
来自今天的爱可可AI前沿推介
[LG] Imitation Is Not Enough: Robustifying Imitation with Reinforcement Learning for Challenging Driving Scenarios
Y Lu, J Fu, G Tucker, X Pan, E Bronstein, B Roelofs...
[Waymo Research & Google Research]
仅有模仿还不够: 为挑战驾驶场景用强化学习强化模仿学习
要点:
-
利用大量现实世界的人工驾驶数据在无人驾驶中首次大规模应用模仿学习和强化学习相结合的方法;
2.将模仿学习与强化学习和安全奖励相结合,可以在具有挑战性的场景中提高安全性和可靠性。
摘要:
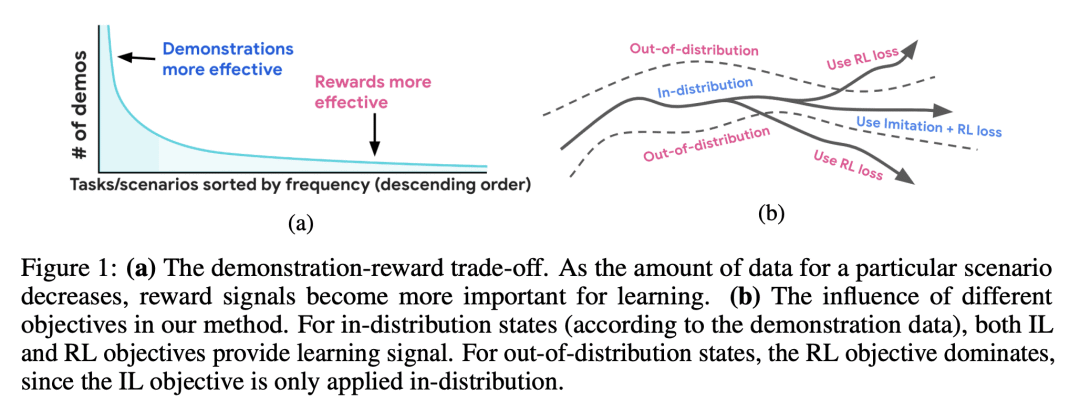
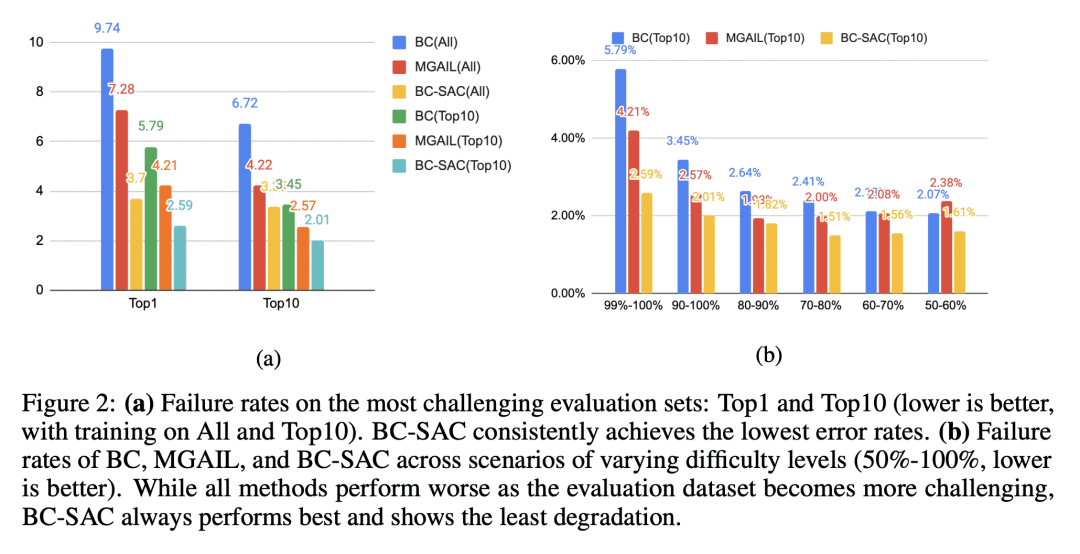
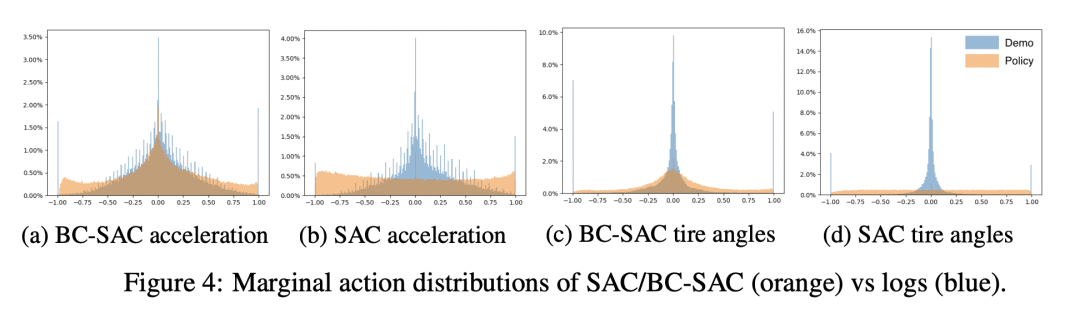
模仿学习(IL)是一种简单而强大的方法,可以大规模收集高质量的人工驾驶数据来识别驾驶偏好并产生类人的驾驶行为。然而,仅基于模仿学习的政策往往无法充分考虑到安全和可靠性问题。本文展示了模仿学习与使用简单奖励的强化学习相结合,如何大大提高驾驶策略的安全性和可靠性,而不是仅从模仿中学到的驾驶策略。特别是,结合使用模仿学习和强化学习来训练超过10万英里的城市驾驶数据的策略,并衡量其在按不同碰撞风险级别分组的测试场景中的有效性。这是首次在无人驾驶中利用大量现实世界人工驾驶数据实现的联合模仿学习和强化学习方法。
Imitation learning (IL) is a simple and powerful way to use high-quality human driving data, which can be collected at scale, to identify driving preferences and produce human-like behavior. However, policies based on imitation learning alone often fail to sufficiently account for safety and reliability concerns. In this paper, we show how imitation learning combined with reinforcement learning using simple rewards can substantially improve the safety and reliability of driving policies over those learned from imitation alone. In particular, we use a combination of imitation and reinforcement learning to train a policy on over 100k miles of urban driving data, and measure its effectiveness in test scenarios grouped by different levels of collision risk. To our knowledge, this is the first application of a combined imitation and reinforcement learning approach in autonomous driving that utilizes large amounts of real-world human driving data.
论文链接:https://arxiv.org/abs/2212.11419
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢