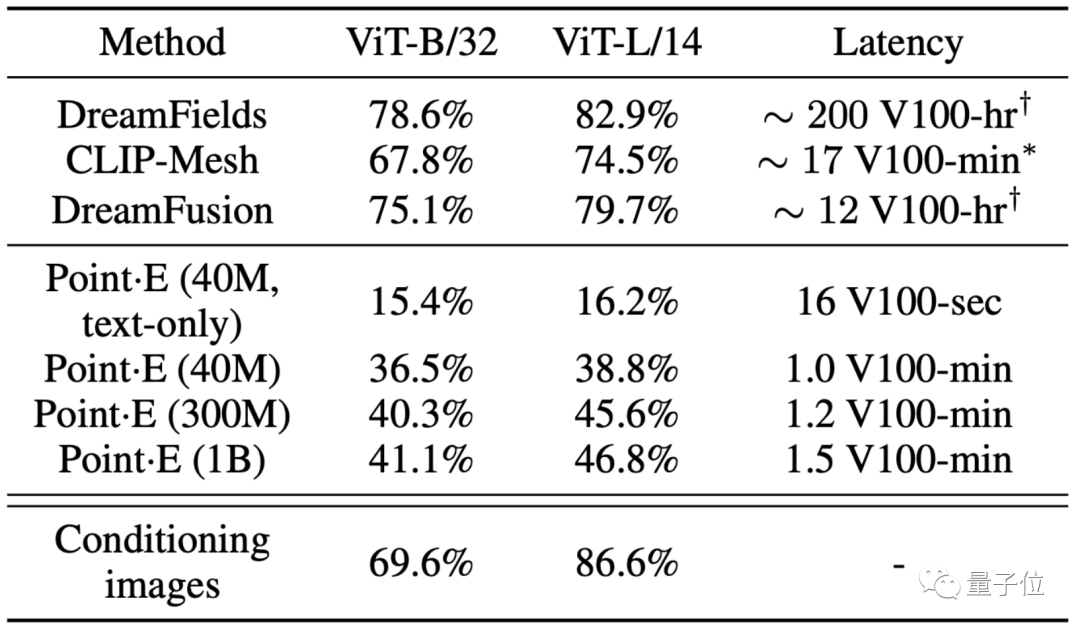
不过,Point·E在生成效果上,还确实不如谷歌的DreamFusion,后者可以直接渲染生成3D模型:

相比之下,作为一个文本生成3D点云AI,Point·E无法像DreamFusion那样用网格(mesh)直接生成3D模型。
在经过渲染前,这些点云需要先完成预处理,经历一个网格化的过程,往往这个过程还需要耗费额外的时间:

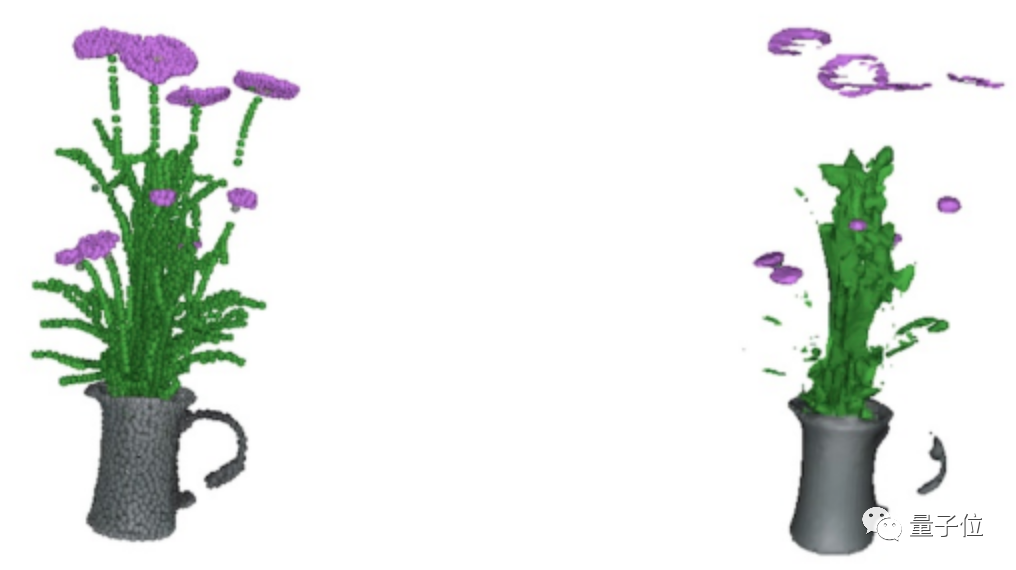
作者也指出了Point·E存在的一些缺点。
一方面,有时候经过预处理,比较稀疏的点云可能会被忽略(例如下图中花的茎秆等地方):
另一方面,从预览图生成点云的过程,有时候也会出bug。例如AI看着预览图,生成了一个完全不匹配的3D点云效果出来:

△超高版柯基和对称雪糕筒
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢