
合成自由视角真实感图像是多媒体领域的一项重要任务。随着高级驾驶辅助系统(ADAS)的发展及其在自动驾驶汽车中的应用,对不同场进行试验成为一项挑战。虽然通过图像到图像的转换方法可以合成出具有照片般真实感的街道场景,但是由于缺乏三维信息,这种方法不能产生连贯的场景。本文提出了一种大规模神经绘制方法来合成自动驾驶场景(READ),使得在PC上通过多种采样方案合成大规模驾驶场景成为可能。为了表示驾驶场景,本文提出了一个渲染网络𝜔−𝑛𝑒𝑡,用于从稀疏点云中学习神经描述子(descriptors)。该模型不仅可以合成逼真的驾驶场景,而且可以对驾驶场景进行拼接和编辑。实验结果表明,该模型在大规模驾驶场景下具有较好的性能。
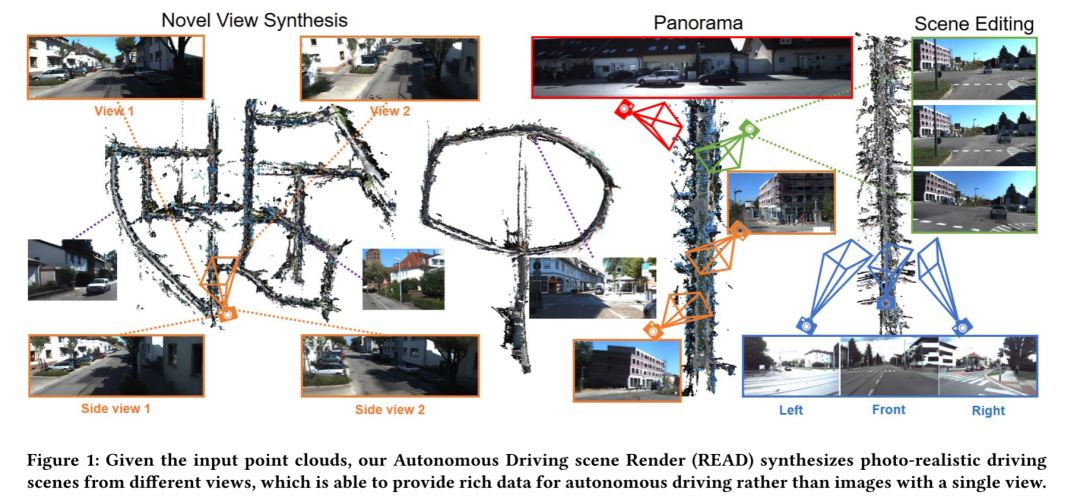
图1:给定输入点云,本文的自动驾驶场景渲染(READ)从不同的视图合成照片真实感驾驶场景,能够为自动驾驶提供丰富的数据,而不是单一视图的图像
论文:https://arxiv.org/pdf/2205.05509.pdf
代码:https://github.com/JOP-Lee/READ-Large-Scale-Neural-Scene-Rendering-for-Autonomous-Driving
介绍
合成自由视角的照片真实感图像是多媒体中的一个重要任务[3]。特别是,合成的大规模街景对于一系列现实世界的应用是必不可少的,包括自动驾驶[12,14]、机器人仿真[6,30]、目标检测[9,35,36]和图像分割[7,25,32]。如图1所示,神经场景绘制的目标是从移动的摄像机合成三维场景,用户可以从不同的视角浏览街道风景,并进行自动驾驶模拟实验。此外,这可以生成多视图图像,为多媒体任务提供数据。
随着自动驾驶的发展,在各种驾驶场景下进行实验具有挑战性。由于复杂的地理位置、多变的环境和道路条件,对室外环境的模拟往往比较困难。此外,很难对一些意外的交通场景进行建模,如车祸,在这些场景中,模拟器可以帮助减少现实差距。然而,像Carla[6]这样被广泛使用的模拟器所生成的数据与使用传统渲染管道的真实世界场景有很大的不同。
基于图像到图像转换的方法[7,10,25,26]通过学习源图像和目标之间的映射来合成带有语义标签的街景。尽管产生了令人鼓舞的街道场景,但仍然存在一些大的人工制品和不连贯的纹理。此外,合成的图像只有单一视图,无法为自动驾驶汽车提供丰富的多视图交通条件。这阻碍了他们大量的现实世界的应用程序。
近年来,基于神经辐射场(NERF)的方法[18,19,29,34]在多视点真实感场景合成方面取得了很好的效果。正如[5]中所建议的,它们不能在只有少量输入视图的情况下产生合理的结果,这通常发生在驾驶场景中,对象只出现在几个帧中。此外,基于NERF的方法主要渲染内部或对象。在复杂的驾驶环境中,大量人工物出现在封闭的视图和周围环境中,很难合成大规模的驾驶场景。为了解决这个问题,NERFW[16]利用额外的深度和分割注释来合成一个室外建筑,使用8个GPU设备需要大约两天的时间。如此长的重建时间主要是由于对广阔的空间进行了不必要的采样。
与纯粹依赖于每个场景拟合的基于NERF的方法不同,神经渲染方法[27,28,31]可以通过神经纹理有效地初始化,神经纹理存储在3D网格代理(3D mesh proxy)的顶部作为地图。类似地,NPBG[2]从原始点云中学习神经描述子,对局部几何和外观进行编码,通过经典点云反映现实世界中场景的几何形状,避免了空场景空间中的样本射线。此外,ADOP[22]改进了NPBG,增加了一个带有色调映射器的可微摄像机模型,引入了更好地近似像素光栅化的空间梯度的公式。一般情况下,基于点的神经绘制方法通过三维点云信息对场景进行初始化,可以用较少的捕获图像合成较大的场景。尽管基于神经绘制的方法可以在室内和室外场景中合成逼真的新颖视图,但由于模型容量的限制,以及内存和计算的限制,在处理大规模驾驶场景时仍然具有很大的挑战性。此外,由于稀疏的点云数据往往含有大量的空洞,因此很难在建筑物、车道、路标等丰富的场景中绘制真实感视图。
本文提出了一种有效的神经场景绘制方法,通过高效的蒙特卡罗采样、大规模点云筛选和 patch 采样,实现了大规模驾驶场景的合成。值得一提的是,本文的方法合成了大规模的驾驶场景,在配备两个RTX2070 GPU的PC上平均训练两天。这极大地降低了计算成本,从而可以在负担得起的硬件上实现大规模场景渲染。对于稀疏点云,通过多尺度特征融合来填补点云的缺失区域。为了从稀疏点云合成真实感驾驶场景,提出了一种𝜔−𝑛𝑒𝑡网络,通过基本门模块过滤神经描述子,并采用不同策略融合相同尺度和不同尺度的特征.通过𝜔−𝑛𝑒𝑡,本文的模型不仅可以合成真实的场景,还通过神经描述子编辑和缝合场景。而且,本文能够更新特定区域,并将它们与原始场景缝合在一起。场景编辑可用于合成来自不同视图的多样驾驶场景数据,甚至用于交通紧急情况。
主要贡献
1)基于本文的神经渲染引擎(READ),构建了一个大规模驾驶仿真环境,为高级驾驶辅助系统生成真实感数据;
2)𝜔−𝑛𝑒𝑡的提出是为了获得更真实、更详细的驾驶场景,其中引入了多种采样策略,以实现对大规模驾驶场景的综合;
3)在KITTI Benchmark[8]和BRNO Urban DataSet[15]上的实验表明,该方法具有良好的定性和定量效果,可以对驾驶场景进行编辑和拼接,从而合成更大、更多样化的驾驶数据。
更多详细内容可参考这里
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢