
来自今天的爱可可AI前沿推介
[CV] SAVi++: Towards End-to-End Object-Centric Learning from Real-World Videos
G F. Elsayed, A Mahendran, S v Steenkiste, K Greff, M C. Mozer, T Kipf
[Google Research]
SAVi++: 现实世界视频端到端目标中心学习
要点:
-
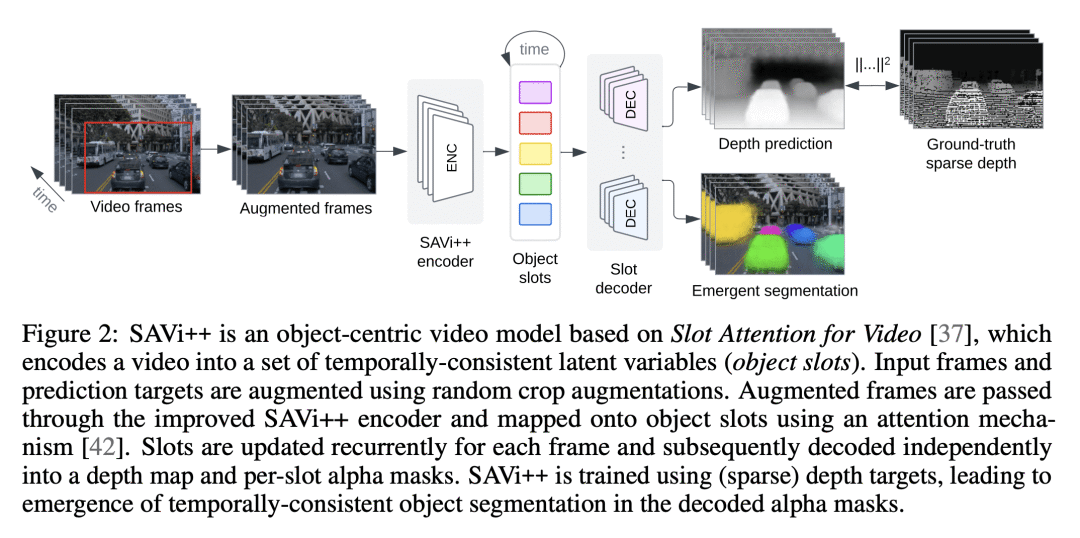
提出SAVi++,一种基于目标中心槽的视频模型,利用深度预测并在架构设计和数据增强方面采用模型扩展的最佳实践; -
SAVi++能处理具有复杂形状和背景以及每场景包含大量目标的视频; -
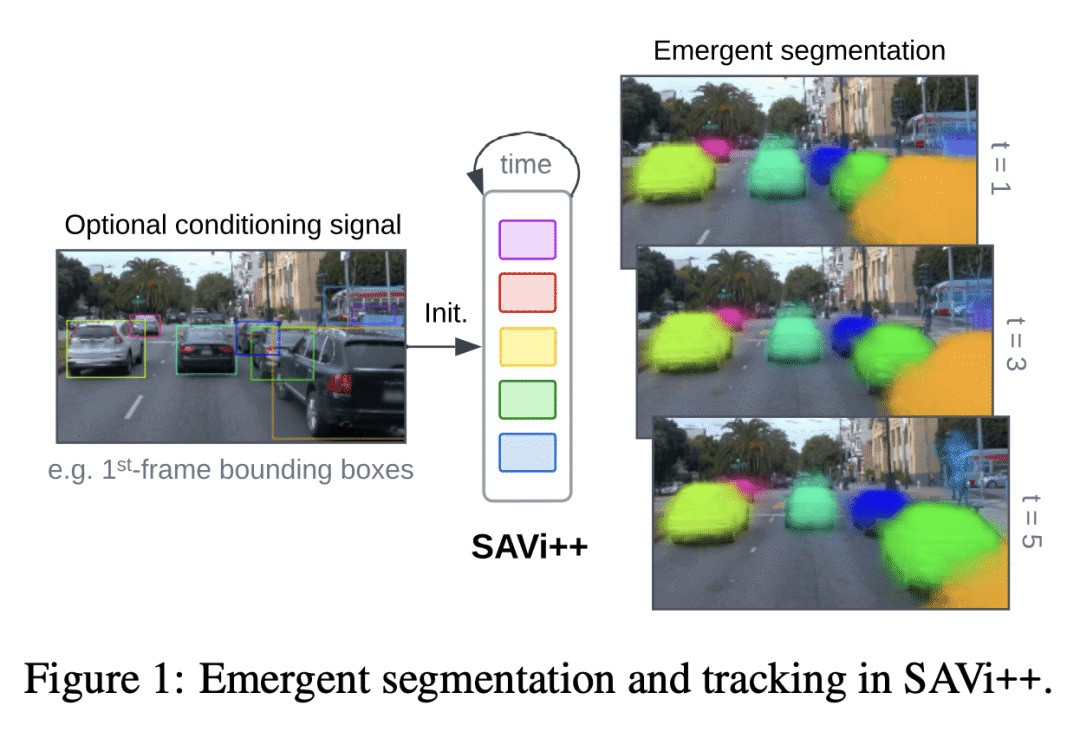
通过从激光雷达获取的稀疏深度信号训练,SAVi++可在Waymo Open数据集中的真实世界驾驶视频中实现自发目标分解和跟踪。
摘要:
视觉世界可以用具有稀疏相互作用的单独实体来简约地描述。事实证明,除非提供明确的实例级监督,否则在动态视觉场景中发现这种构图结构对端到端计算机视觉方法具有挑战性。利用运动线索的基于槽的模型最近在学习在没有直接监督情况下表示、分割和跟踪目标方面很有希望,但它们仍然无法扩展到复杂的现实世界多对目标视频。为了弥合这一差距,本文从人类发展中汲取灵感,并假设深度信号形式的场景几何信息可以促进以目标为中心的学习。提出SAbi++,一个以目标为中心的视频模型,经过训练,可以预测基于槽的视频表示的深度信号。通过进一步利用模型扩展的最佳实践,可训练SAVI++来分割用移动相机录制的复杂动态场景,其中包含自然背景上不同外观的静态和移动对象,而无需分割监督。本文证明,用从激光雷达获得的稀疏深度信号,SAVi++能从现实世界Waymo Open数据集中的视频中学习自发目标分割和跟踪。
The visual world can be parsimoniously characterized in terms of distinct entities with sparse interactions. Discovering this compositional structure in dynamic visual scenes has proven challenging for end-to-end computer vision approaches unless explicit instance-level supervision is provided. Slot-based models leveraging motion cues have recently shown great promise in learning to represent, segment, and track objects without direct supervision, but they still fail to scale to complex real-world multi-object videos. In an effort to bridge this gap, we take inspiration from human development and hypothesize that information about scene geometry in the form of depth signals can facilitate object-centric learning. We introduce SAVi++, an object-centric video model which is trained to predict depth signals from a slot-based video representation. By further leveraging best practices for model scaling, we are able to train SAVi++ to segment complex dynamic scenes recorded with moving cameras, containing both static and moving objects of diverse appearance on naturalistic backgrounds, without the need for segmentation supervision. Finally, we demonstrate that by using sparse depth signals obtained from LiDAR, SAVi++ is able to learn emergent object segmentation and tracking from videos in the real-world Waymo Open dataset.
论文链接:https://arxiv.org/abs/2206.07764

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢