
来自今天的爱可可AI前沿推介
[LG] Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning
P Villalobos, J Sevilla, L Heim...
[University of Aberdeen & MIT & Centre for the Governance of AI & University of Tübingen]
数据会用完吗? ——机器学习可扩展数据集局限分析
要点:
-
预测视觉和语言模型的训练数据集以及未标记数据的总存量的增长; -
语言数据集的增长呈指数级,目前语言数据的存量每年增长7%;
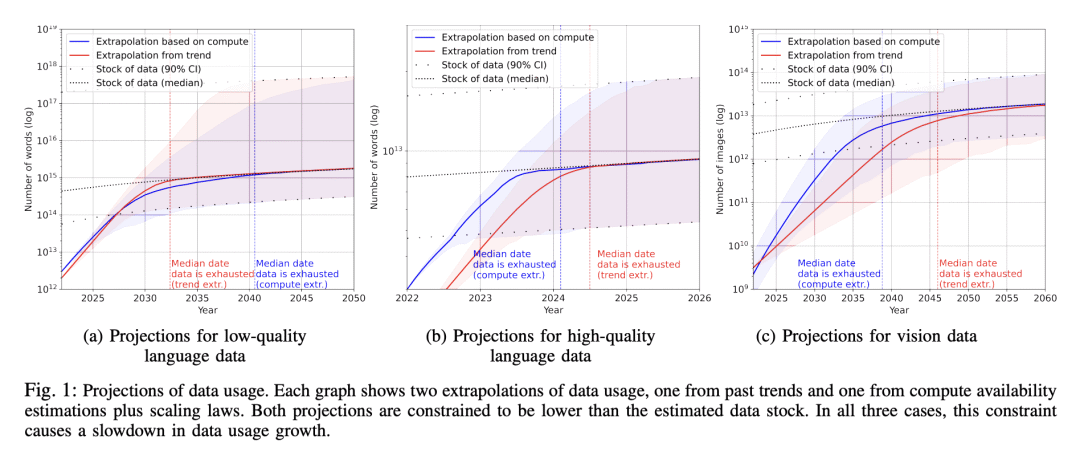
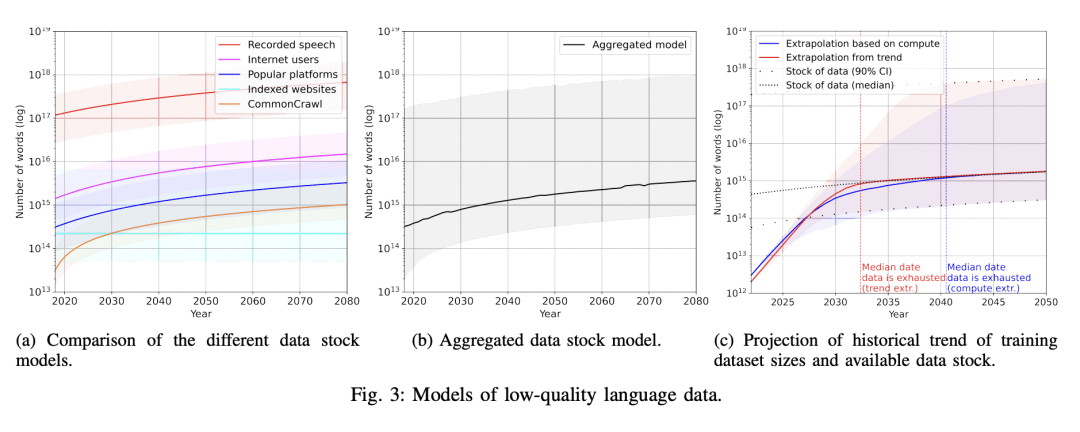
3、 可能会在2030-2050年间耗尽语言数据,高质量的语言数据将在2026年耗尽。
摘要:
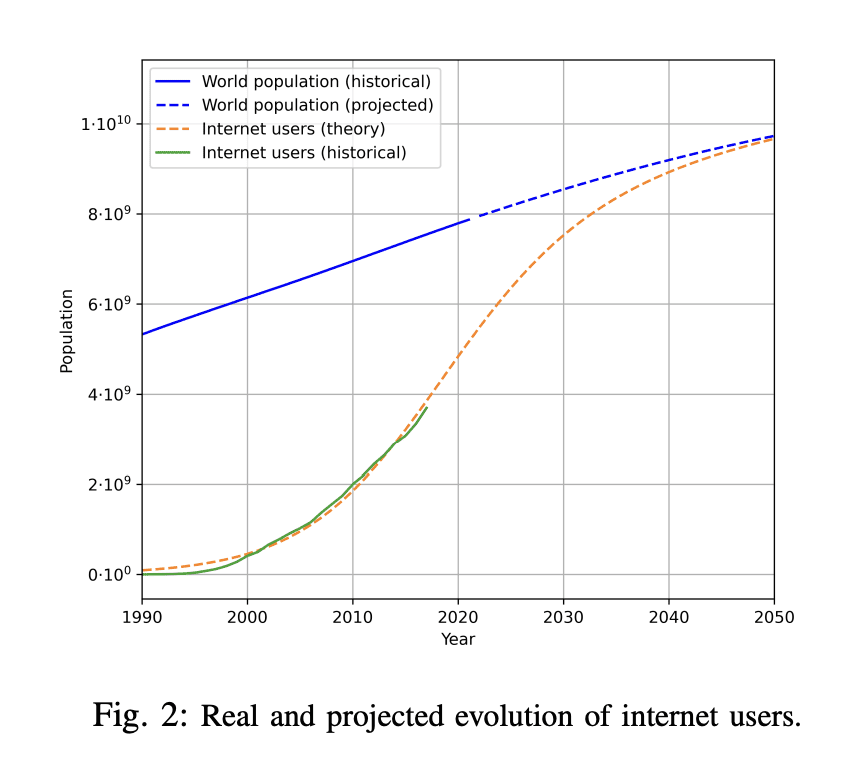
本文分析了机器学习中用于自然语言处理和计算机视觉的数据集大小的增长趋势,用两种方法进行推断:用历史增长率和估计未来预测计算预算的计算最优数据集大小。通过估计未来几十年互联网上可用的无标签数据总存量来调查数据使用量的增长。分析表明,高质量的语言数据存量将很快耗尽;可能在2026年之前。相比之下,低质量语言数据和图像数据的存量会在很久之后耗尽;在2030年至2050年期间(对于低质量语言数据)和在2030年至2060年期间(对于图像数据)。本文工作表明,如果不大幅提高数据效率或获得新的数据来源,依赖大量数据集的机器学习模型的当前趋势可能会放缓。
We analyze the growth of dataset sizes used in machine learning for natural language processing and computer vision, and extrapolate these using two methods; using the historical growth rate and estimating the compute-optimal dataset size for future predicted compute budgets. We investigate the growth in data usage by estimating the total stock of unlabeled data available on the internet over the coming decades. Our analysis indicates that the stock of high-quality language data will be exhausted soon; likely before 2026. By contrast, the stock of low-quality language data and image data will be exhausted only much later; between 2030 and 2050 (for low-quality language) and between 2030 and 2060 (for images). Our work suggests that the current trend of ever-growing ML models that rely on enormous datasets might slow down if data efficiency is not drastically improved or new sources of data become available.
论文链接:https://arxiv.org/abs/2211.04325
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢