基于机器学习的模型可以实现准确、快速的分子特性预测,这对药物发现和材料设计很有意义。各种有监督的机器学习模型已经证明了有前途的性能,但是广阔的化学空间和有限的属性标签使监督学习具有挑战性。
最近,在大型无标签语料库上预训练的无监督基于 transformer 的语言模型在许多下游自然语言处理任务中产生了最先进的结果。
受此启发,来自美国 IBM 研究院的研究人员提出了通过训练高效的 transformer 编码器模型 MOLFORMER 获得的分子嵌入,该模型使用旋转位置嵌入。该模型对来自 PubChem 和 ZINC 数据集的 11 亿个未标记分子的 SMILES 序列采用线性注意机制,并结合高度分布式训练。
研究表明,在来自十个基准数据集的几个下游任务上,学习到的分子表示优于现有基线,包括监督和自我监督的图神经网络和语言模型。进一步的分析,特别是通过注意力的镜头,表明经过化学 SMILES 训练的 MOLFORMER 确实学习了分子内原子之间的空间关系。这些结果提供了令人鼓舞的证据,表明大规模分子语言模型可以捕获足够的化学和结构信息来预测各种不同的分子特性,包括量子化学特性。
该研究以「Large-scale chemical language representations capture molecular structure and properties」为题,于 2022 年 12 月 21 日发布在《Nature Machine Intelligence》上。
![]() 论文链接:https://www.nature.com/articles/s42256-022-00580-7
论文链接:https://www.nature.com/articles/s42256-022-00580-7
机器学习 (ML) 已成为一种有吸引力的、计算效率高的预测分子特性的方法,对药物发现和材料工程具有重要意义。分子的 ML 模型可以直接在预定义的化学描述符上进行训练。然而,最近的 ML 模型侧重于从编码连接信息的自然图或分子结构的线注释中自动学习特征,例如流行的 SMILES 表示。
SMILES 学习已被广泛用于分子特性预测。然而,SMILES 语法复杂且有限制;适当字符集上的大多数序列不属于明确定义的分子。
用于分子特性预测的 GNN 和语言模型的监督训练面临的一个挑战是标记数据的稀缺性。分子的标签注释通常很昂贵,而且由需要注释的似是而非的化学物质组成的空间的大小是天文数字(10^60 到 10^100),这一事实使这个问题更加复杂。
这种情况产生了对分子表示学习的需求,这种学习可以推广到非/自我监督环境中的各种属性预测任务。基于大型 transformer 基础模型的成功,使用学习任务不可知语言表示的范例,通过对大型未标记语料库进行预训练并随后将其用于对感兴趣的下游任务进行微调,已扩展到其他领域。
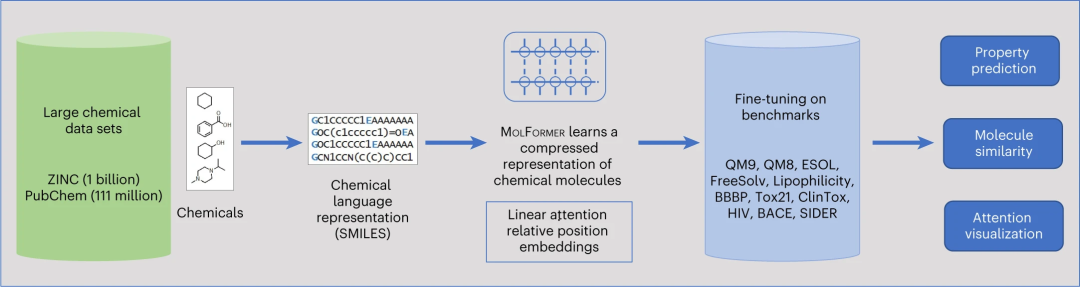
MOLFORMER 管道概览
用于预测分子特性的预训练语言模型和 GNN 最近才开始出现。然而,在数十亿个分子的大型语料库上训练的预训练语言模型在多大程度上能够捕获各种下游任务中的分子-属性关系仍未得到探索。
在此,研究人员提出了称为 MOLFORMER(分子语言 transformer)的分子 SMILES transformer 模型。将性能最佳的 MOLFORMER 变体命名为 MOLFORMER-XL。MOLFORMER-XL 是使用在 11 亿个分子的大型语料库上训练的有效线性注意机制获得的。
结果表明,分子 SMILES 的预训练 transformer 编码器在预测各种分子特性(包括量子力学特性)方面与现有的监督或无监督语言模型和 GNN 基线相比具有竞争力。
内容中包含的图片若涉及版权问题,请及时与我们联系删除



评论
沙发等你来抢