
本文提出了 Imagen,它使用大型变换器语言模型和扩散模型来生成文本到图像。主要发现是使用仅在文本数据上预训练的大型语言模型作为文本编码器是有效的。提出了动态阈值化和高效 U-Net 架构,以提高扩散模型的训练效果和效率。
标题:Imagen:Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
作者:Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, Mohammad Norouzi
原文链接:http://export.arxiv.org/abs/2205.11487
代码链接:https://github.com/Alpha-VL/ConvMAE
Multimodal learning 最近比较火,有text-to-image synthesis(DALL-E, Stable Diffusion)和image-text contrastive learning (CLIP),都成为了最近关注度超级高的领域。这些模型改变了研究界思考的模式:语言信号在视觉表征学习中,究竟可以充当什么样的角色?同时并通过创意图像生成和编辑图像的这些工作,使得AI帮助人类进行艺术创作提供了可能,造成了很强的出圈效果,引起了广泛的公众关注。为了进一步追求这个研究方向,Google引入了Imagen,一种结合了 Transformer 语言模型 (LM) 的强大功能的文本到图像扩散模型和high- resolution的Diffusion Models,在文本到图像合成中提供前所未有的照片级真实感和深度语言理解。与仅使用图像文本数据进行模型训练的先前工作相比,Imagen背后的关键发现是来自大型 LMs 的文本embedding在纯文本语料库上预训练,对于文本到图像的合成非常有效。这其实重塑了大家对视觉语言学习的认知。因为大家往往会觉得视觉-语言里的语言信息,和纯文本语料里的语言信息,是存在domain的gap的,但这份基于bert的工作给大家的研究提供了全新的思路。
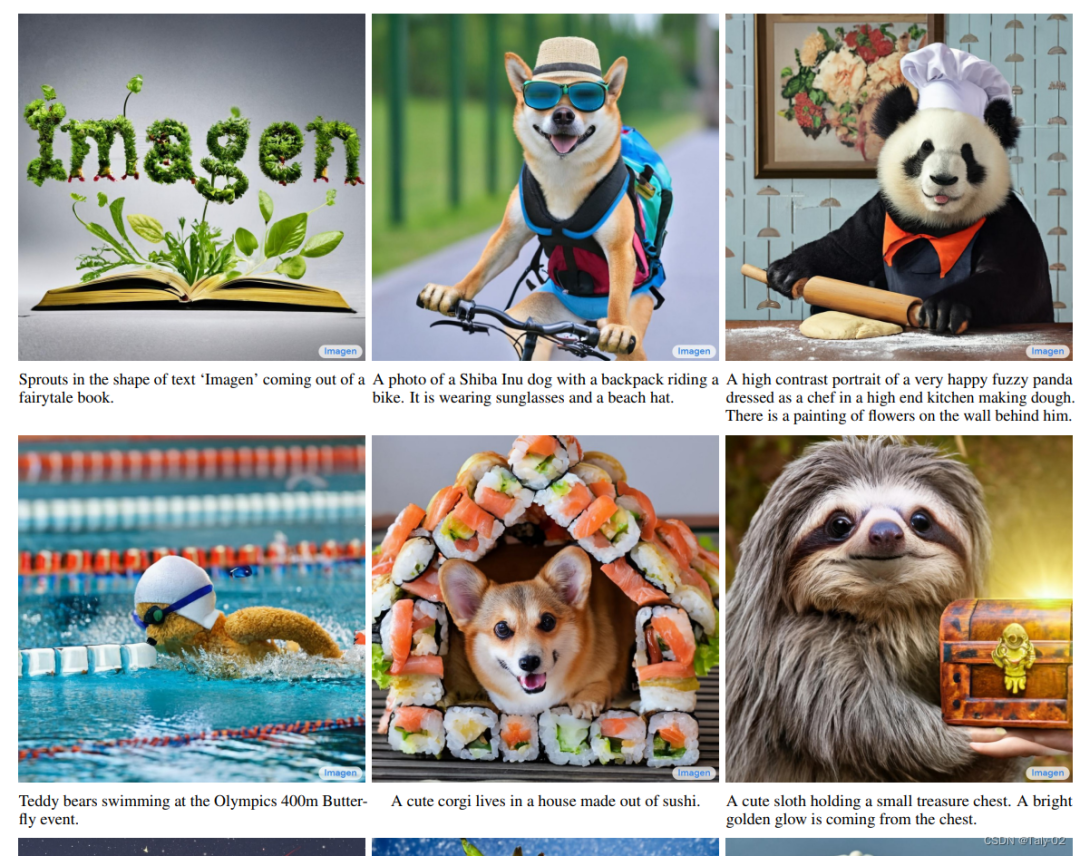
具体来讲,Imagen包含一个冻结的 T5-XXL的文本编码器,用于将输入文本映射到一系列嵌入和一个 图像扩散模型,然后是两个超分辨率扩散 生成 和 图像的模型。所有扩散模型都以文本嵌入序列为条件,摆脱了classifier的guidance。Imagen依赖于新的采样技术,允许使用大的引导权重,所以不会像原有工作一样带来样本质量下降,从而使得图像具有比以前更高的保真度,并且更好地完成图像-文本对齐。虽然概念上简单且易于训练,但Imagen 产生了令人惊讶的强大结果。此外,人主观的评价可以看出,从 Imagen生成的样本在图像文本对齐方面与 COCO 字幕上的参考图像相当。
同时,论文还引入了DrawBench,这是一套用于文本到图像评估的新结构化文本提示。DrawBench通过文本到图像的多维评估实现更深入的洞察模型,带有旨在探测模型不同语义属性的文本提示。这些包括组合性、基数、空间关系、处理复杂文本提示或带有罕见词的提示的能力,并且它们包括创造性提示,这些提示将模型的能力极限推向训练数据范围之外生成高度难以置信的场景的能力。使用DrawBench,经过广泛的人类主观评估,可以得出结论:Imagen的性能明显优于其他同期工作。
该论文的主要贡献包括:
我们发现,仅在文本数据上训练的大型冻结语言模型对于文本到图像的生成是非常有效的文本编码器,并且缩放冻结文本编码器的大小比缩放图像扩散模型的大小更能显着提高样本质量 .
我们引入dynamic thresholding(动态阈值),一个新的扩散采样技术可利用高引导权重并生成比以前更逼真和更详细的图像。
我们强调了几个重要的扩散架构设计选择,并提出了Efficient U-Net,这是一种新的架构变体,它更简单、收敛速度更快并且内存效率更高。
我们引入了DrawBench,这是一个针对文本到图像任务的新的综合且具有挑战性的评估基准。在DrawBench(图像生成领域一个重要的benchmark,涉及到人自主的评估)评估中,我们发现Imagen优于所有其他工作,包括OpenAI引起巨大轰动的DALL-E 2。
本文转自GiantPandaCV,阅读原文请点击这里
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢