
来自今天的爱可可AI前沿推介
[CL] A Length-Extrapolatable Transformer
Y Sun, L Dong, B Patra, S Ma, S Huang, A Benhaim, V Chaudhary, X Song, F Wei
[Microsoft]
长度外推Transformer
要点:
-
总结了Transformer位置建模设计原则; -
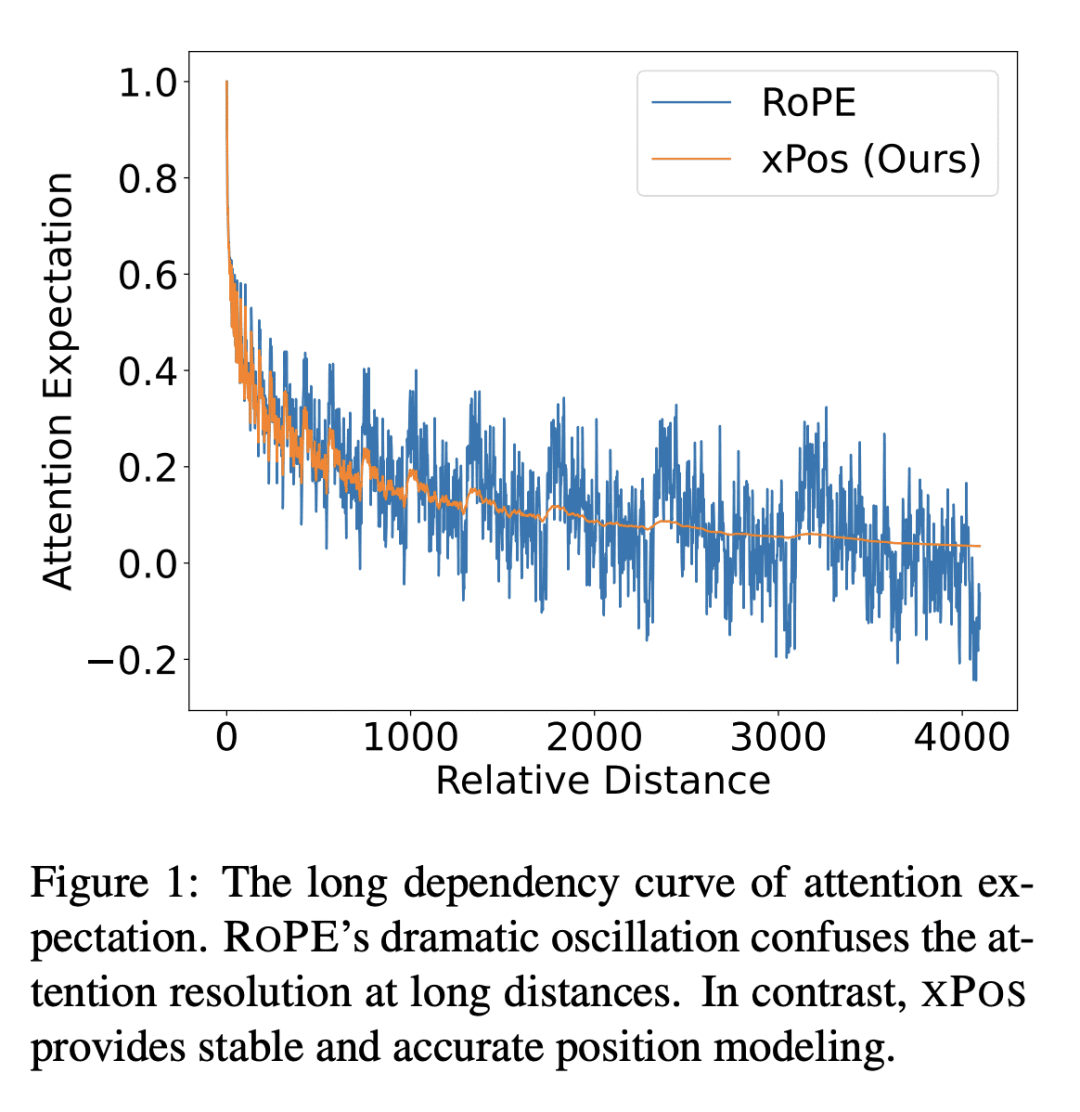
定义注意力分辨率来表示长度外推,即对短文进行训练而在较长序列上评估; -
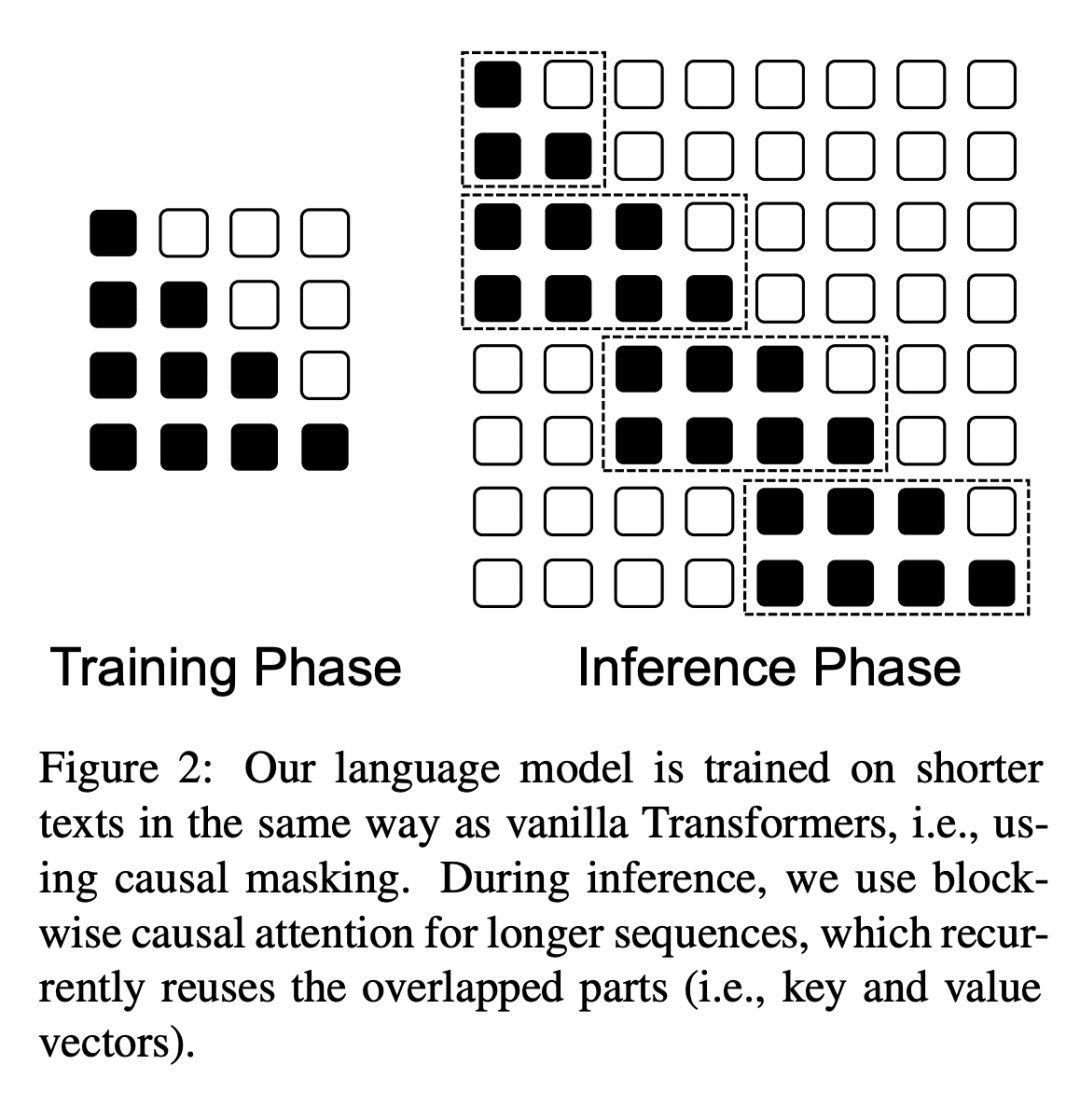
提出一种可外推的位置嵌入,用分块因果注意力来改善长度外推。
摘要:
位置建模在Transformer中起着关键作用。本文专注于长度外推,即对短文进行训练而在较长序列上评估。本文将注意力分辨率定义为外推的一个指标,提出了两个设计来改善Transformer的上述指标。具体的,提出了一个相对位置嵌入来显式最大化注意力分辨率。此外,在推理过程中使用分块的因果注意力来提高分辨率。用语言建模来评估不同的Transformer变体。实验结果表明,所提出模型在插值和外推设置中都取得了强大的性能。
Position modeling plays a critical role in Transformers. In this paper, we focus on length extrapolation, i.e., training on short texts while evaluating longer sequences. We define attention resolution as an indicator of extrapolation. Then we propose two designs to improve the above metric of Transformers. Specifically, we introduce a relative position embedding to explicitly maximize attention resolution. Moreover, we use blockwise causal attention during inference for better resolution. We evaluate different Transformer variants with language modeling. Experimental results show that our model achieves strong performance in both interpolation and extrapolation settings. The code will be available at this https URL.
论文链接:https://arxiv.org/abs/2212.10554
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢