
【论文标题】Noisy Self-Knowledge Distillation for Text Summarization 【作者团队】Yang Liu, Sheng Shen, Mirella Lapata 【发表时间】2020/9/15 【论文链接】https://arxiv.org/abs/2009.07032
【推荐理由】 本文来自UC伯克利+爱丁堡大学联合团队,该论文首次将自知识蒸馏应用于文本摘要任务,以缓解在单索引源和嘈杂数据集上出现的最大似然训练问题。
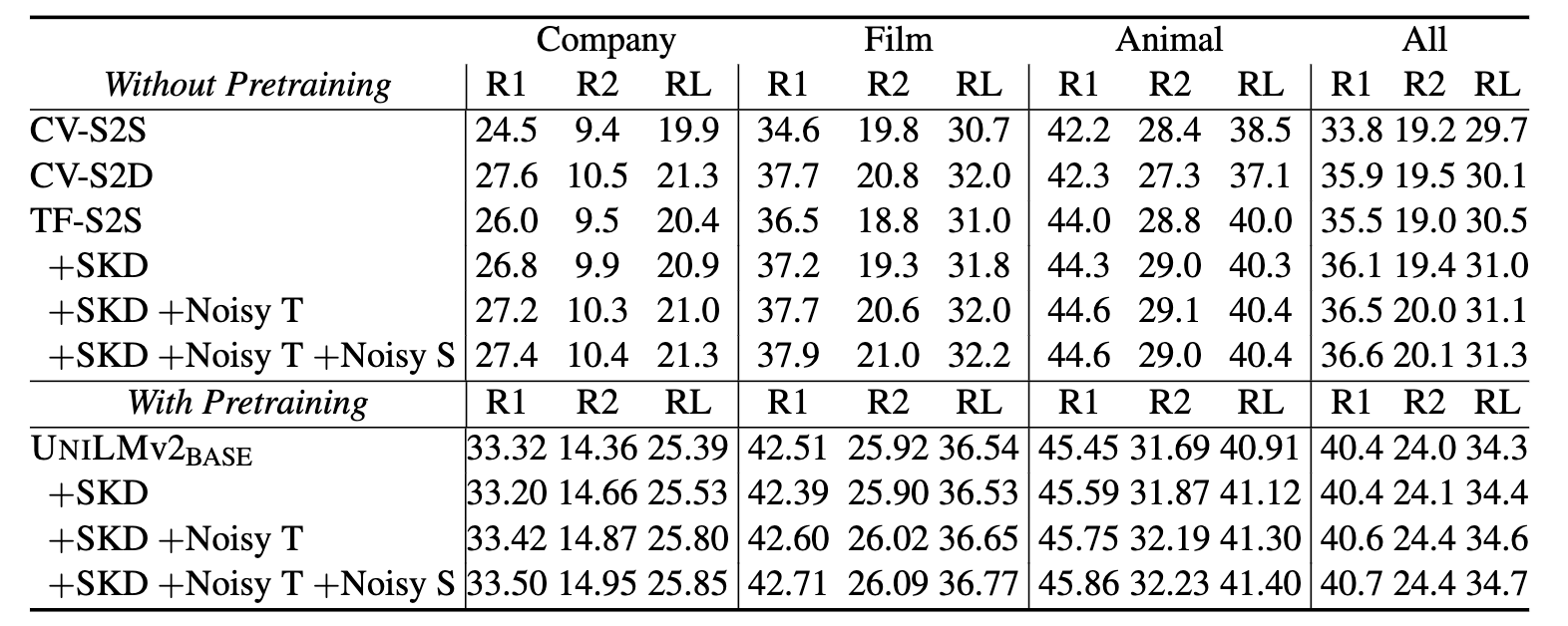
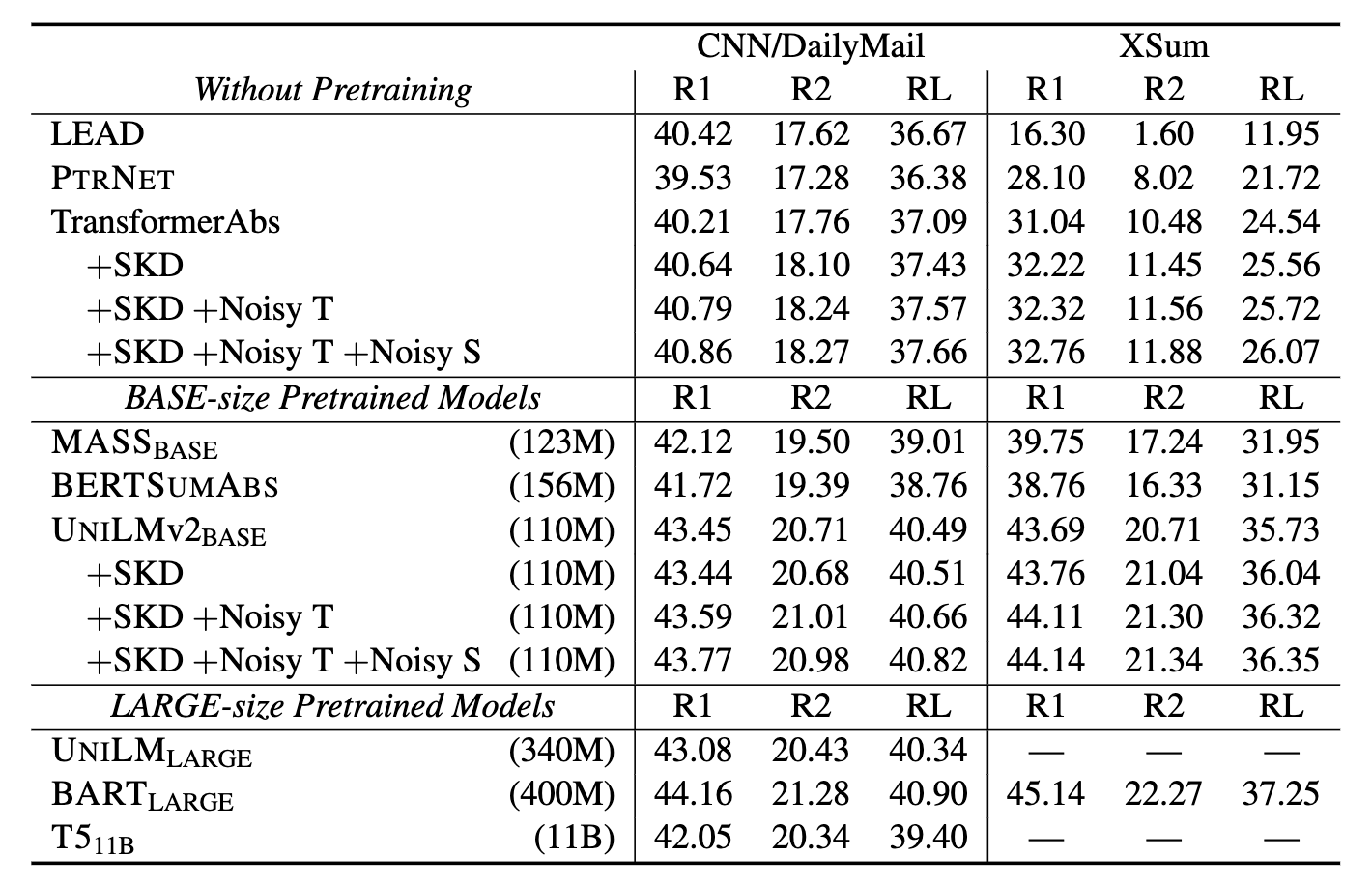
在本文中,作者将自知识蒸馏应用于文本摘要任务,作者认为这可以缓解在单索引源和嘈杂数据集上出现的最大似然训练问题。知识蒸馏是通过训练一个较小的学生模型,使其模仿一个较大的教师模型的输出,达到将知识从教师模型迁移至学生模型的目的。本文的学生摘要模型不是依靠one-hot的注释标签,而是在教师模型的指导下进行训练的。该教师模型通过产生平滑的标签,以帮助规范化训练。此外,为了在训练过程中更好地建模模型的不确定性,作者为教师模型和学生模型引入了多个噪声信号。实验结果证明,在三个基准测试集上,本文的框架可提高预训练和非预训练的摘要生成器的性能,从而获得SOTA的结果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢