
论文标题:VTC-LFC: Vision Transformer Compression with Low-Frequency Components
论文链接:https://openreview.net/forum?id=HuiLIB6EaOk
代码链接:https://github.com/Daner-Wang/VTC-LFC
作者单位:阿里巴巴
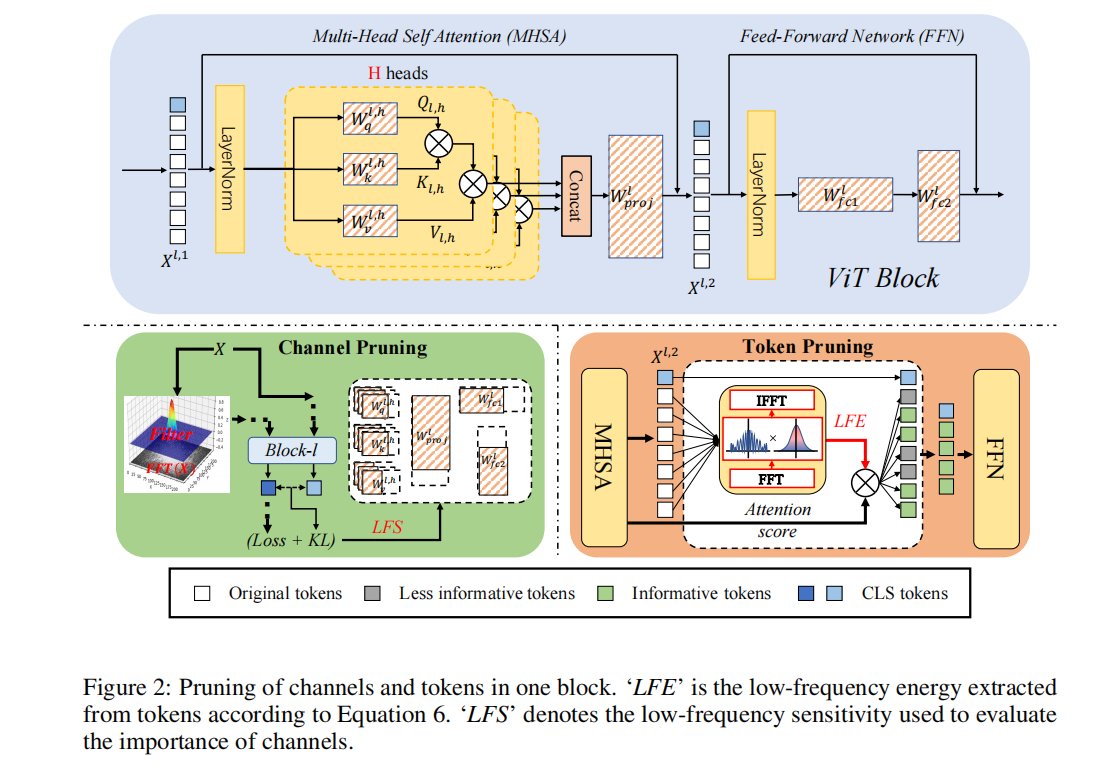
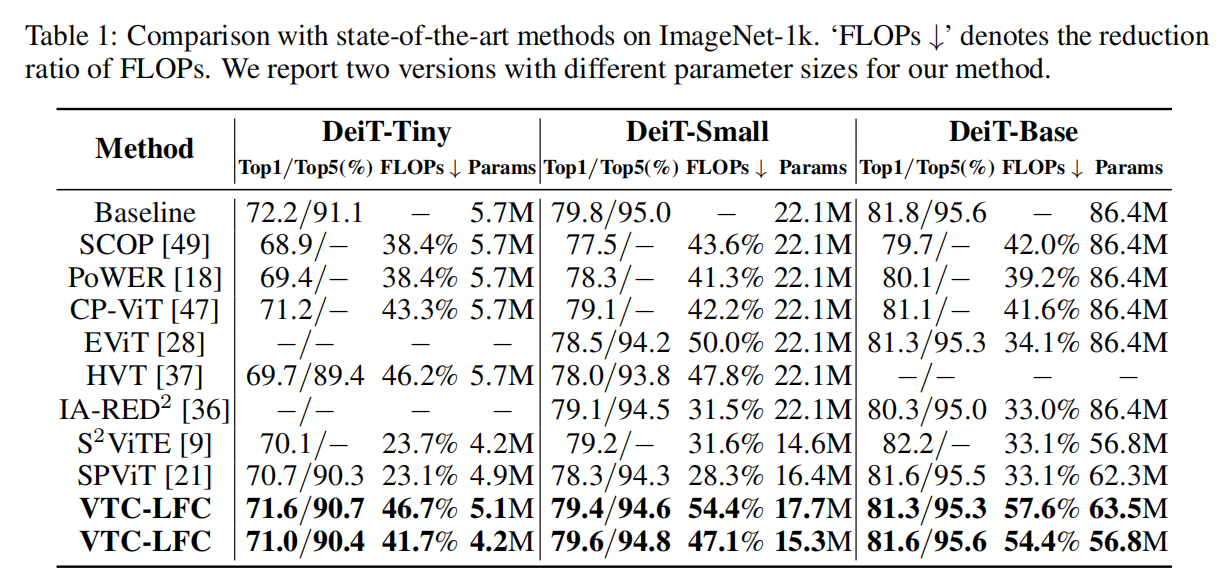
尽管视觉Transformer(ViTs)最近主导了许多视觉任务,但在资源有限的设备上部署ViT模型仍然是一个具有挑战性的问题。为了应对这样的挑战,已经提出了几种压缩ViTs的方法。其中大多数借鉴了卷积神经网络(CNN)的经验,主要集中在空间域。然而,仅在空间域中的压缩在没有微调的情况下受到了巨大的性能下降,并且对噪声不鲁棒,因为空间域中的噪声很容易混淆剪枝标准,导致一些参数/通道被错误地修剪。受最近发现自注意力是一个低通滤波器和低频信号/分量对ViTs更具信息量的启发。本文提出了用低频分量压缩ViTs。提出了两个指标,即低频灵敏度(LFS)和低频能量(LFE),以获得更好的通道剪枝和token剪枝。此外,应用自下而上的级联剪枝方案联合压缩不同维度。大量实验表明,该方法可以节省ViTs中40%~60%的FLOPs,从而显著提高ImageNet-1K上性能下降不到1%的实际设备的吞吐量。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢