
来自今天的爱可可AI前沿推介
[CV] Generalized Decoding for Pixel, Image, and Language
X Zou, Z Dou, J Yang, Z Gan, L Li, C Li, X Dai, H Behl, J Wang, L Yuan, N Peng, L Wang, Y J Lee, J Gao
[Microsoft & University of Wisconsin-Madison & UCLA]
像素、图像和语言的广义解码
要点:
-
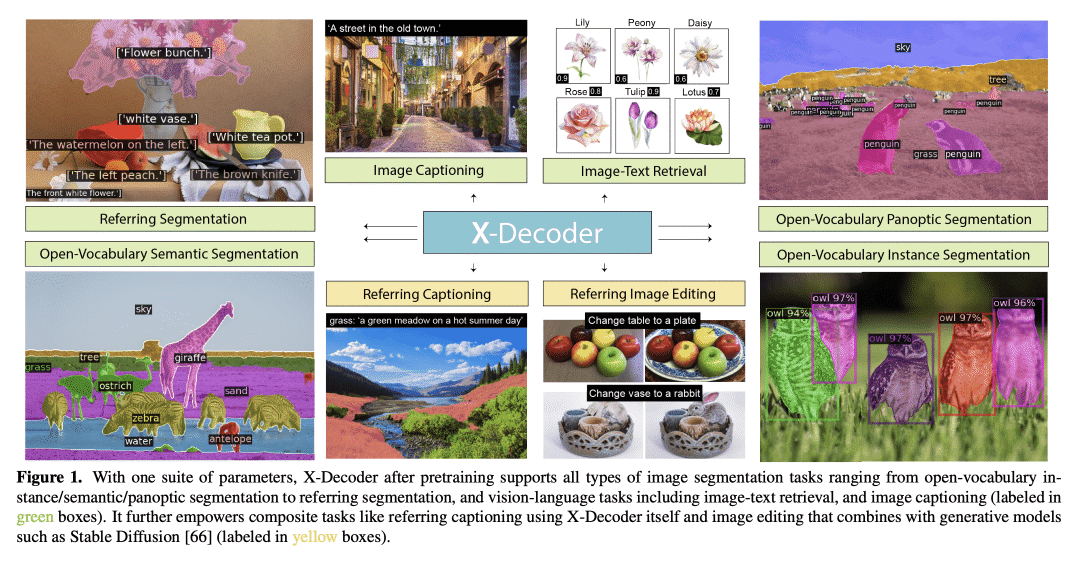
X-Decoder能无缝预测像素级分割和语言token,是第一个提供统一方式支持所有类型图像分割和各种视觉语言(VL)任务的模型; -
X-Decoder可支持零样本和微调设置下的各种下游任务; -
在八个数据集上的开放词汇分割和引用分割方面达到了新水准。
摘要:
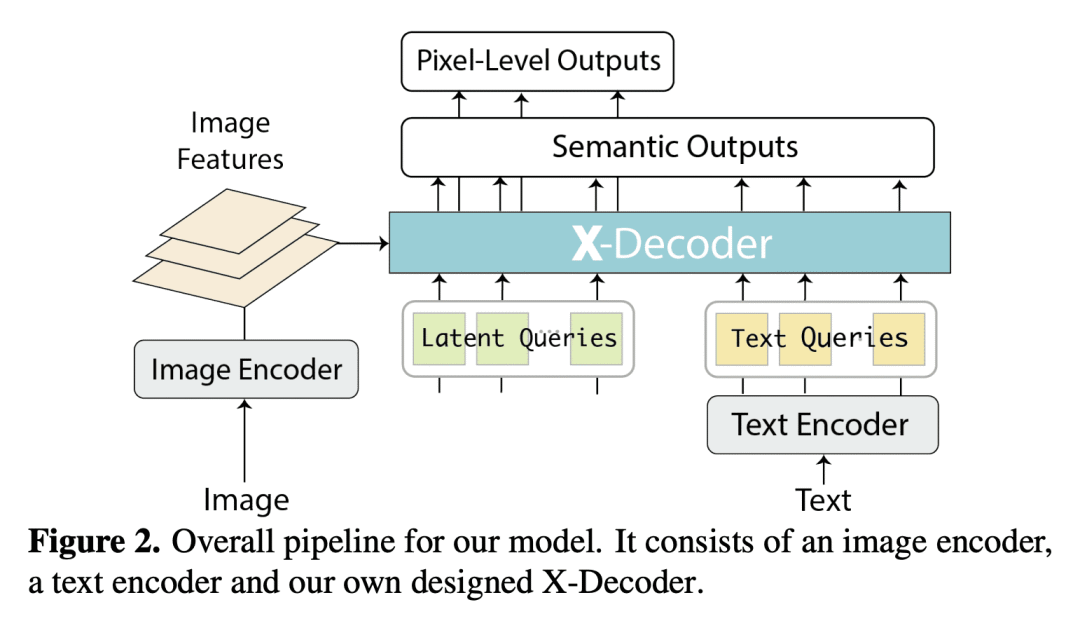
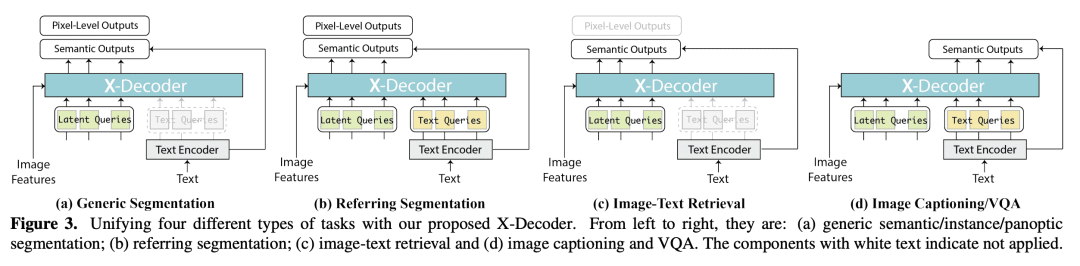
本文提出了X-Decoder,一个广义解码模型,可以无缝预测像素级分割和语言token。X-Decoder将两种类型的查询作为输入:(i )通用非语义查询和 (ii) 从文本输入归纳的语义查询,以解码同一语义空间中不同的像素级和token级输出。有了这些新设计,X-Decoder是第一个提供统一方式支持所有类型图像分割和各种视觉语言(VL)任务的模型。该设计实现了不同粒度任务之间的无缝交互,并通过学习一个共同而丰富的像素级视觉语义理解空间来带来互利,无需任何伪标签。在对有限数量的分割数据和数百万图像文本对的混合集进行预训练后,X-Decoder在零样本和微调设置下都表现出对各种下游任务的强大可迁移性。值得注意的是,它实现了 (1) 在八个数据集的开放词汇分割和引用分割方面的最新结果;(2) 在分割和VL任务上对其他通用和专家模型进行更好或更具竞争力的微调性能;以及(3) 高效微调和新任务组合的灵活性(例如,引用描述和图像编辑)。
We present X-Decoder, a generalized decoding model that can predict pixel-level segmentation and language tokens seamlessly. X-Decodert takes as input two types of queries: (i) generic non-semantic queries and (ii) semantic queries induced from text inputs, to decode different pixel-level and token-level outputs in the same semantic space. With such a novel design, X-Decoder is the first work that provides a unified way to support all types of image segmentation and a variety of vision-language (VL) tasks. Further, our design enables seamless interactions across tasks at different granularities and brings mutual benefits by learning a common and rich pixel-level visual-semantic understanding space, without any pseudo-labeling. After pretraining on a mixed set of a limited amount of segmentation data and millions of image-text pairs, X-Decoder exhibits strong transferability to a wide range of downstream tasks in both zero-shot and finetuning settings. Notably, it achieves (1) state-of-the-art results on open-vocabulary segmentation and referring segmentation on eight datasets; (2) better or competitive finetuned performance to other generalist and specialist models on segmentation and VL tasks; and (3) flexibility for efficient finetuning and novel task composition (e.g., referring captioning and image editing). Code, demo, video, and visualization are available at this https URL.
论文链接:https://arxiv.org/abs/2212.11270
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢