
来自今天的爱可可AI前沿推介
[CL] Optimizing Prompts for Text-to-Image Generation
Y Hao, Z Chi, L Dong, F Wei
[Microsoft Research]
文本到图像生成的提示优化
要点:
-
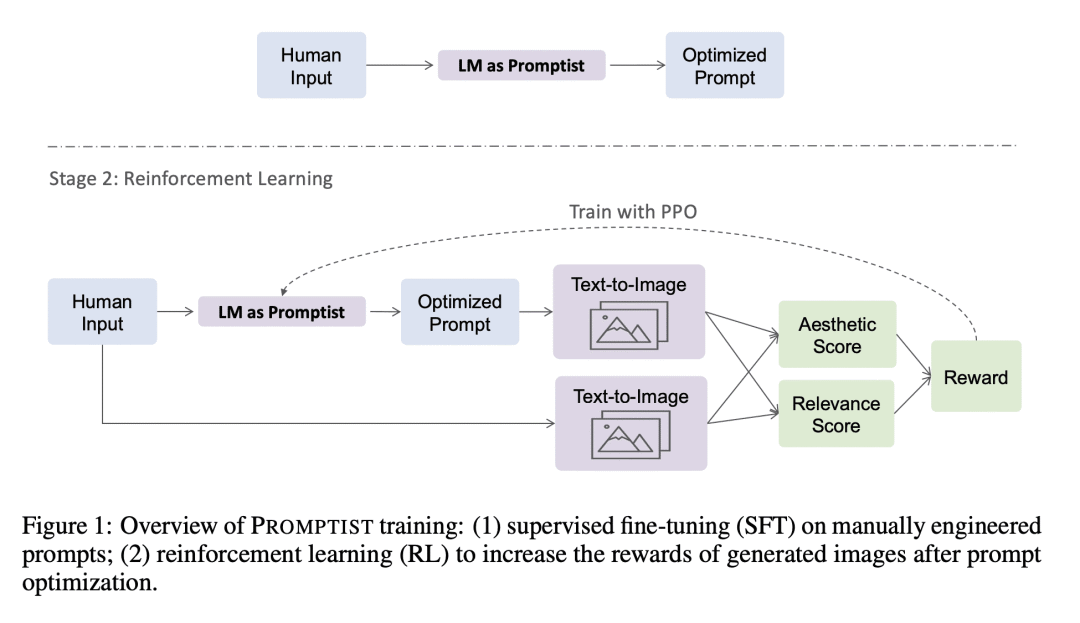
提出一种提示自适应框架,用于自动将用户输入调整为模型首选的提示; -
用预训练语言模型监督微调加强化学习来探索保留用户意图的最优提示; -
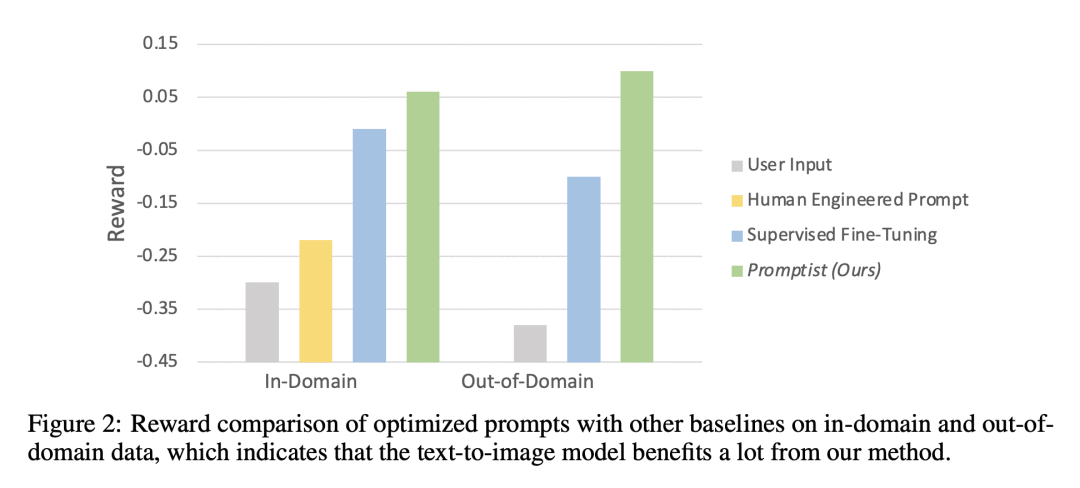
实验结果表明,该方法在自动度量和人工偏好评级方面优于手动提示工程。
摘要:
精心设计的提示,可以引导文本到图像模型生成令人惊叹的图像。然而,好的提示通常是特定于模型的,并且与用户输入不匹配。本文建议的不是费力的人工工程,而是快速自适应,这是一个将原始用户输入自动调整到模型首选提示的一般框架。首先在一小部分手动设计的提示上使用预训练的语言模型进行监督微调。用强化学习来探索更好的提示。定义了一个奖励函数,鼓励策略生成更美观的图像,同时保留原始用户意图。Stable Diffusion上的实验结果表明,该方法在自动度量和人工偏好评级方面都优于手动即时工程。此外,强化学习进一步提高了性能,特别是在域外提示下。
Well-designed prompts can guide text-to-image models to generate amazing images. However, the performant prompts are often model-specific and misaligned with user input. Instead of laborious human engineering, we propose prompt adaptation, a general framework that automatically adapts original user input to model-preferred prompts. Specifically, we first perform supervised fine-tuning with a pretrained language model on a small collection of manually engineered prompts. Then we use reinforcement learning to explore better prompts. We define a reward function that encourages the policy to generate more aesthetically pleasing images while preserving the original user intentions. Experimental results on Stable Diffusion show that our method outperforms manual prompt engineering in terms of both automatic metrics and human preference ratings. Moreover, reinforcement learning further boosts performance, especially on out-of-domain prompts. The pretrained checkpoints are available at this https URL. The demo can be found at this https URL.
论文链接:https://arxiv.org/abs/2212.09611

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢