
来自今天的爱可可AI前沿推介
[CL] Self-Instruct: Aligning Language Model with Self Generated Instructions
Y Wang, Y Kordi, S Mishra... [University of Washington & Tehran Polytechnic & Arizona State University & Johns Hopkins University]
Self-Instruct: 基于自生成指令对齐语言模型
要点:
-
提出Self-Instruct框架,通过自生成的指令数据(指令、输入和输出样本)和自引导来改善预训练语言模型的指令执行能力; -
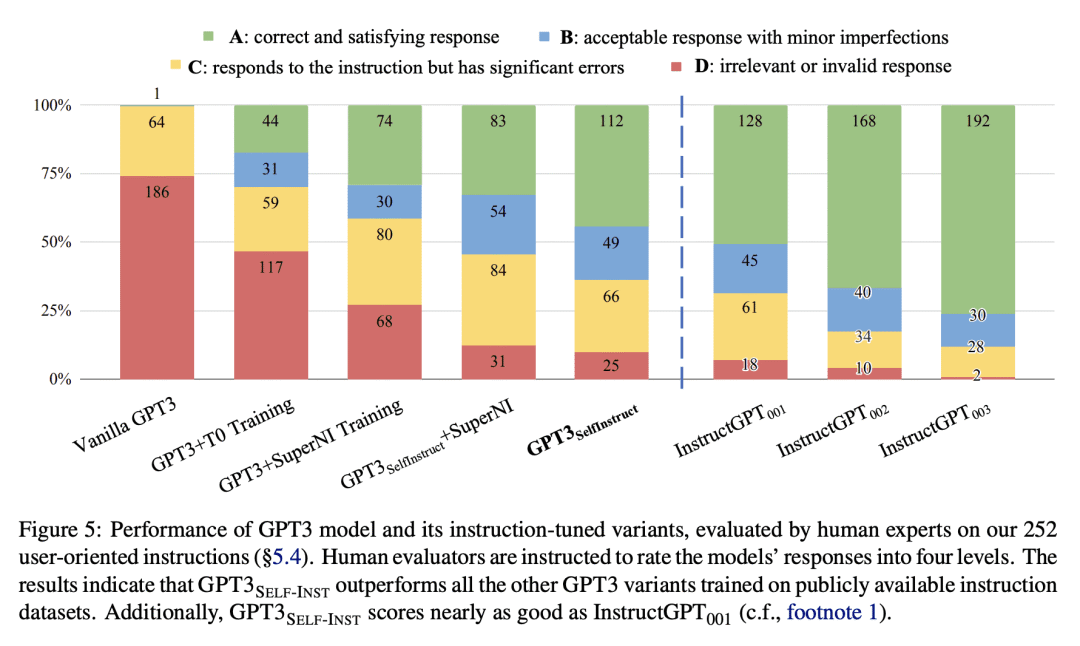
在Super-NaturalInstructions数据集上展示了比原始模型33%的绝对改进,与InstructGPT_001的性能相当,InstructGPT_001使用私有用户数据和人工标注进行训练; -
当对一组专家编写的新任务指令进行评估时,Self-Instruct的表现远远优于现有的开放指令数据集,仅落后InstructGPT_001 5%。
摘要:
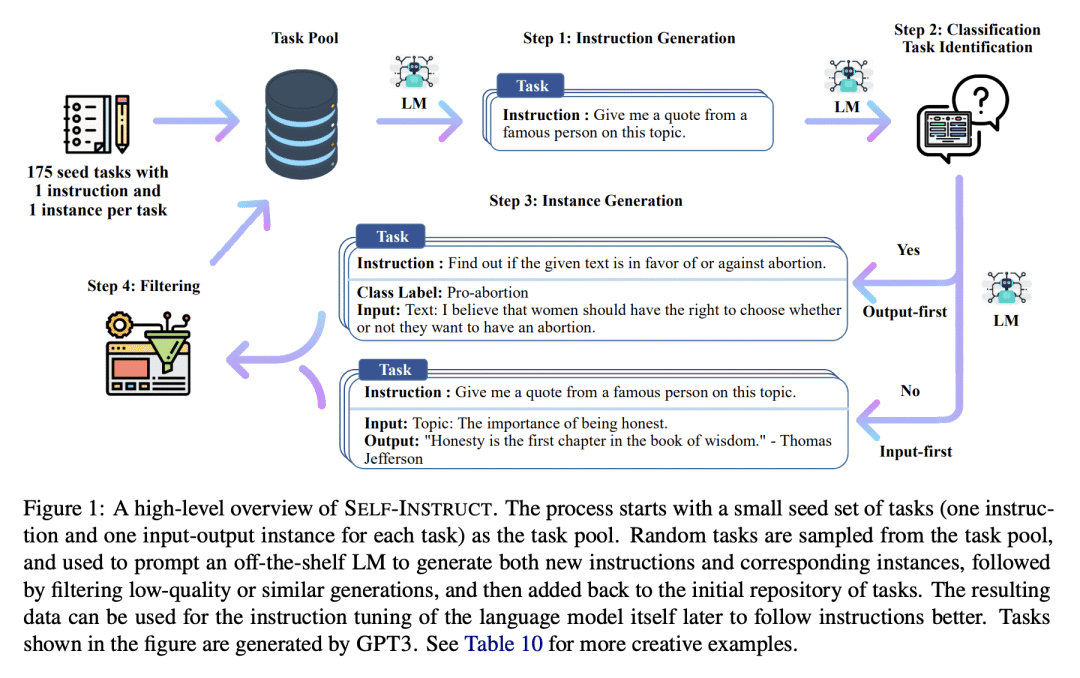
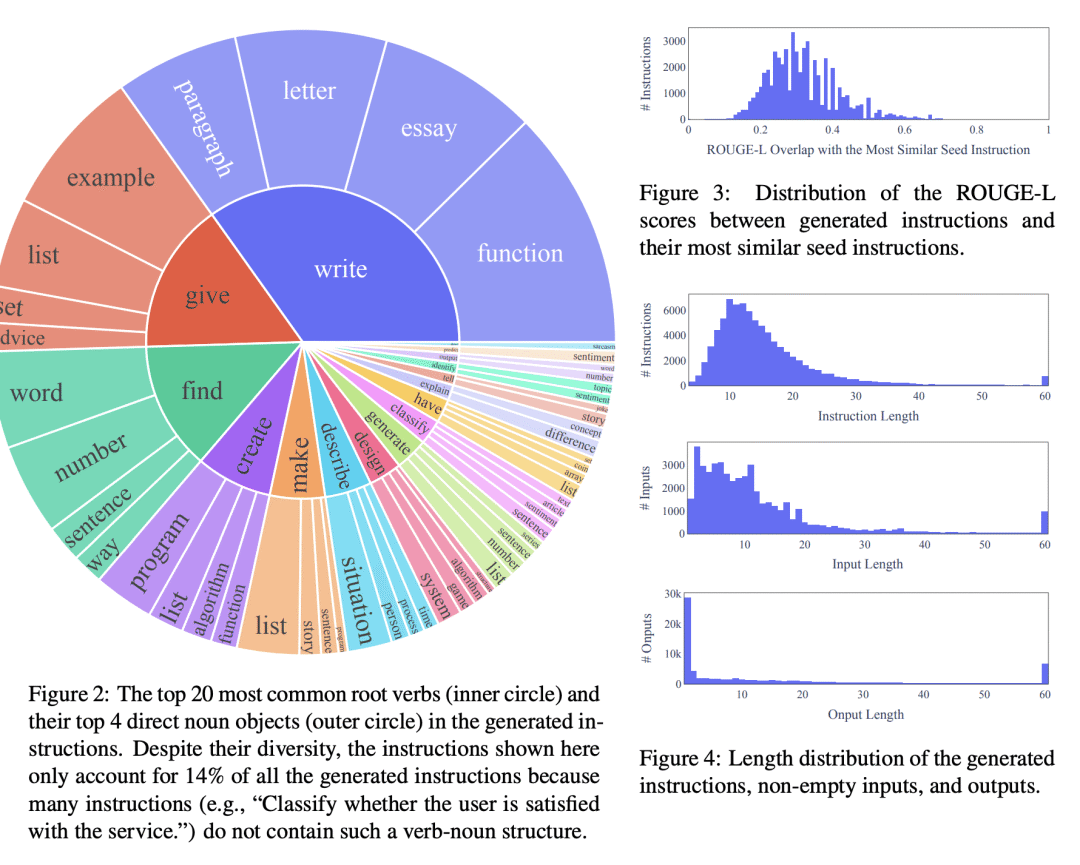
大型“指令微调”语言模型(用于响应指令)展示了零样本泛化到新任务的卓越能力。然而,其严重依赖于人工编写的指令数据,这些数据在数量、多样性和创造性方面受到限制,阻碍了微调模型的通用性。本文提出Self-Instruct,一种通过自己代际提升来提高预训练语言模型指令遵循能力的框架。该管道从语言模型生成指令、输入和输出样本,在用它们微调原始模型之前对其进行修剪。将该方法应用于vanilla GPT3,在Super-NaturalInstructions数据集上展示了比原始模型33%的绝对改进,与InstructGPT_001的性能相当,InstructGPT_001使用私有用户数据和人工标注进行训练。为了进一步评估,为新任务策划了一套专家编写的说明,并通过人工评估表明,使用现有开放指令数据集,用Self-Instruct微调的GPT3优于使用现有开放指令数据集,仅有5%的绝对差距。Self-Instruct提供了一种几乎无标注的方法,用于将预训练的语言模型与指令对齐,本文发布了大型合成数据集,以促进未来对指令调优的研究。
Large "instruction-tuned" language models (finetuned to respond to instructions) have demonstrated a remarkable ability to generalize zero-shot to new tasks. Nevertheless, they depend heavily on human-written instruction data that is limited in quantity, diversity, and creativity, therefore hindering the generality of the tuned model. We introduce Self-Instruct, a framework for improving the instruction-following capabilities of pretrained language models by bootstrapping off its own generations. Our pipeline generates instruction, input, and output samples from a language model, then prunes them before using them to finetune the original model. Applying our method to vanilla GPT3, we demonstrate a 33% absolute improvement over the original model on Super-NaturalInstructions, on par with the performance of InstructGPT_001, which is trained with private user data and human annotations. For further evaluation, we curate a set of expert-written instructions for novel tasks, and show through human evaluation that tuning GPT3 with Self-Instruct outperforms using existing public instruction datasets by a large margin, leaving only a 5% absolute gap behind InstructGPT_001. Self-Instruct provides an almost annotation-free method for aligning pre-trained language models with instructions, and we release our large synthetic dataset to facilitate future studies on instruction tuning.
论文链接:https://arxiv.org/abs/2212.10560
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢