
来自今天的爱可可AI前沿推介
[CL] Beyond Contrastive Learning: A Variational Generative Model for Multilingual Retrieval
J Wieting, J H. Clark, W W. Cohen, G Neubig...
[Google Research & CMU & University of California San Diego, San Diego]
超越对比学习:面向多语言检索的变分生成模型
要点:
-
提出一种生成模型,用于学习多语言文本嵌入,可用于检索或句对评分; -
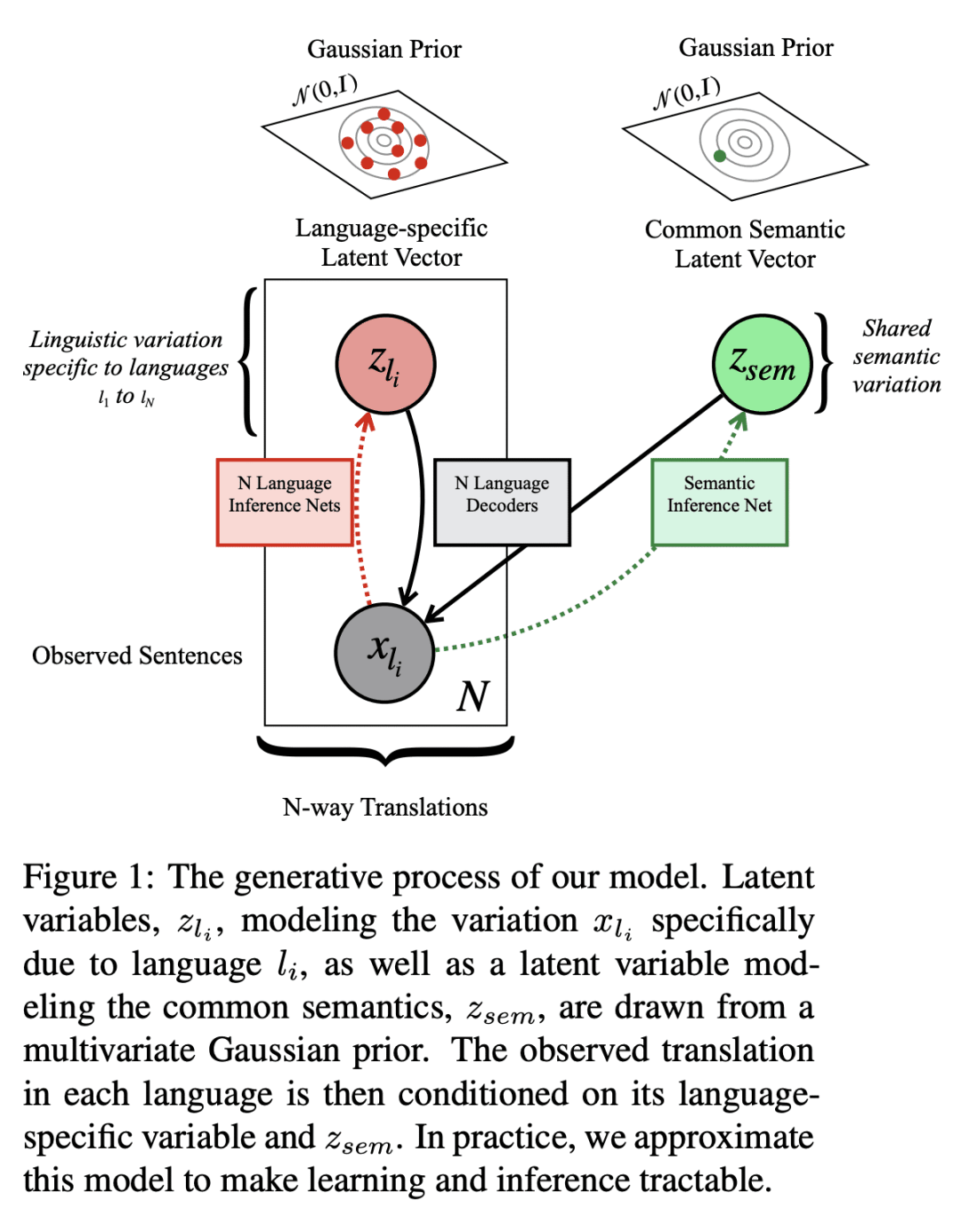
该模型有效鼓励了这种多语言环境中的源分离,将翻译间共享的语义信息与文体或语言特定的变化区分开来; -
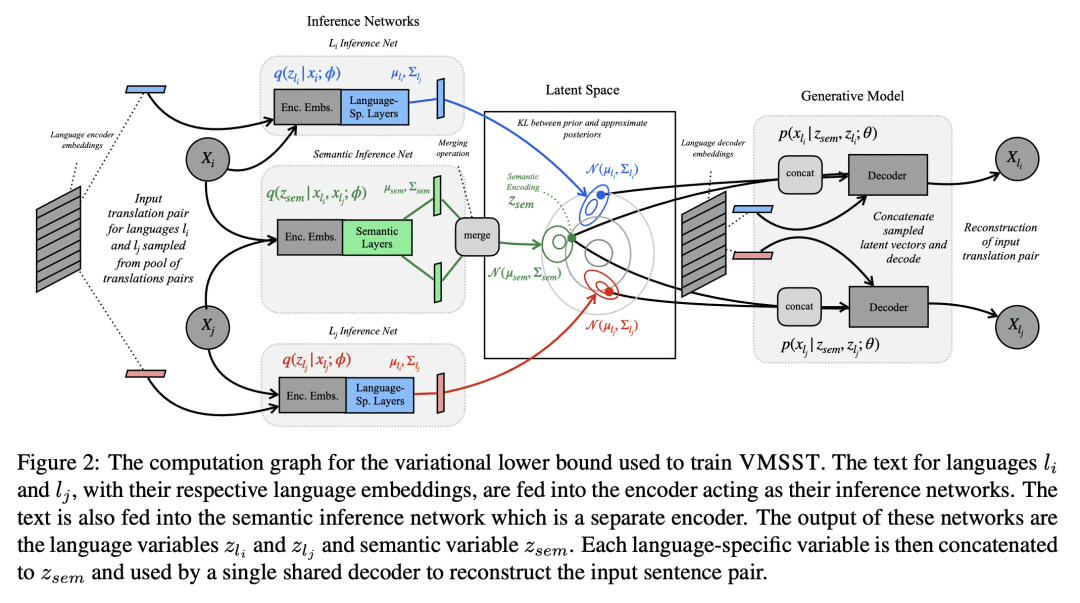
提出VMSST,一种生成式大规模多语言文本嵌入模型,旨在将语义信息与语言特定信息分离。
摘要:
对比学习已成功用于检索语义对齐的句子,但它通常需要大的批量大小或仔细的工程才能正常工作。本文提出一种用于学习多语言文本嵌入的生成模型,可用于检索或句对评分。该模型对N种语言的并行数据进行操作,并通过本文提出的近似值,有效地鼓励在这种多语言环境中进行源分离,将翻译之间共享的语义信息与文体或特定语言变化分开。本文在学习多语种文本嵌入的对比和基于代际的方法之间进行了仔细的大规模比较,尽管这些方法很受欢迎,但这种比较尚未尽得到深入理解。本文在一系列任务上评估了这种方法,包括语义相似性、双文挖掘和跨语言问题检索——最后一项任务是本文提出的。总体而言,本文提出的变分多语言源分离Transformer(VMSST)模型在这些任务上的表现优于强大的对比和生成基线。
Contrastive learning has been successfully used for retrieval of semantically aligned sentences, but it often requires large batch sizes or careful engineering to work well. In this paper, we instead propose a generative model for learning multilingual text embeddings which can be used to retrieve or score sentence pairs. Our model operates on parallel data in N languages and, through an approximation we introduce, efficiently encourages source separation in this multilingual setting, separating semantic information that is shared between translations from stylistic or language-specific variation. We show careful large-scale comparisons between contrastive and generation-based approaches for learning multilingual text embeddings, a comparison that has not been done to the best of our knowledge despite the popularity of these approaches. We evaluate this method on a suite of tasks including semantic similarity, bitext mining, and cross-lingual question retrieval -- the last of which we introduce in this paper. Overall, our Variational Multilingual Source-Separation Transformer (VMSST) model outperforms both a strong contrastive and generative baseline on these tasks.
论文链接:https://arxiv.org/abs/2212.10726
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢