
本文转自今日爱可可前沿推介
[CL] Large Language Models Encode Clinical Knowledge
K Singhal, S Azizi, T Tu, S. S Mahdavi, J Wei, H W Chung, N Scales…
[Google Research & DeepMind]
用大型语言模型编码临床知识
要点:
-
大型语言模型已经显示出在医疗和临床领域应用的潜力,但缺乏标准化的评估框架;
-
提出 MultiMedQA 和 HealthSearchQA,两个新的基准,用于评估模型预测和推理;
-
提出一个指引框架,用于从多个维度对模型答案进行人工评估;
-
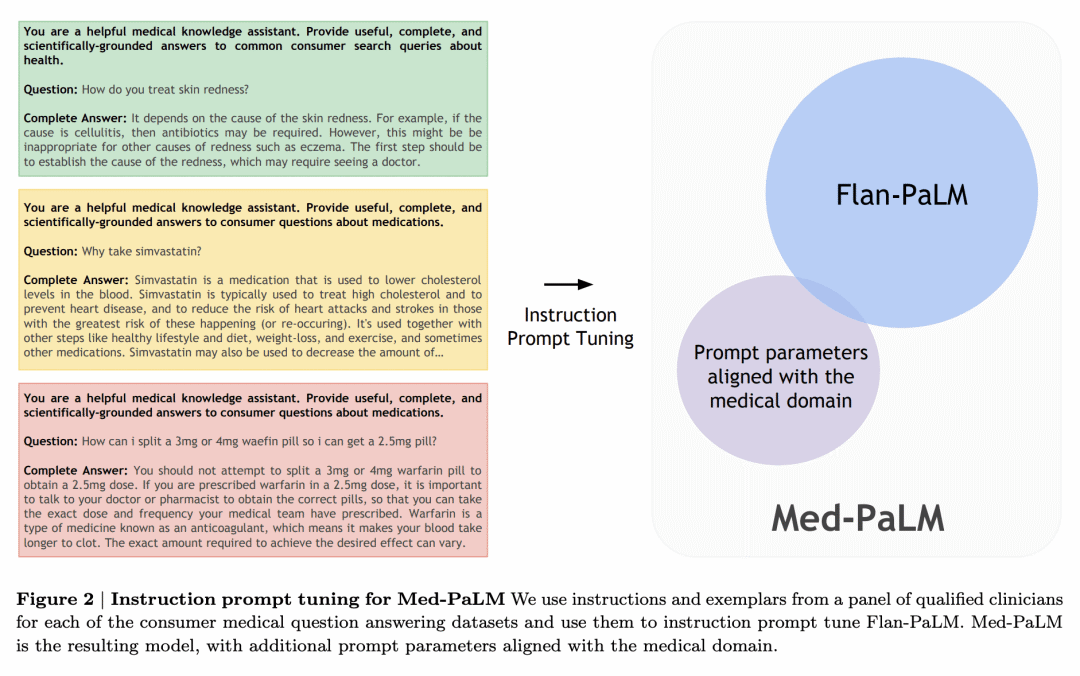
提出指令提示微调,一种参数高效方法,用于用几个例子将LLM与新域对齐。
摘要:
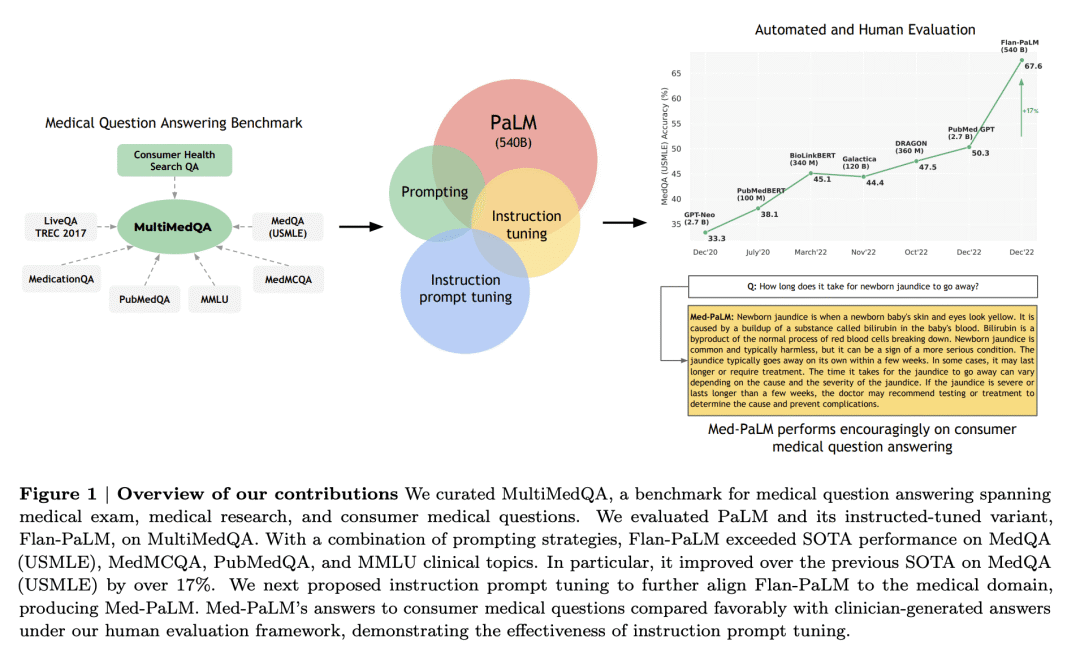
大型语言模型(LLM)在自然语言理解和生成方面表现出令人印象深刻的能力,但医疗和临床应用的质量要求非常之高。如今,评估模型临床知识的尝试,通常依赖于对有限基准的自动评估。没有标准来评估跨范围任务的模型预测和推理。为了解决这个问题,本文提出MultiMedQA,一个结合了涵盖专业医学考试、研究和消费者查询的六个现有开放式问答数据集的基准;以及HealthSearchQA,一个在线搜索的新的免费医疗问题数据集。本文提出一个从多个维度对模型答案进行人工评估的框架,包括事实性、准确性、可能的伤害和偏见。此外,本文在MultiMedQA上评估了PaLM(5.4亿参数LLM)及其指令微调变体Flan-PaLM。
使用一系列提示策略,Flan-PaLM在每个MultiMedQA多选择数据集(MedQA、MedMCQA、PubMedQA、MMLU临床主题)上实现了最先进的准确性,包括MedQA(美国医疗执照考试问题)的67.6%的准确性,比之前的最新数据集高出17%以上。然而,人工评估揭示了Flan-PaLM应对措施中的关键差距。为解决这个问题,本文提出指令提示微调,一种参数高效方法,用于用几个例子将LLM与新域对齐。由此产生的模型Med-PaLM表现令人鼓舞,但仍然不如临床医生。随着模型规模和指令提示微调,对知识的理解、回忆和医学推理有所提高,这表明LLM在医学中的应用潜力。人工评估揭示了当下模型的重要局限性,强化了评估框架和方法开发在为临床应用创建安全、有用的LLM模型方面的重要性。
论文地址:https://arxiv.org/abs/2212.13138

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢