
论文标题:Masked Autoencoders that Listen
论文链接:https://openreview.net/forum?id=MAMOi89bOL
代码链接:https://github.com/facebookresearch/AudioMAE
作者单位:Meta AI & CMU
本文研究了基于图像的掩码自编码器(MAE)的简单扩展,以从音频频谱图中进行自监督表示学习。遵循MAE中的Transformer编码器-解码器设计,我们的Audio-MAE首先以高掩码比对音频频谱图patch进行编码,仅通过编码器层提供非掩码token。然后解码器重新排序和解码填充掩码token的编码上下文,以便重建输入频谱图。我们发现在解码器中加入局部窗口注意力是有益的,因为音频频谱图在局部时间和频段中高度相关。然后,我们在目标数据集上以较低的掩码比微调编码器。经验上,Audio-MAE在六个音频和语音分类任务上设置了新的最先进的性能,优于使用外部监督预训练的其他最新模型。
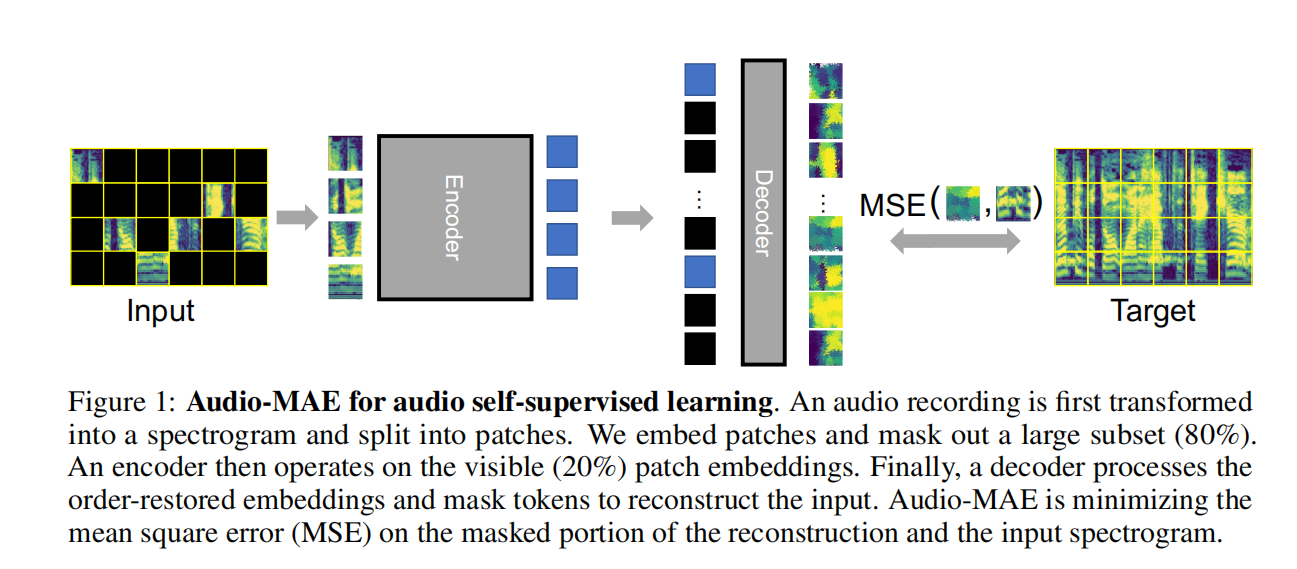
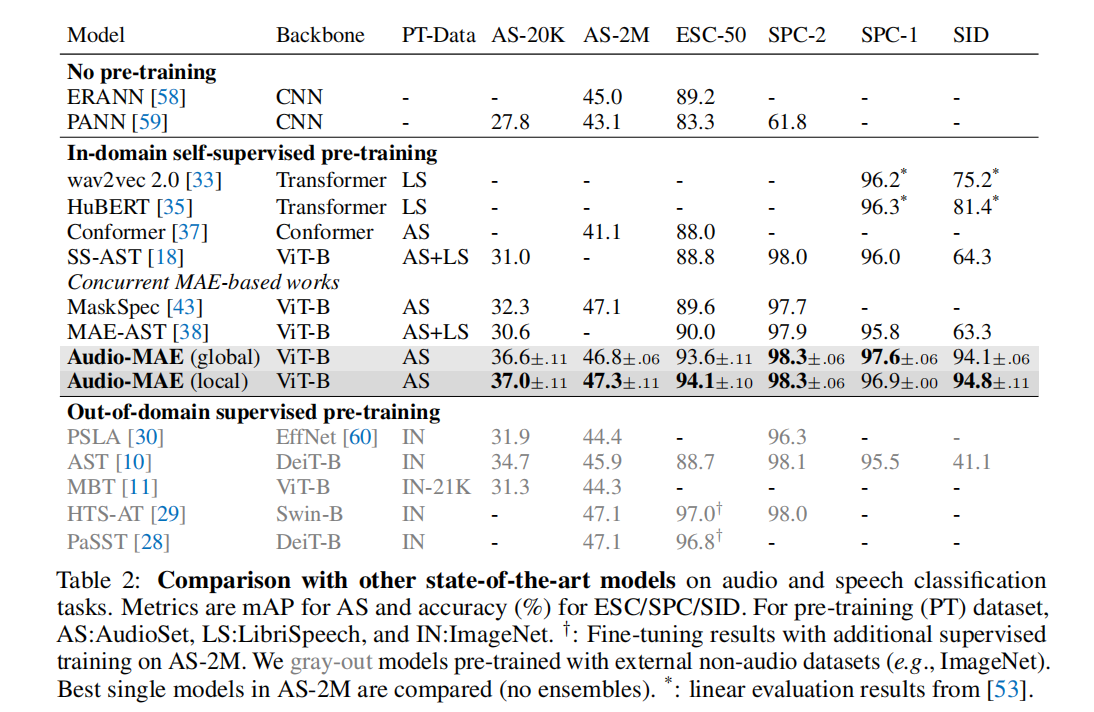
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢