
日前,NVIDIA 发布了AI Enterprise 3.0(简称NVAIE 3.0),包括了模型的训练、推理优化、部署、模型管理、云原生管理等AI应用开发上线的全流程,之前需要耗时数个月才能开发完成的AI应用,在NVAIE 3.0平台下,可以做到数小时完成。

从图里我们可以看到平台在 4 个层级的关键特性:
-
囊括了上层工作流、框架和预训练模型: 在应用场景的level上,定义清晰的输入输出,并预置预训练模型,快速完成典型应用场景的AI应用开发
-
同时支持模型开发和部署: 应用开发的工具闭环,完成机器学习模型从开发到部署的完整生命周期,包括低代码迁移学习工具TAO、主流深度学习框架TF/Pytorch、推理加速TensorRT框架、推理服务引擎等
-
云原生的架构,支持混合云部署: GPU、DPU在k8s内的集成,MLOps工具等
-
大量的基础设施优化: 包括GPU虚拟化、基于RDMA的存储访问加速、底层CUDA优化等
下面就展开前两层,看看NVAIE是如何解决AI应用开发中的痛点的。
当我们训练得到了一个不错的模型checkpoint后,需要通过TensorRT转换为可供部署的ONNX模型,这时常常遭遇算子缺失的问题。而在NVAIE 3.0平台下,你训练得到的模型则会在平台第二层中的TAO组件的能力加持下,轻松完成到ONNX模型的转换,无需再担心算子缺失、定制化开发的问题。
模型量化的痛点,可在NVAIE的第二层得到了解决——通过第二层的TAO组件可以直接得到的已经量化完成的INT8模型,无需再操心量化流程繁琐和量化精度损失的问题了。
而像一些典型的AI应用场景——比如智能客服,则在平台的最上层预置了应用开发的工作流(workflow):
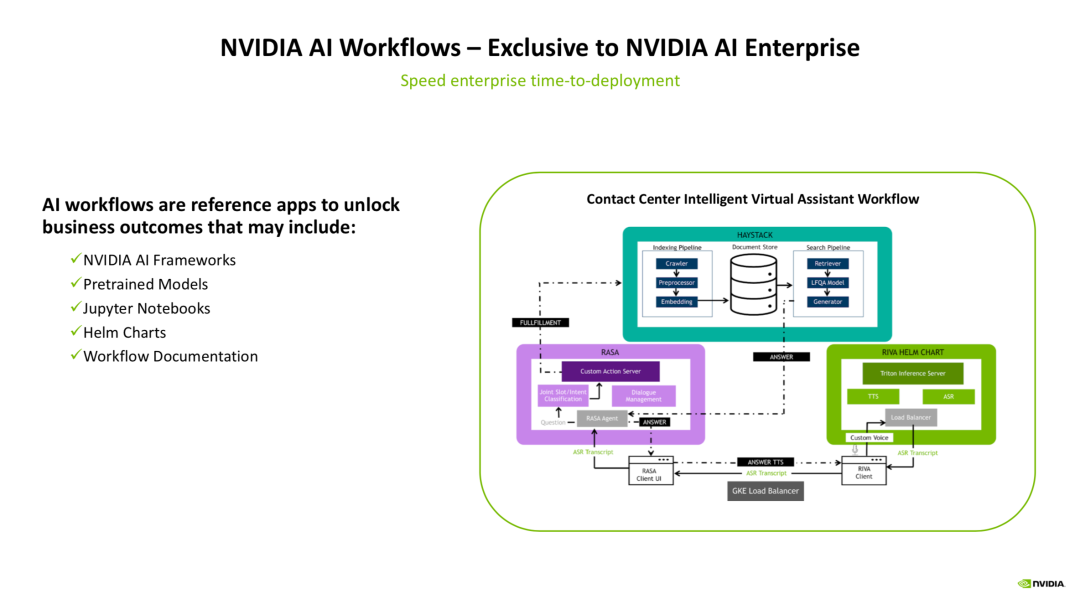
以上图中的智能虚拟助手的workflow为例,我们来看一个典型的workflow是怎么工作的。
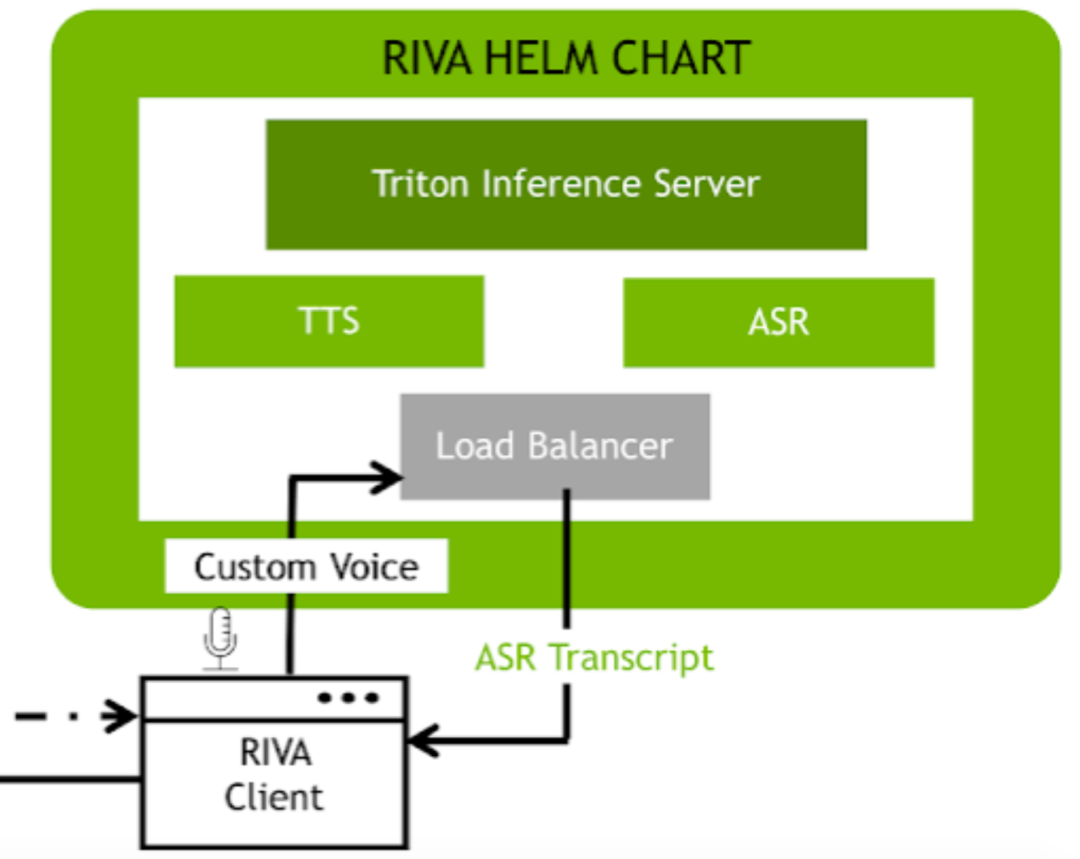
最右下角是一个基于RIVA的工作流,在这里面会完成语音转文字(ASR)、文字转语音(TTS)的操作,来作为智能虚拟助手的“输入预处理”和“输出预处理”操作。而后,经过RIVA得到的用户输入,会被输入到左边的RASA工作流。
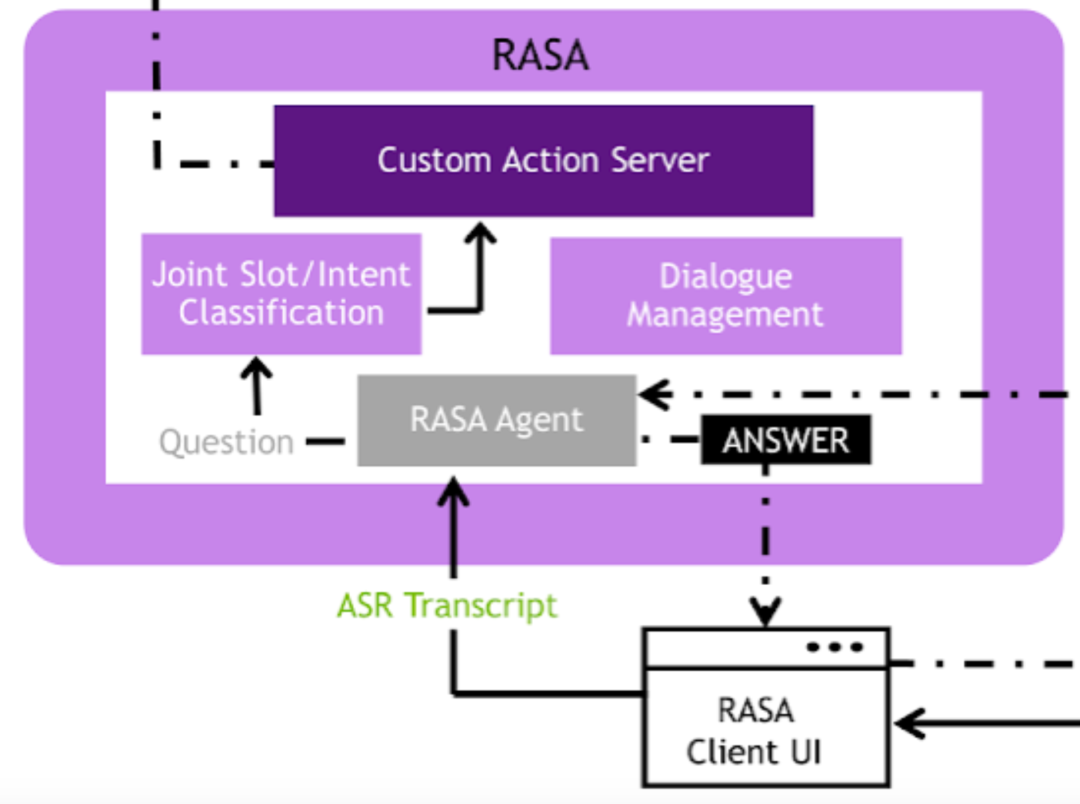
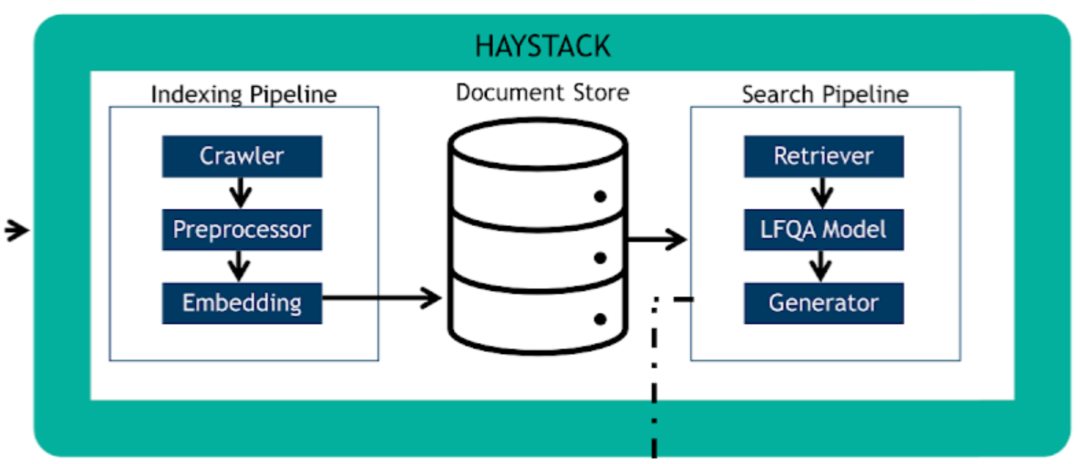
RASA是一个开源的对话机器人框架,在这里,转成文本的用户语音输入会经过基础的NLU模块,进行分词、意图理解、槽位填充等操作,来得到一个结构化的语义理解结果,该结果会被输入到内部的对话管理(DM)模块来进行对话状态的追踪和管理。得到了语义理解的结果,便会将该结果丢给图中最上面的HEYSTACK工作流,来通过答案检索的方式,得到一个适合回答用户的候选回复,该回复最终会传入回RIVA工作流,通过TTS模块生成语音回复。
NVAIE平台内置了大量的预训练模型(比如效果先进的行人检测模型PeopleNet),且这些预训练模型都是未加密、完全开放权重的,用户完全可以拿来进行AI模型的“热启动”,并且标注场景化的数据进行模型权重的微调。
预训练模型在车的识别方面,内置了诸如车辆识别、车牌识别、车型识别等多种模型,可以得到极大的提速, NGC目录查询:https://catalog.ngc.nvidia.com/
除了以上模型层面的优化外,NVAIE 3.0对AI服务的并发、可靠性、GPU利用率等进行大量的优化,实现了操作系统级别的开发套件封装。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢